 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHephaestus: Improving Fundamental Agent Capabilities of Large Language Models through Continual Pre-Training
Feb 10, 2025



Due to the scarcity of agent-oriented pre-training data, LLM-based autonomous agents typically rely on complex prompting or extensive fine-tuning, which often fails to introduce new capabilities while preserving strong generalizability. We introduce Hephaestus-Forge, the first large-scale pre-training corpus designed to enhance the fundamental capabilities of LLM agents in API function calling, intrinsic reasoning and planning, and adapting to environmental feedback. Hephaestus-Forge comprises 103B agent-specific data encompassing 76,537 APIs, including both tool documentation to introduce knowledge of API functions and function calling trajectories to strengthen intrinsic reasoning. To explore effective training protocols, we investigate scaling laws to identify the optimal recipe in data mixing ratios. By continual pre-training on Hephaestus-Forge, Hephaestus outperforms small- to medium-scale open-source LLMs and rivals commercial LLMs on three agent benchmarks, demonstrating the effectiveness of our pre-training corpus in enhancing fundamental agentic capabilities and generalization of LLMs to new tasks or environments.
Graph-Aware Language Model Pre-Training on a Large Graph Corpus Can Help Multiple Graph Applications
Jun 05, 2023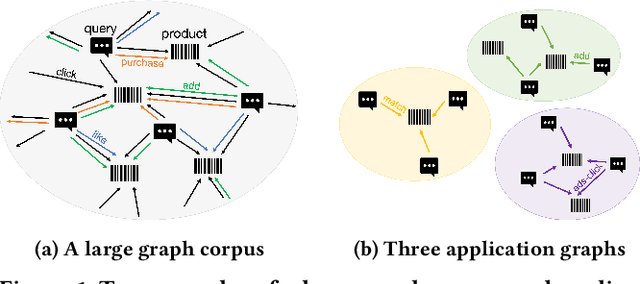
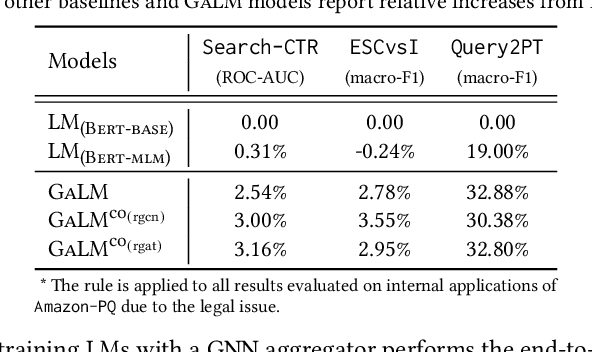
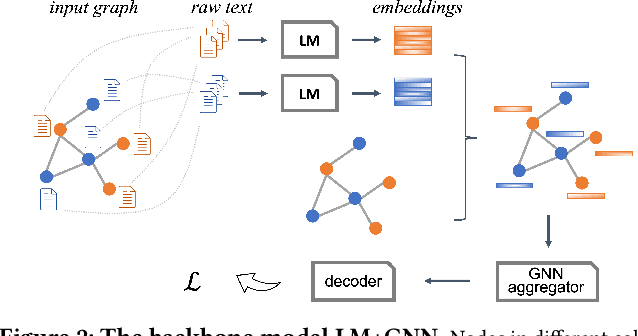
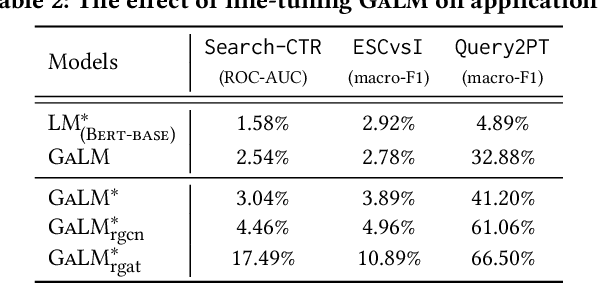
Model pre-training on large text corpora has been demonstrated effective for various downstream applications in the NLP domain. In the graph mining domain, a similar analogy can be drawn for pre-training graph models on large graphs in the hope of benefiting downstream graph applications, which has also been explored by several recent studies. However, no existing study has ever investigated the pre-training of text plus graph models on large heterogeneous graphs with abundant textual information (a.k.a. large graph corpora) and then fine-tuning the model on different related downstream applications with different graph schemas. To address this problem, we propose a framework of graph-aware language model pre-training (GALM) on a large graph corpus, which incorporates large language models and graph neural networks, and a variety of fine-tuning methods on downstream applications. We conduct extensive experiments on Amazon's real internal datasets and large public datasets. Comprehensive empirical results and in-depth analysis demonstrate the effectiveness of our proposed methods along with lessons learned.
