 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeITEm: Unsupervised Image-Text Embedding Learning for eCommerce
Oct 22, 2023



Product embedding serves as a cornerstone for a wide range of applications in eCommerce. The product embedding learned from multiple modalities shows significant improvement over that from a single modality, since different modalities provide complementary information. However, some modalities are more informatively dominant than others. How to teach a model to learn embedding from different modalities without neglecting information from the less dominant modality is challenging. We present an image-text embedding model (ITEm), an unsupervised learning method that is designed to better attend to image and text modalities. We extend BERT by (1) learning an embedding from text and image without knowing the regions of interest; (2) training a global representation to predict masked words and to construct masked image patches without their individual representations. We evaluate the pre-trained ITEm on two tasks: the search for extremely similar products and the prediction of product categories, showing substantial gains compared to strong baseline models.
eProduct: A Million-Scale Visual Search Benchmark to Address Product Recognition Challenges
Jul 13, 2021
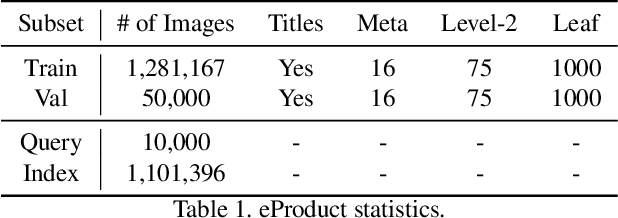
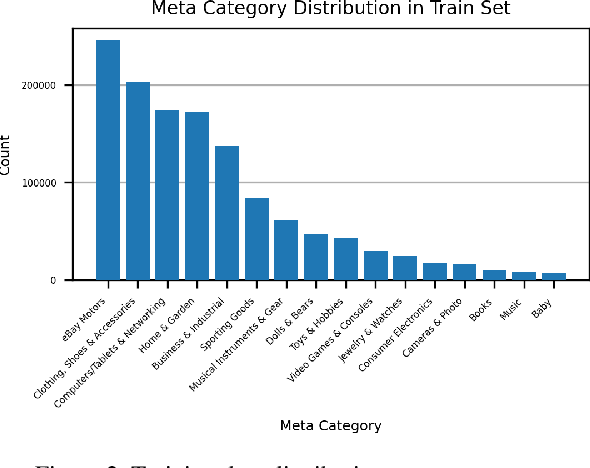
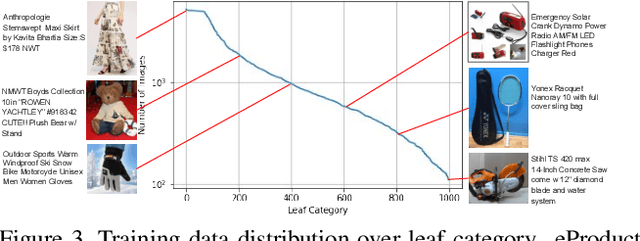
Large-scale product recognition is one of the major applications of computer vision and machine learning in the e-commerce domain. Since the number of products is typically much larger than the number of categories of products, image-based product recognition is often cast as a visual search rather than a classification problem. It is also one of the instances of super fine-grained recognition, where there are many products with slight or subtle visual differences. It has always been a challenge to create a benchmark dataset for training and evaluation on various visual search solutions in a real-world setting. This motivated creation of eProduct, a dataset consisting of 2.5 million product images towards accelerating development in the areas of self-supervised learning, weakly-supervised learning, and multimodal learning, for fine-grained recognition. We present eProduct as a training set and an evaluation set, where the training set contains 1.3M+ listing images with titles and hierarchical category labels, for model development, and the evaluation set includes 10,000 query and 1.1 million index images for visual search evaluation. We will present eProduct's construction steps, provide analysis about its diversity and cover the performance of baseline models trained on it.
