 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccommodate Knowledge Conflicts in Retrieval-augmented LLMs: Towards Reliable Response Generation in the Wild
Apr 17, 2025The proliferation of large language models (LLMs) has significantly advanced information retrieval systems, particularly in response generation (RG). Unfortunately, LLMs often face knowledge conflicts between internal memory and retrievaled external information, arising from misinformation, biases, or outdated knowledge. These conflicts undermine response reliability and introduce uncertainty in decision-making. In this work, we analyze how LLMs navigate knowledge conflicts from an information-theoretic perspective and reveal that when conflicting and supplementary information exhibit significant differences, LLMs confidently resolve their preferences. However, when the distinction is ambiguous, LLMs experience heightened uncertainty. Based on this insight, we propose Swin-VIB, a novel framework that integrates a pipeline of variational information bottleneck models into adaptive augmentation of retrieved information and guiding LLM preference in response generation. Extensive experiments on single-choice, open-ended question-answering (QA), and retrieval augmented generation (RAG) validate our theoretical findings and demonstrate the efficacy of Swin-VIB. Notably, our method improves single-choice task accuracy by at least 7.54\% over competitive baselines.
Hierarchical Mutual Information Analysis: Towards Multi-view Clustering in The Wild
Oct 28, 2023Multi-view clustering (MVC) can explore common semantics from unsupervised views generated by different sources, and thus has been extensively used in applications of practical computer vision. Due to the spatio-temporal asynchronism, multi-view data often suffer from view missing and are unaligned in real-world applications, which makes it difficult to learn consistent representations. To address the above issues, this work proposes a deep MVC framework where data recovery and alignment are fused in a hierarchically consistent way to maximize the mutual information among different views and ensure the consistency of their latent spaces. More specifically, we first leverage dual prediction to fill in missing views while achieving the instance-level alignment, and then take the contrastive reconstruction to achieve the class-level alignment. To the best of our knowledge, this could be the first successful attempt to handle the missing and unaligned data problem separately with different learning paradigms. Extensive experiments on public datasets demonstrate that our method significantly outperforms state-of-the-art methods on multi-view clustering even in the cases of view missing and unalignment.
Self-supervised Multi-view Clustering in Computer Vision: A Survey
Sep 18, 2023



Multi-view clustering (MVC) has had significant implications in cross-modal representation learning and data-driven decision-making in recent years. It accomplishes this by leveraging the consistency and complementary information among multiple views to cluster samples into distinct groups. However, as contrastive learning continues to evolve within the field of computer vision, self-supervised learning has also made substantial research progress and is progressively becoming dominant in MVC methods. It guides the clustering process by designing proxy tasks to mine the representation of image and video data itself as supervisory information. Despite the rapid development of self-supervised MVC, there has yet to be a comprehensive survey to analyze and summarize the current state of research progress. Therefore, this paper explores the reasons and advantages of the emergence of self-supervised MVC and discusses the internal connections and classifications of common datasets, data issues, representation learning methods, and self-supervised learning methods. This paper does not only introduce the mechanisms for each category of methods but also gives a few examples of how these techniques are used. In the end, some open problems are pointed out for further investigation and development.