Understanding and Constructing Latent Modality Structures in Multi-modal Representation Learning
Mar 10, 2023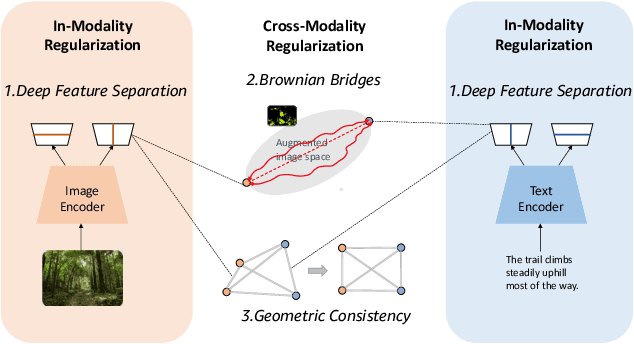
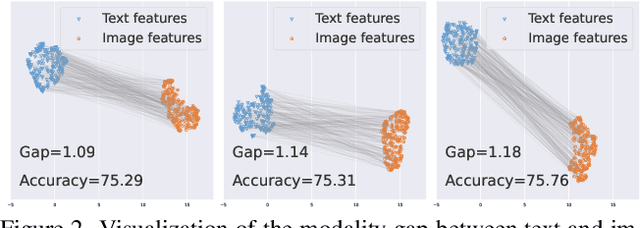
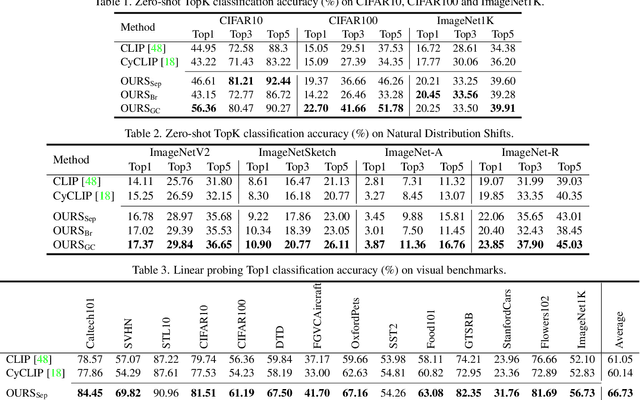
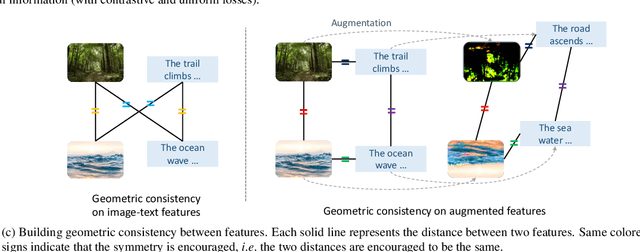
Contrastive loss has been increasingly used in learning representations from multiple modalities. In the limit, the nature of the contrastive loss encourages modalities to exactly match each other in the latent space. Yet it remains an open question how the modality alignment affects the downstream task performance. In this paper, based on an information-theoretic argument, we first prove that exact modality alignment is sub-optimal in general for downstream prediction tasks. Hence we advocate that the key of better performance lies in meaningful latent modality structures instead of perfect modality alignment. To this end, we propose three general approaches to construct latent modality structures. Specifically, we design 1) a deep feature separation loss for intra-modality regularization; 2) a Brownian-bridge loss for inter-modality regularization; and 3) a geometric consistency loss for both intra- and inter-modality regularization. Extensive experiments are conducted on two popular multi-modal representation learning frameworks: the CLIP-based two-tower model and the ALBEF-based fusion model. We test our model on a variety of tasks including zero/few-shot image classification, image-text retrieval, visual question answering, visual reasoning, and visual entailment. Our method achieves consistent improvements over existing methods, demonstrating the effectiveness and generalizability of our proposed approach on latent modality structure regularization.
