 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-level Alignment Training Scheme for Video-and-Language Grounding
Apr 26, 2022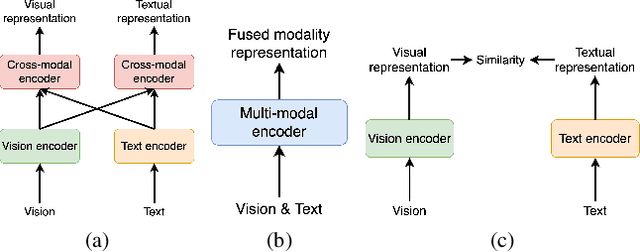
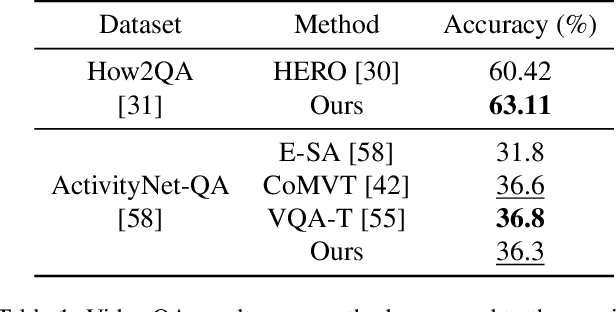

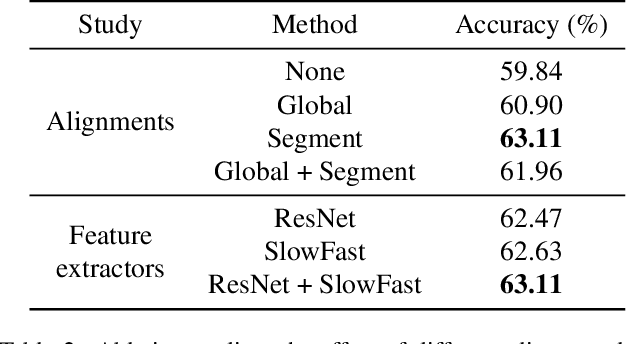
To solve video-and-language grounding tasks, the key is for the network to understand the connection between the two modalities. For a pair of video and language description, their semantic relation is reflected by their encodings' similarity. A good multi-modality encoder should be able to well capture both inputs' semantics and encode them in the shared feature space where embedding distance gets properly translated into their semantic similarity. In this work, we focused on this semantic connection between video and language, and developed a multi-level alignment training scheme to directly shape the encoding process. Global and segment levels of video-language alignment pairs were designed, based on the information similarity ranging from high-level context to fine-grained semantics. The contrastive loss was used to contrast the encodings' similarities between the positive and negative alignment pairs, and to ensure the network is trained in such a way that similar information is encoded closely in the shared feature space while information of different semantics is kept apart. Our multi-level alignment training can be applied to various video-and-language grounding tasks. Together with the task-specific training loss, our framework achieved comparable performance to previous state-of-the-arts on multiple video QA and retrieval datasets.