Instance-level Image Retrieval using Reranking Transformers
Mar 22, 2021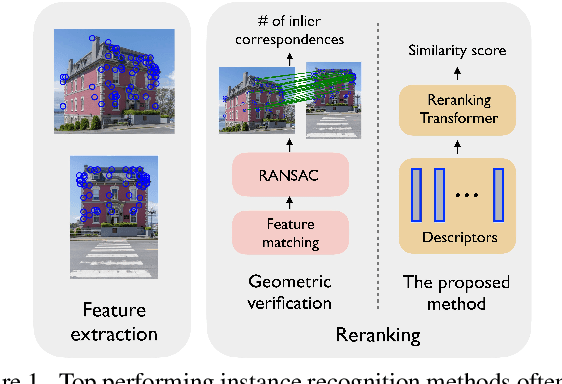
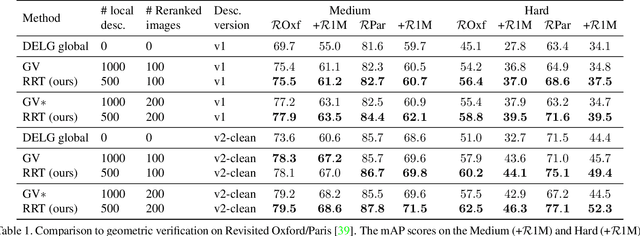
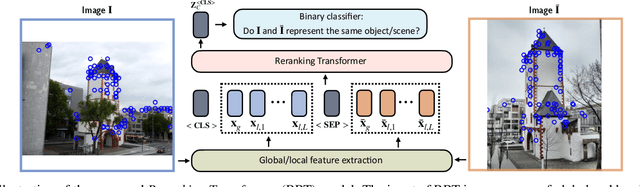
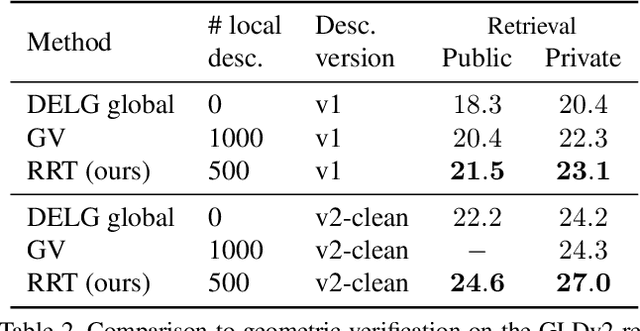
Instance-level image retrieval is the task of searching in a large database for images that match an object in a query image. To address this task, systems usually rely on a retrieval step that uses global image descriptors, and a subsequent step that performs domain-specific refinements or reranking by leveraging operations such as geometric verification based on local features. In this work, we propose Reranking Transformers (RRTs) as a general model to incorporate both local and global features to rerank the matching images in a supervised fashion and thus replace the relatively expensive process of geometric verification. RRTs are lightweight and can be easily parallelized so that reranking a set of top matching results can be performed in a single forward-pass. We perform extensive experiments on the Revisited Oxford and Paris datasets, and the Google Landmark v2 dataset, showing that RRTs outperform previous reranking approaches while using much fewer local descriptors. Moreover, we demonstrate that, unlike existing approaches, RRTs can be optimized jointly with the feature extractor, which can lead to feature representations tailored to downstream tasks and further accuracy improvements. Training code and pretrained models will be made public.
Learning Tuple Compatibility for Conditional OutfitRecommendation
Aug 18, 2020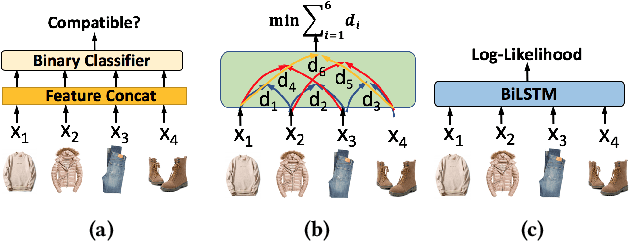
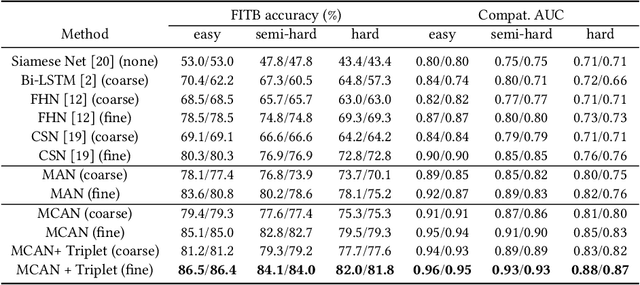
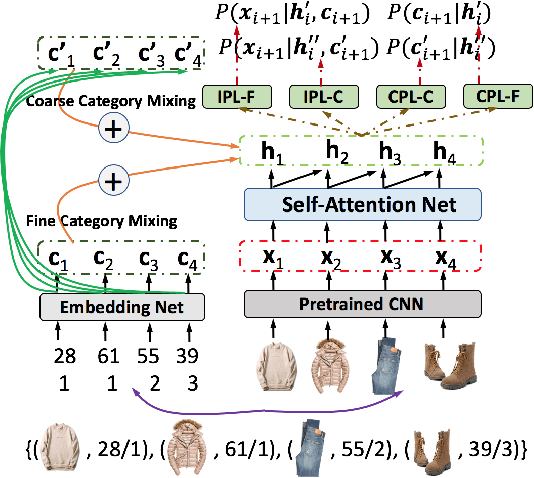
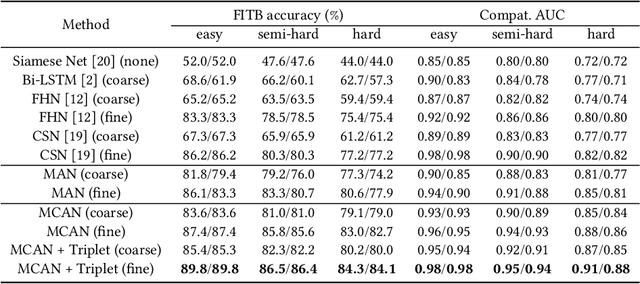
Outfit recommendation requires the answers of some challenging outfit compatibility questions such as 'Which pair of boots and school bag go well with my jeans and sweater?'. It is more complicated than conventional similarity search, and needs to consider not only visual aesthetics but also the intrinsic fine-grained and multi-category nature of fashion items. Some existing approaches solve the problem through sequential models or learning pair-wise distances between items. However, most of them only consider coarse category information in defining fashion compatibility while neglecting the fine-grained category information often desired in practical applications. To better define the fashion compatibility and more flexibly meet different needs, we propose a novel problem of learning compatibility among multiple tuples (each consisting of an item and category pair), and recommending fashion items following the category choices from customers. Our contributions include: 1) Designing a Mixed Category Attention Net (MCAN) which integrates both fine-grained and coarse category information into recommendation and learns the compatibility among fashion tuples. MCAN can explicitly and effectively generate diverse and controllable recommendations based on need. 2) Contributing a new dataset IQON, which follows eastern culture and can be used to test the generalization of recommendation systems. Our extensive experiments on a reference dataset Polyvore and our dataset IQON demonstrate that our method significantly outperforms state-of-the-art recommendation methods.