Self-supervised Image Clustering from Multiple Incomplete Views via Constrastive Complementary Generation
Sep 24, 2022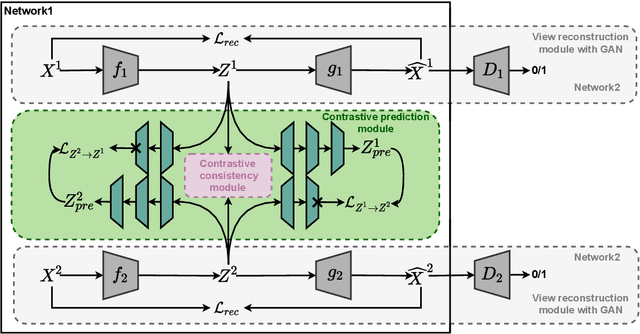
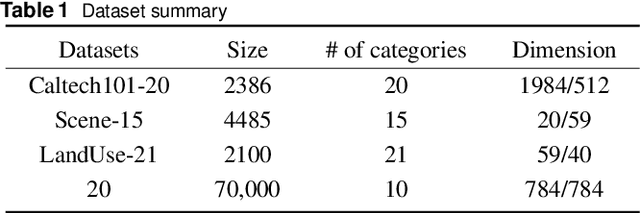
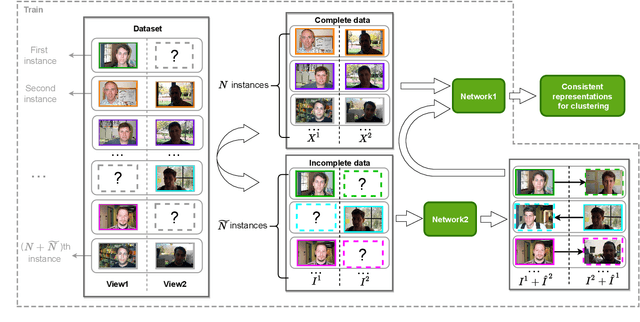
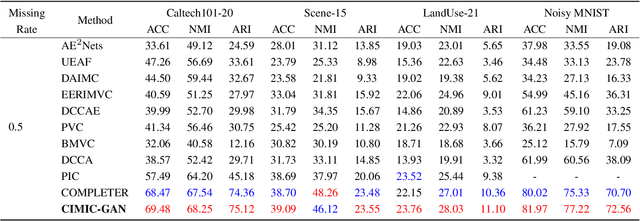
Incomplete Multi-View Clustering aims to enhance clustering performance by using data from multiple modalities. Despite the fact that several approaches for studying this issue have been proposed, the following drawbacks still persist: 1) It's difficult to learn latent representations that account for complementarity yet consistency without using label information; 2) and thus fails to take full advantage of the hidden information in incomplete data results in suboptimal clustering performance when complete data is scarce. In this paper, we propose Contrastive Incomplete Multi-View Image Clustering with Generative Adversarial Networks (CIMIC-GAN), which uses GAN to fill in incomplete data and uses double contrastive learning to learn consistency on complete and incomplete data. More specifically, considering diversity and complementary information among multiple modalities, we incorporate autoencoding representation of complete and incomplete data into double contrastive learning to achieve learning consistency. Integrating GANs into the autoencoding process can not only take full advantage of new features of incomplete data, but also better generalize the model in the presence of high data missing rates. Experiments conducted on \textcolor{black}{four} extensively-used datasets show that CIMIC-GAN outperforms state-of-the-art incomplete multi-View clustering methods.
Journalistic Guidelines Aware News Image Captioning
Sep 10, 2021
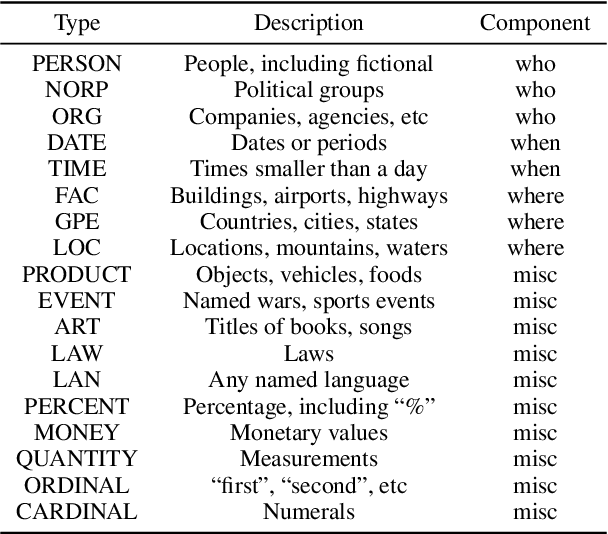

The task of news article image captioning aims to generate descriptive and informative captions for news article images. Unlike conventional image captions that simply describe the content of the image in general terms, news image captions follow journalistic guidelines and rely heavily on named entities to describe the image content, often drawing context from the whole article they are associated with. In this work, we propose a new approach to this task, motivated by caption guidelines that journalists follow. Our approach, Journalistic Guidelines Aware News Image Captioning (JoGANIC), leverages the structure of captions to improve the generation quality and guide our representation design. Experimental results, including detailed ablation studies, on two large-scale publicly available datasets show that JoGANIC substantially outperforms state-of-the-art methods both on caption generation and named entity related metrics.