Learning Two-Step Hybrid Policy for Graph-Based Interpretable Reinforcement Learning
Jan 21, 2022
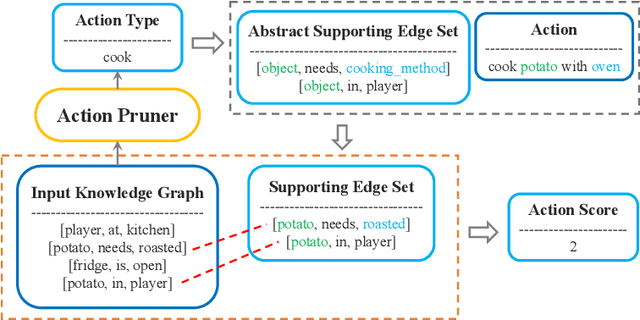
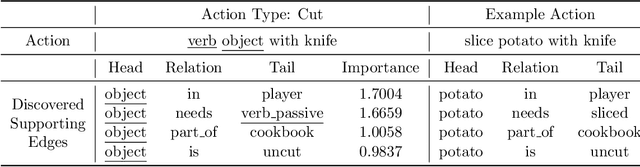
We present a two-step hybrid reinforcement learning (RL) policy that is designed to generate interpretable and robust hierarchical policies on the RL problem with graph-based input. Unlike prior deep reinforcement learning policies parameterized by an end-to-end black-box graph neural network, our approach disentangles the decision-making process into two steps. The first step is a simplified classification problem that maps the graph input to an action group where all actions share a similar semantic meaning. The second step implements a sophisticated rule-miner that conducts explicit one-hop reasoning over the graph and identifies decisive edges in the graph input without the necessity of heavy domain knowledge. This two-step hybrid policy presents human-friendly interpretations and achieves better performance in terms of generalization and robustness. Extensive experimental studies on four levels of complex text-based games have demonstrated the superiority of the proposed method compared to the state-of-the-art.
Interactive Teaching for Conversational AI
Dec 02, 2020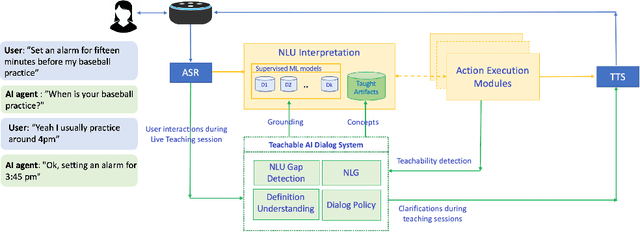
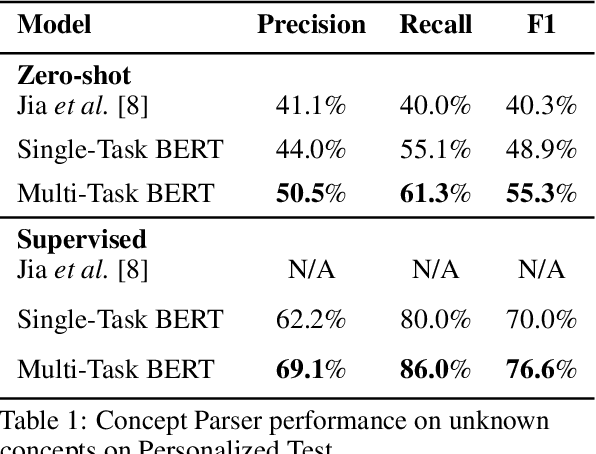
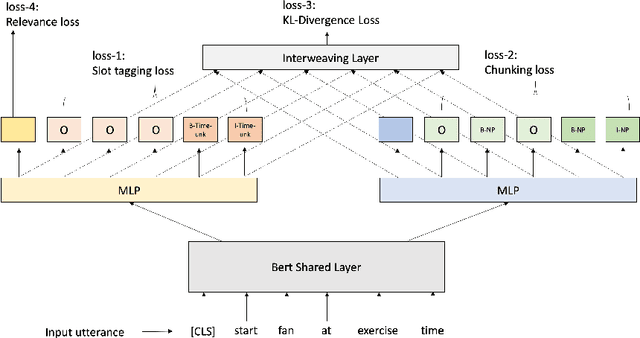
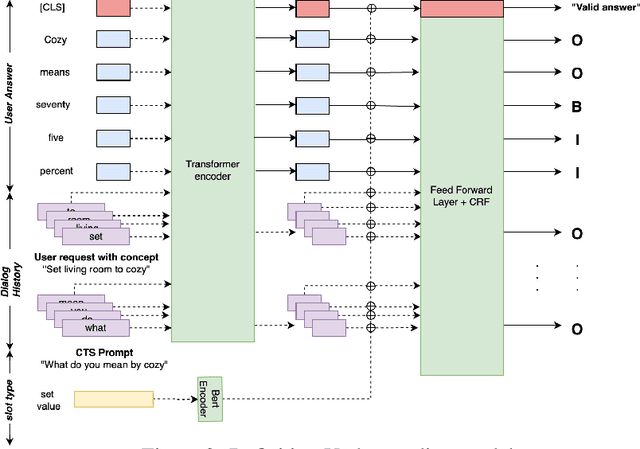
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.