A Multi-level Alignment Training Scheme for Video-and-Language Grounding
Apr 26, 2022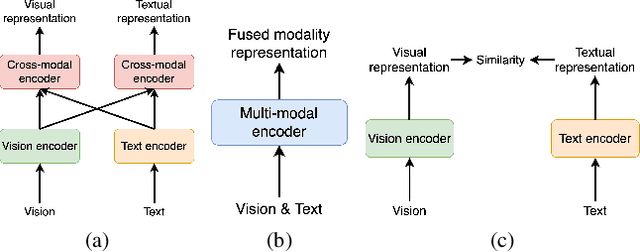
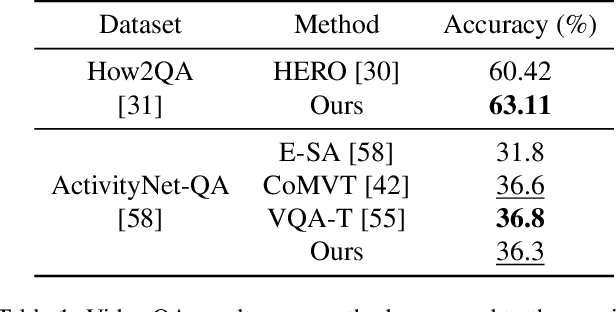

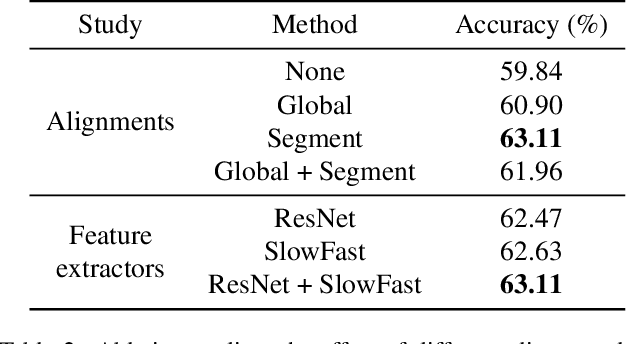
To solve video-and-language grounding tasks, the key is for the network to understand the connection between the two modalities. For a pair of video and language description, their semantic relation is reflected by their encodings' similarity. A good multi-modality encoder should be able to well capture both inputs' semantics and encode them in the shared feature space where embedding distance gets properly translated into their semantic similarity. In this work, we focused on this semantic connection between video and language, and developed a multi-level alignment training scheme to directly shape the encoding process. Global and segment levels of video-language alignment pairs were designed, based on the information similarity ranging from high-level context to fine-grained semantics. The contrastive loss was used to contrast the encodings' similarities between the positive and negative alignment pairs, and to ensure the network is trained in such a way that similar information is encoded closely in the shared feature space while information of different semantics is kept apart. Our multi-level alignment training can be applied to various video-and-language grounding tasks. Together with the task-specific training loss, our framework achieved comparable performance to previous state-of-the-arts on multiple video QA and retrieval datasets.