ReFormer: The Relational Transformer for Image Captioning
Jul 29, 2021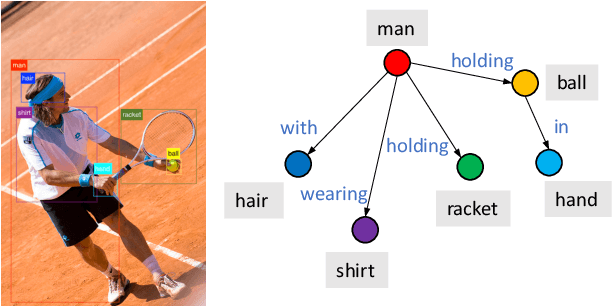
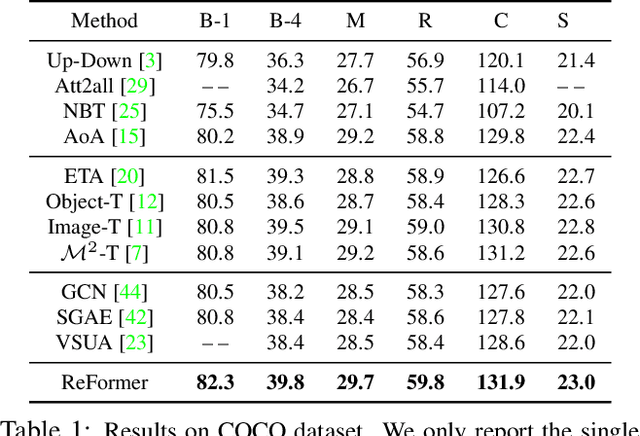
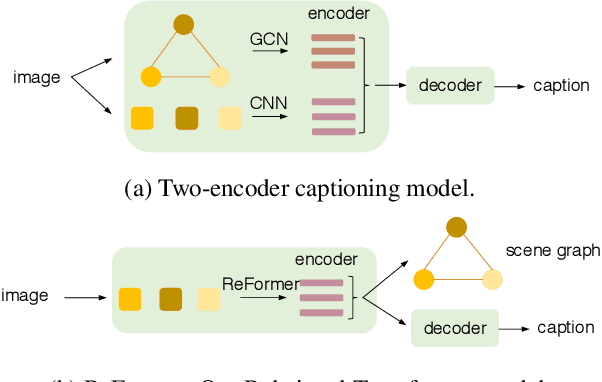
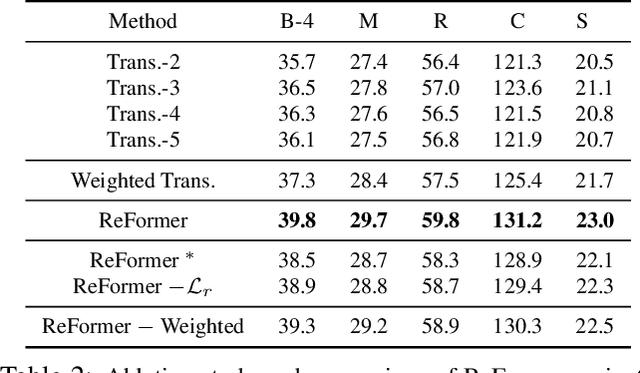
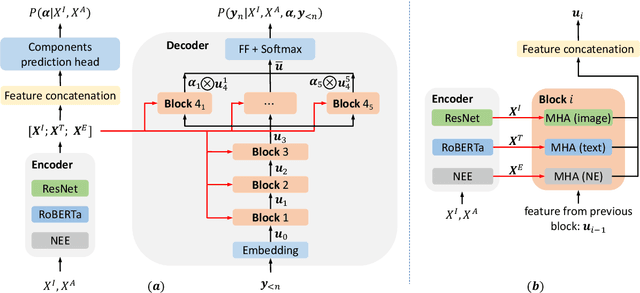
Image captioning is shown to be able to achieve a better performance by using scene graphs to represent the relations of objects in the image. The current captioning encoders generally use a Graph Convolutional Net (GCN) to represent the relation information and merge it with the object region features via concatenation or convolution to get the final input for sentence decoding. However, the GCN-based encoders in the existing methods are less effective for captioning due to two reasons. First, using the image captioning as the objective (i.e., Maximum Likelihood Estimation) rather than a relation-centric loss cannot fully explore the potential of the encoder. Second, using a pre-trained model instead of the encoder itself to extract the relationships is not flexible and cannot contribute to the explainability of the model. To improve the quality of image captioning, we propose a novel architecture ReFormer -- a RElational transFORMER to generate features with relation information embedded and to explicitly express the pair-wise relationships between objects in the image. ReFormer incorporates the objective of scene graph generation with that of image captioning using one modified Transformer model. This design allows ReFormer to generate not only better image captions with the bene-fit of extracting strong relational image features, but also scene graphs to explicitly describe the pair-wise relation-ships. Experiments on publicly available datasets show that our model significantly outperforms state-of-the-art methods on image captioning and scene graph generation