LRTA: A Transparent Neural-Symbolic Reasoning Framework with Modular Supervision for Visual Question Answering
Nov 21, 2020
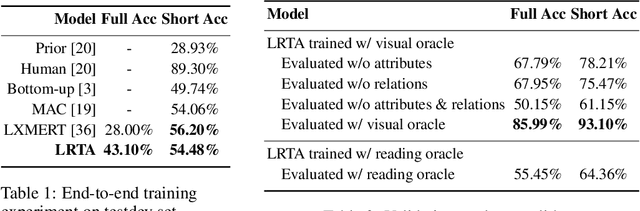
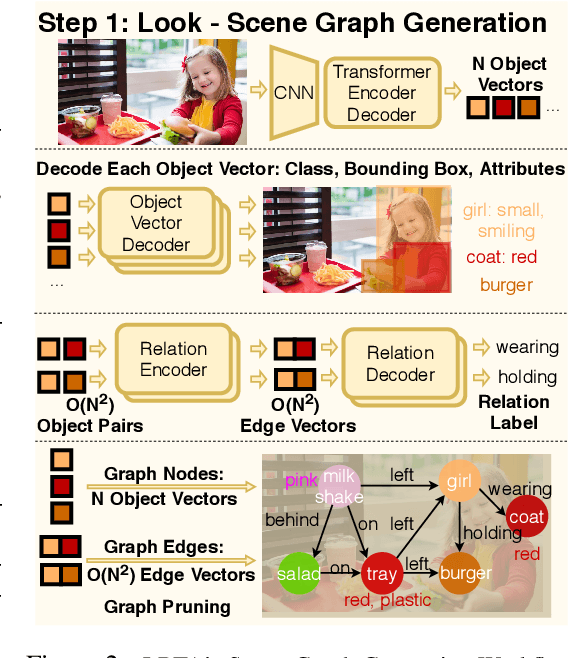
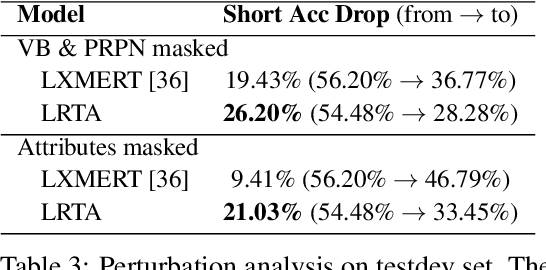
The predominant approach to visual question answering (VQA) relies on encoding the image and question with a "black-box" neural encoder and decoding a single token as the answer like "yes" or "no". Despite this approach's strong quantitative results, it struggles to come up with intuitive, human-readable forms of justification for the prediction process. To address this insufficiency, we reformulate VQA as a full answer generation task, which requires the model to justify its predictions in natural language. We propose LRTA [Look, Read, Think, Answer], a transparent neural-symbolic reasoning framework for visual question answering that solves the problem step-by-step like humans and provides human-readable form of justification at each step. Specifically, LRTA learns to first convert an image into a scene graph and parse a question into multiple reasoning instructions. It then executes the reasoning instructions one at a time by traversing the scene graph using a recurrent neural-symbolic execution module. Finally, it generates a full answer to the given question with natural language justifications. Our experiments on GQA dataset show that LRTA outperforms the state-of-the-art model by a large margin (43.1% v.s. 28.0%) on the full answer generation task. We also create a perturbed GQA test set by removing linguistic cues (attributes and relations) in the questions for analyzing whether a model is having a smart guess with superficial data correlations. We show that LRTA makes a step towards truly understanding the question while the state-of-the-art model tends to learn superficial correlations from the training data.