Privacy Preserving Visual Question Answering
Feb 15, 2022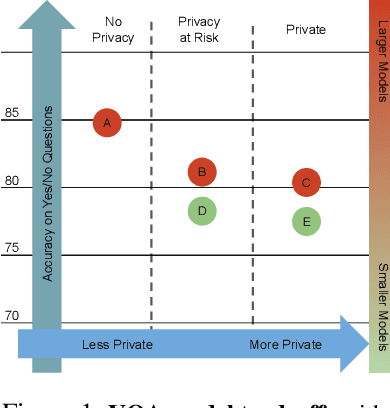

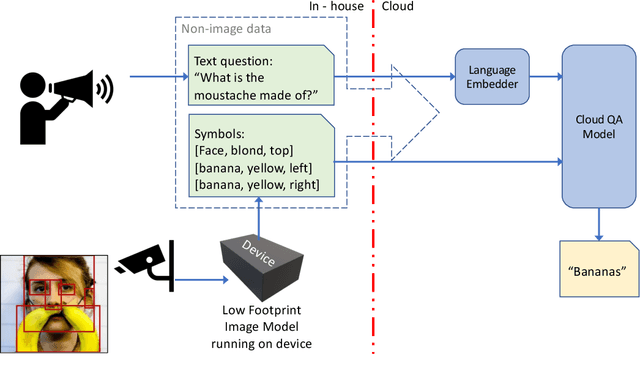

We introduce a novel privacy-preserving methodology for performing Visual Question Answering on the edge. Our method constructs a symbolic representation of the visual scene, using a low-complexity computer vision model that jointly predicts classes, attributes and predicates. This symbolic representation is non-differentiable, which means it cannot be used to recover the original image, thereby keeping the original image private. Our proposed hybrid solution uses a vision model which is more than 25 times smaller than the current state-of-the-art (SOTA) vision models, and 100 times smaller than end-to-end SOTA VQA models. We report detailed error analysis and discuss the trade-offs of using a distilled vision model and a symbolic representation of the visual scene.
A Thousand Words Are Worth More Than a Picture: Natural Language-Centric Outside-Knowledge Visual Question Answering
Jan 14, 2022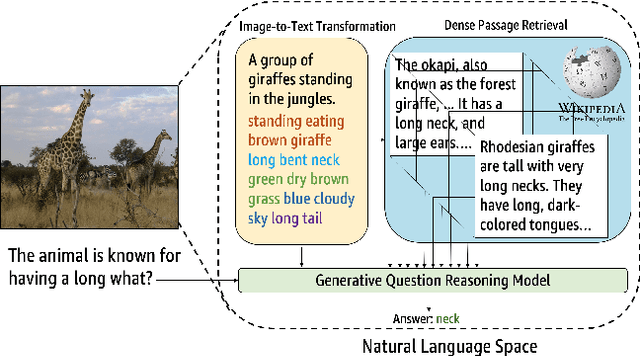
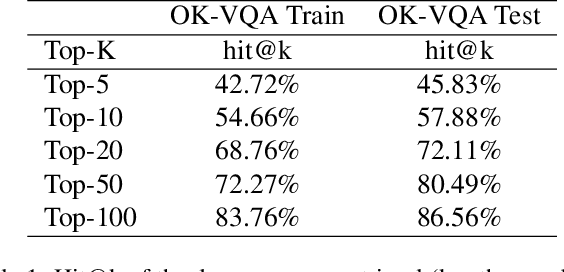

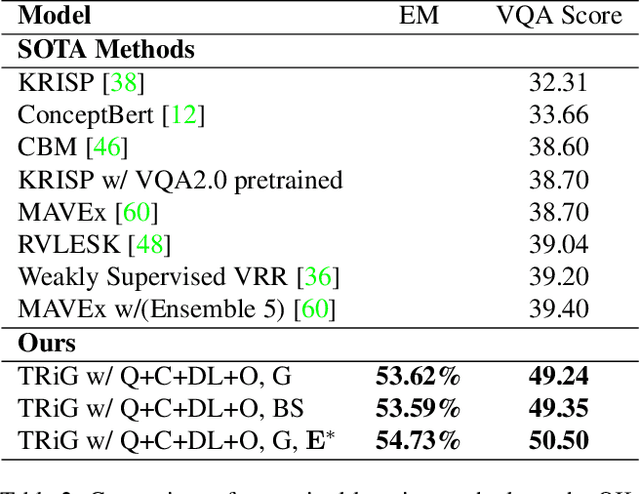
Outside-knowledge visual question answering (OK-VQA) requires the agent to comprehend the image, make use of relevant knowledge from the entire web, and digest all the information to answer the question. Most previous works address the problem by first fusing the image and question in the multi-modal space, which is inflexible for further fusion with a vast amount of external knowledge. In this paper, we call for a paradigm shift for the OK-VQA task, which transforms the image into plain text, so that we can enable knowledge passage retrieval, and generative question-answering in the natural language space. This paradigm takes advantage of the sheer volume of gigantic knowledge bases and the richness of pre-trained language models. A Transform-Retrieve-Generate framework (TRiG) framework is proposed, which can be plug-and-played with alternative image-to-text models and textual knowledge bases. Experimental results show that our TRiG framework outperforms all state-of-the-art supervised methods by at least 11.1% absolute margin.