Crossing-Domain Generative Adversarial Networks for Unsupervised Multi-Domain Image-to-Image Translation
Aug 27, 2020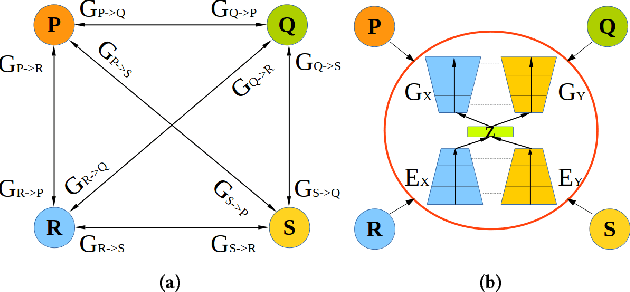
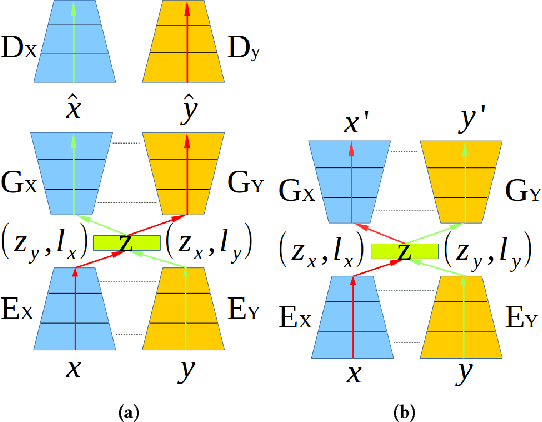
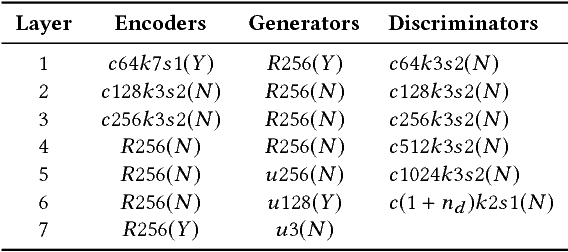
State-of-the-art techniques in Generative Adversarial Networks (GANs) have shown remarkable success in image-to-image translation from peer domain X to domain Y using paired image data. However, obtaining abundant paired data is a non-trivial and expensive process in the majority of applications. When there is a need to translate images across n domains, if the training is performed between every two domains, the complexity of the training will increase quadratically. Moreover, training with data from two domains only at a time cannot benefit from data of other domains, which prevents the extraction of more useful features and hinders the progress of this research area. In this work, we propose a general framework for unsupervised image-to-image translation across multiple domains, which can translate images from domain X to any a domain without requiring direct training between the two domains involved in image translation. A byproduct of the framework is the reduction of computing time and computing resources, since it needs less time than training the domains in pairs as is done in state-of-the-art works. Our proposed framework consists of a pair of encoders along with a pair of GANs which learns high-level features across different domains to generate diverse and realistic samples from. Our framework shows competing results on many image-to-image tasks compared with state-of-the-art techniques.