Adversarial Code Learning for Image Generation
Jan 30, 2020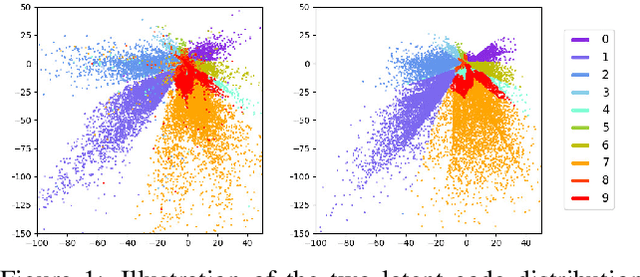
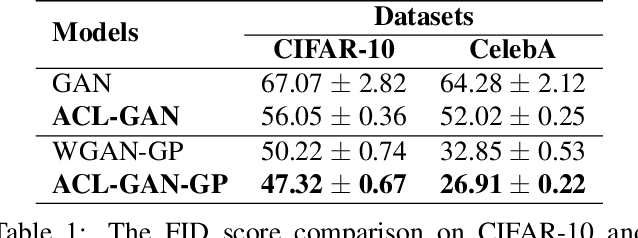
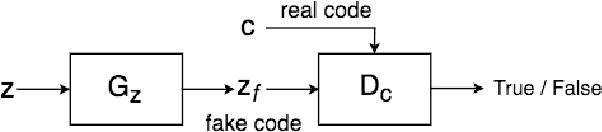

We introduce the "adversarial code learning" (ACL) module that improves overall image generation performance to several types of deep models. Instead of performing a posterior distribution modeling in the pixel spaces of generators, ACLs aim to jointly learn a latent code with another image encoder/inference net, with a prior noise as its input. We conduct the learning in an adversarial learning process, which bears a close resemblance to the original GAN but again shifts the learning from image spaces to prior and latent code spaces. ACL is a portable module that brings up much more flexibility and possibilities in generative model designs. First, it allows flexibility to convert non-generative models like Autoencoders and standard classification models to decent generative models. Second, it enhances existing GANs' performance by generating meaningful codes and images from any part of the prior. We have incorporated our ACL module with the aforementioned frameworks and have performed experiments on synthetic, MNIST, CIFAR-10, and CelebA datasets. Our models have achieved significant improvements which demonstrated the generality for image generation tasks.
Fashion-AttGAN: Attribute-Aware Fashion Editing with Multi-Objective GAN
Apr 20, 2019
In this paper, we introduce attribute-aware fashion-editing, a novel task, to the fashion domain. We re-define the overall objectives in AttGAN and propose the Fashion-AttGAN model for this new task. A dataset is constructed for this task with 14,221 and 22 attributes, which has been made publically available. Experimental results show the effectiveness of our Fashion-AttGAN on fashion editing over the original AttGAN.
Transformed Residual Quantization for Approximate Nearest Neighbor Search
Dec 22, 2015

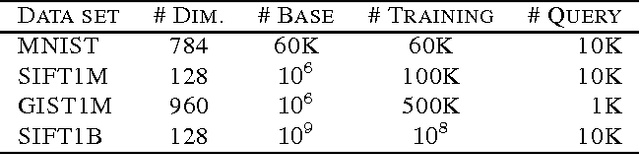

The success of product quantization (PQ) for fast nearest neighbor search depends on the exponentially reduced complexities of both storage and computation with respect to the codebook size. Recent efforts have been focused on employing sophisticated optimization strategies, or seeking more effective models. Residual quantization (RQ) is such an alternative that holds the same property as PQ in terms of the aforementioned complexities. In addition to being a direct replacement of PQ, hybrids of PQ and RQ can yield more gains for approximate nearest neighbor search. This motivated us to propose a novel approach to optimizing RQ and the related hybrid models. With an observation of the general randomness increase in a residual space, we propose a new strategy that jointly learns a local transformation per residual cluster with an ultimate goal to reduce overall quantization errors. We have shown that our approach can achieve significantly better accuracy on nearest neighbor search than both the original and the optimized PQ on several very large scale benchmarks.