Learning Better Visual Dialog Agents with Pretrained Visual-Linguistic Representation
May 24, 2021

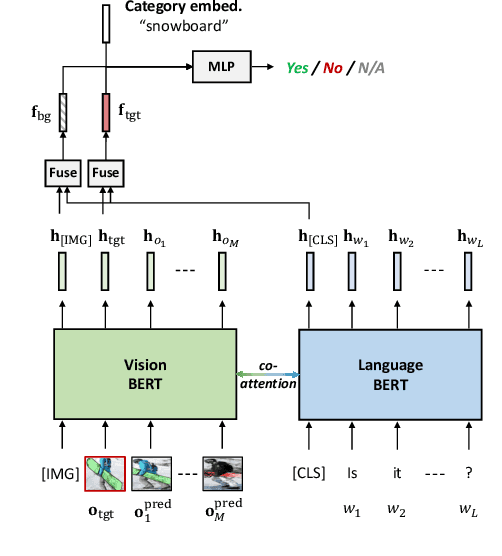
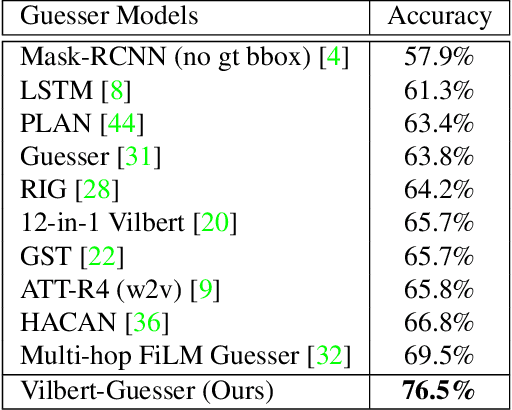
GuessWhat?! is a two-player visual dialog guessing game where player A asks a sequence of yes/no questions (Questioner) and makes a final guess (Guesser) about a target object in an image, based on answers from player B (Oracle). Based on this dialog history between the Questioner and the Oracle, a Guesser makes a final guess of the target object. Previous baseline Oracle model encodes no visual information in the model, and it cannot fully understand complex questions about color, shape, relationships and so on. Most existing work for Guesser encode the dialog history as a whole and train the Guesser models from scratch on the GuessWhat?! dataset. This is problematic since language encoder tend to forget long-term history and the GuessWhat?! data is sparse in terms of learning visual grounding of objects. Previous work for Questioner introduces state tracking mechanism into the model, but it is learned as a soft intermediates without any prior vision-linguistic insights. To bridge these gaps, in this paper we propose Vilbert-based Oracle, Guesser and Questioner, which are all built on top of pretrained vision-linguistic model, Vilbert. We introduce two-way background/target fusion mechanism into Vilbert-Oracle to account for both intra and inter-object questions. We propose a unified framework for Vilbert-Guesser and Vilbert-Questioner, where state-estimator is introduced to best utilize Vilbert's power on single-turn referring expression comprehension. Experimental results show that our proposed models outperform state-of-the-art models significantly by 7%, 10%, 12% for Oracle, Guesser and End-to-End Questioner respectively.