Learning Tuple Compatibility for Conditional OutfitRecommendation
Aug 18, 2020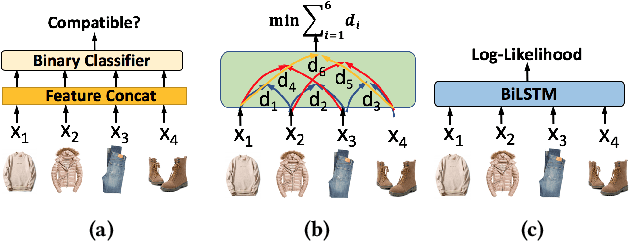
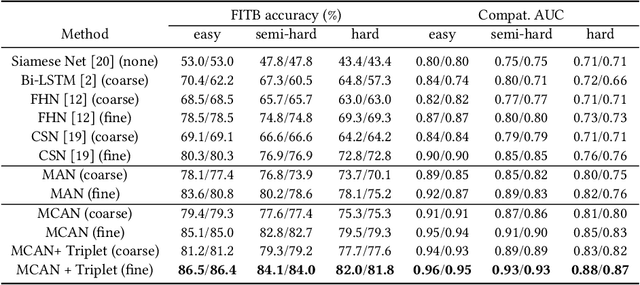
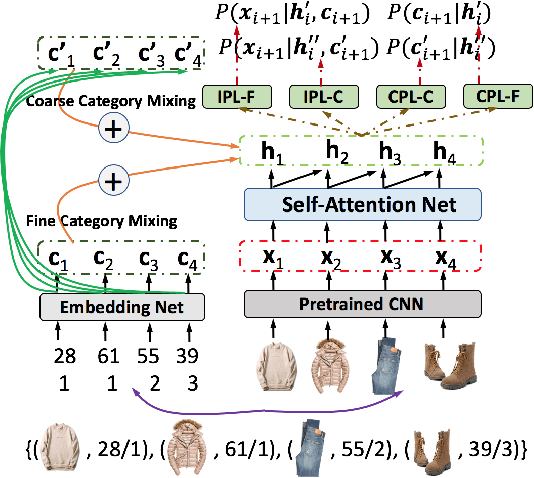
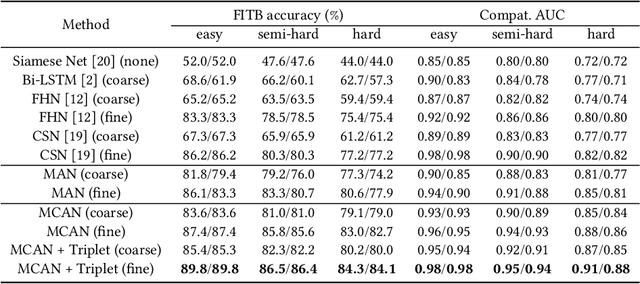
Outfit recommendation requires the answers of some challenging outfit compatibility questions such as 'Which pair of boots and school bag go well with my jeans and sweater?'. It is more complicated than conventional similarity search, and needs to consider not only visual aesthetics but also the intrinsic fine-grained and multi-category nature of fashion items. Some existing approaches solve the problem through sequential models or learning pair-wise distances between items. However, most of them only consider coarse category information in defining fashion compatibility while neglecting the fine-grained category information often desired in practical applications. To better define the fashion compatibility and more flexibly meet different needs, we propose a novel problem of learning compatibility among multiple tuples (each consisting of an item and category pair), and recommending fashion items following the category choices from customers. Our contributions include: 1) Designing a Mixed Category Attention Net (MCAN) which integrates both fine-grained and coarse category information into recommendation and learns the compatibility among fashion tuples. MCAN can explicitly and effectively generate diverse and controllable recommendations based on need. 2) Contributing a new dataset IQON, which follows eastern culture and can be used to test the generalization of recommendation systems. Our extensive experiments on a reference dataset Polyvore and our dataset IQON demonstrate that our method significantly outperforms state-of-the-art recommendation methods.