Interactive Teaching for Conversational AI
Dec 02, 2020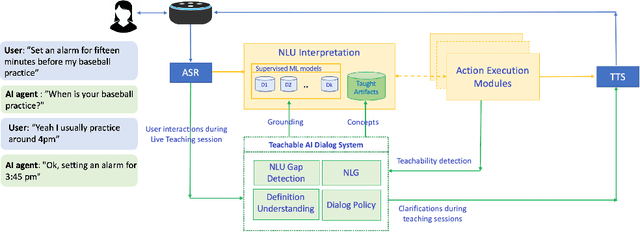
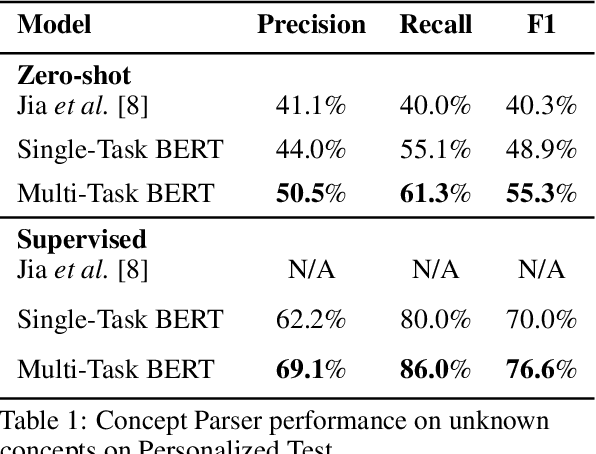
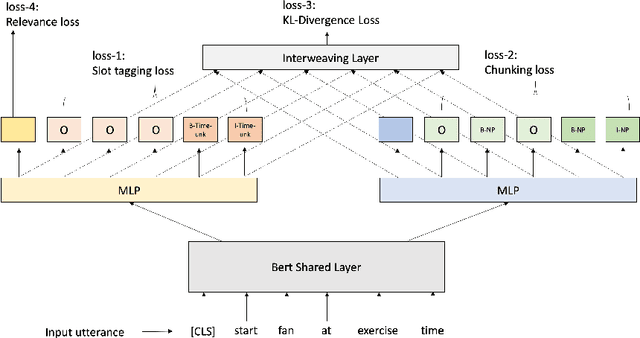
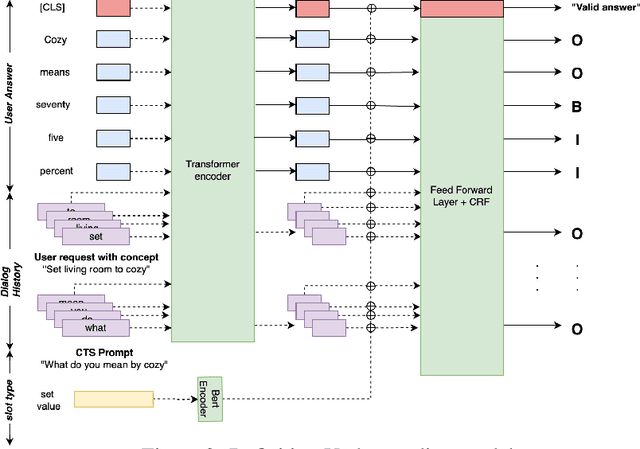
Current conversational AI systems aim to understand a set of pre-designed requests and execute related actions, which limits them to evolve naturally and adapt based on human interactions. Motivated by how children learn their first language interacting with adults, this paper describes a new Teachable AI system that is capable of learning new language nuggets called concepts, directly from end users using live interactive teaching sessions. The proposed setup uses three models to: a) Identify gaps in understanding automatically during live conversational interactions, b) Learn the respective interpretations of such unknown concepts from live interactions with users, and c) Manage a classroom sub-dialogue specifically tailored for interactive teaching sessions. We propose state-of-the-art transformer based neural architectures of models, fine-tuned on top of pre-trained models, and show accuracy improvements on the respective components. We demonstrate that this method is very promising in leading way to build more adaptive and personalized language understanding models.
Adversarial Code Learning for Image Generation
Jan 30, 2020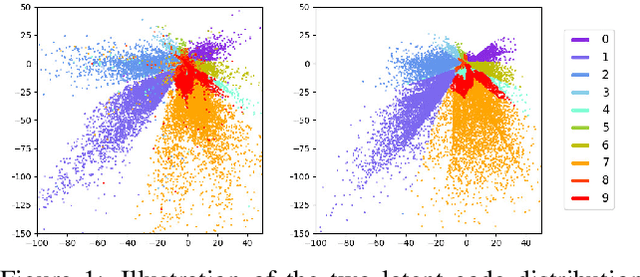
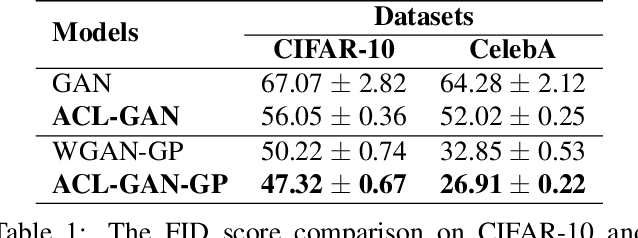
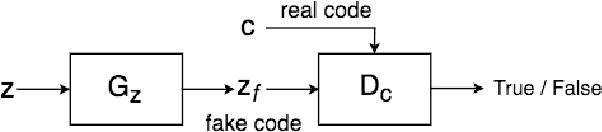

We introduce the "adversarial code learning" (ACL) module that improves overall image generation performance to several types of deep models. Instead of performing a posterior distribution modeling in the pixel spaces of generators, ACLs aim to jointly learn a latent code with another image encoder/inference net, with a prior noise as its input. We conduct the learning in an adversarial learning process, which bears a close resemblance to the original GAN but again shifts the learning from image spaces to prior and latent code spaces. ACL is a portable module that brings up much more flexibility and possibilities in generative model designs. First, it allows flexibility to convert non-generative models like Autoencoders and standard classification models to decent generative models. Second, it enhances existing GANs' performance by generating meaningful codes and images from any part of the prior. We have incorporated our ACL module with the aforementioned frameworks and have performed experiments on synthetic, MNIST, CIFAR-10, and CelebA datasets. Our models have achieved significant improvements which demonstrated the generality for image generation tasks.
Convolutional Quantum-Like Language Model with Mutual-Attention for Product Rating Prediction
Dec 25, 2019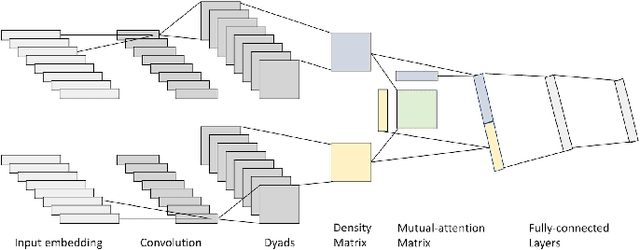
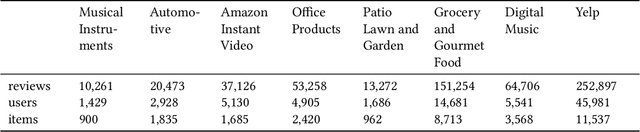
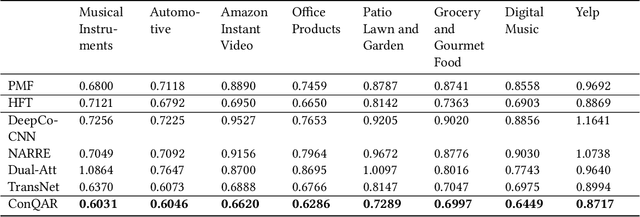
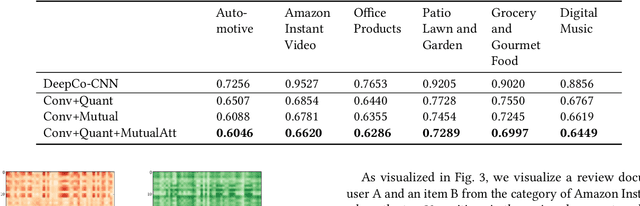
Recommender systems are designed to help mitigate information overload users experience during online shopping. Recent work explores neural language models to learn user and item representations from user reviews and combines such representations with rating information. Most existing convolutional-based neural models take pooling immediately after convolution and loses the interaction information between the latent dimension of convolutional feature vectors along the way. Moreover, these models usually take all feature vectors at higher levels as equal and do not take into consideration that some features are more relevant to this specific user-item context. To bridge these gaps, this paper proposes a convolutional quantum-like language model with mutual-attention for rating prediction (ConQAR). By introducing a quantum-like density matrix layer, interactions between latent dimensions of convolutional feature vectors are well captured. With the attention weights learned from the mutual-attention layer, final representations of a user and an item absorb information from both itself and its counterparts for making rating prediction. Experiments on two large datasets show that our model outperforms multiple state-of-the-art CNN-based models. We also perform an ablation test to analyze the independent effects of the two components of our model. Moreover, we conduct a case study and present visualizations of the quantum probabilistic distributions in one user and one item review document to show that the learned distributions capture meaningful information about this user and item, and can be potentially used as textual profiling of the user and item.