Fashion Captioning: Towards Generating Accurate Descriptions with Semantic Rewards
Aug 06, 2020
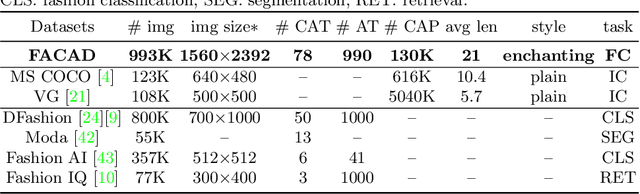
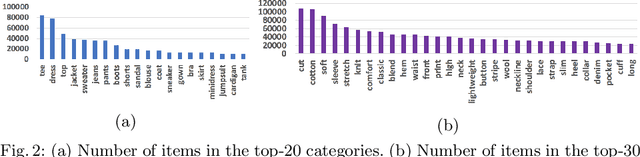
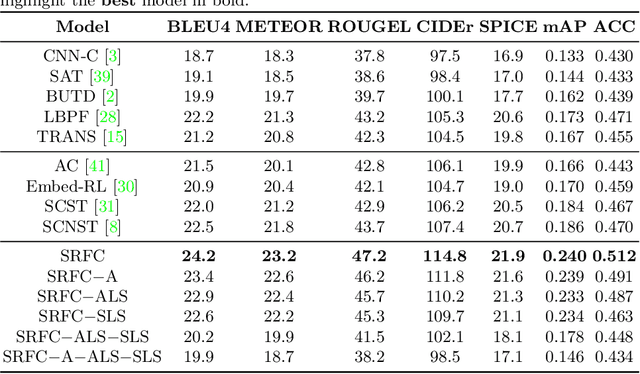
Generating accurate descriptions for online fashion items is important not only for enhancing customers' shopping experiences, but also for the increase of online sales. Besides the need of correctly presenting the attributes of items, the expressions in an enchanting style could better attract customer interests. The goal of this work is to develop a novel learning framework for accurate and expressive fashion captioning. Different from popular work on image captioning, it is hard to identify and describe the rich attributes of fashion items. We seed the description of an item by first identifying its attributes, and introduce attribute-level semantic (ALS) reward and sentence-level semantic (SLS) reward as metrics to improve the quality of text descriptions. We further integrate the training of our model with maximum likelihood estimation (MLE), attribute embedding, and Reinforcement Learning (RL). To facilitate the learning, we build a new FAshion CAptioning Dataset (FACAD), which contains 993K images and 130K corresponding enchanting and diverse descriptions. Experiments on FACAD demonstrate the effectiveness of our model.
Learning Color Compatibility in Fashion Outfits
Jul 05, 2020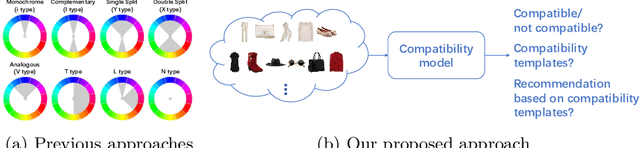
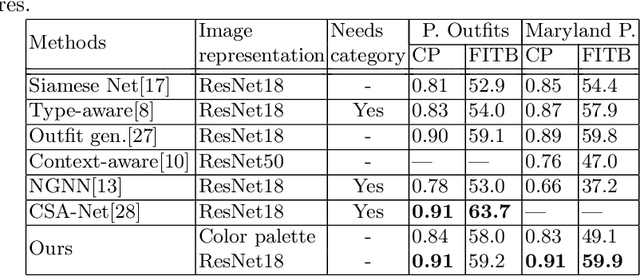
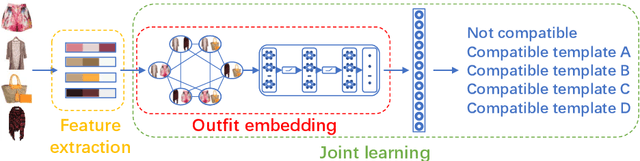
Color compatibility is important for evaluating the compatibility of a fashion outfit, yet it was neglected in previous studies. We bring this important problem to researchers' attention and present a compatibility learning framework as solution to various fashion tasks. The framework consists of a novel way to model outfit compatibility and an innovative learning scheme. Specifically, we model the outfits as graphs and propose a novel graph construction to better utilize the power of graph neural networks. Then we utilize both ground-truth labels and pseudo labels to train the compatibility model in a weakly-supervised manner.Extensive experimental results verify the importance of color compatibility alone with the effectiveness of our framework. With color information alone, our model's performance is already comparable to previous methods that use deep image features. Our full model combining the aforementioned contributions set the new state-of-the-art in fashion compatibility prediction.