 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEHA: A Dataset of Conflict Events in the Horn of Africa
Dec 18, 2024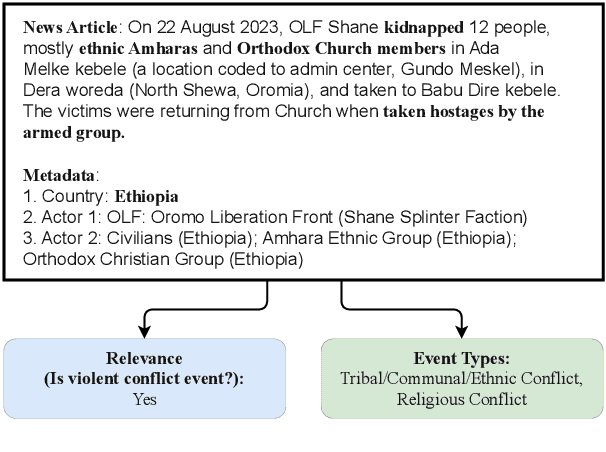


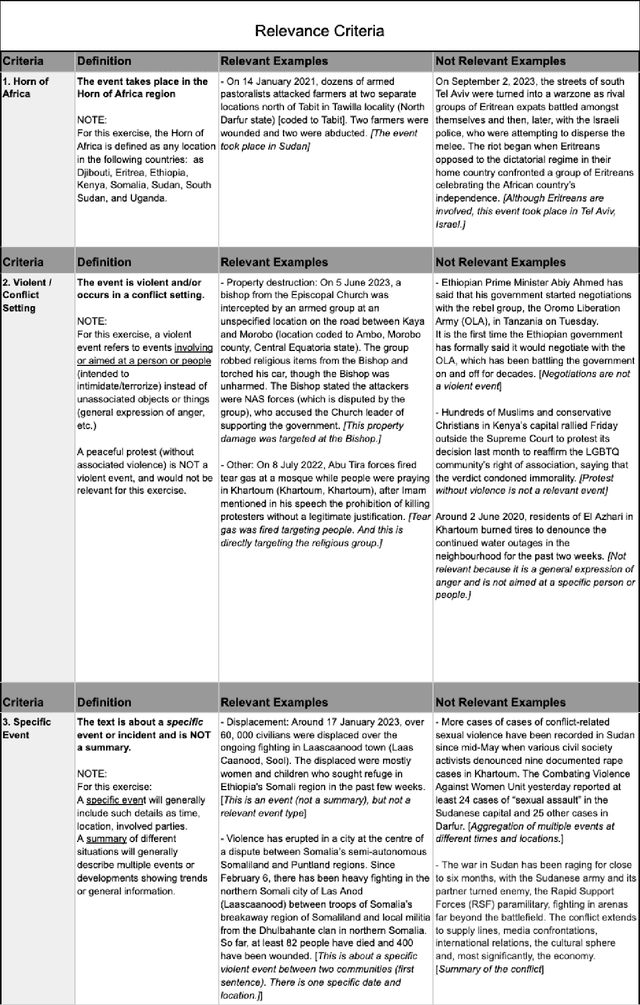
Natural Language Processing (NLP) of news articles can play an important role in understanding the dynamics and causes of violent conflict. Despite the availability of datasets categorizing various conflict events, the existing labels often do not cover all of the fine-grained violent conflict event types relevant to areas like the Horn of Africa. In this paper, we introduce a new benchmark dataset Conflict Events in the Horn of Africa region (CEHA) and propose a new task for identifying violent conflict events using online resources with this dataset. The dataset consists of 500 English event descriptions regarding conflict events in the Horn of Africa region with fine-grained event-type definitions that emphasize the cause of the conflict. This dataset categorizes the key types of conflict risk according to specific areas required by stakeholders in the Humanitarian-Peace-Development Nexus. Additionally, we conduct extensive experiments on two tasks supported by this dataset: Event-relevance Classification and Event-type Classification. Our baseline models demonstrate the challenging nature of these tasks and the usefulness of our dataset for model evaluations in low-resource settings with limited number of training data.
HumVI: A Multilingual Dataset for Detecting Violent Incidents Impacting Humanitarian Aid
Oct 08, 2024



Humanitarian organizations can enhance their effectiveness by analyzing data to discover trends, gather aggregated insights, manage their security risks, support decision-making, and inform advocacy and funding proposals. However, data about violent incidents with direct impact and relevance for humanitarian aid operations is not readily available. An automatic data collection and NLP-backed classification framework aligned with humanitarian perspectives can help bridge this gap. In this paper, we present HumVI - a dataset comprising news articles in three languages (English, French, Arabic) containing instances of different types of violent incidents categorized by the humanitarian sector they impact, e.g., aid security, education, food security, health, and protection. Reliable labels were obtained for the dataset by partnering with a data-backed humanitarian organization, Insecurity Insight. We provide multiple benchmarks for the dataset, employing various deep learning architectures and techniques, including data augmentation and mask loss, to address different task-related challenges, e.g., domain expansion. The dataset is publicly available at https://github.com/dataminr-ai/humvi-dataset.
Explain then Rank: Scale Calibration of Neural Rankers Using Natural Language Explanations from Large Language Models
Feb 19, 2024



The process of scale calibration in ranking systems involves adjusting the outputs of rankers to correspond with significant qualities like click-through rates or relevance, crucial for mirroring real-world value and thereby boosting the system's effectiveness and reliability. Although there has been research on calibrated ranking losses within learning-to-rank models, the particular issue of adjusting the scale for neural rankers, which excel in handling textual information, has not been thoroughly examined. Neural ranking models are adept at processing text data, yet the application of existing scale calibration techniques to these models poses significant challenges due to their complexity and the intensive training they require, often resulting in suboptimal outcomes. This study delves into the potential of large language models (LLMs) to provide uncertainty measurements for a query and document pair that correlate with the scale-calibrated scores. By employing Monte Carlo sampling to gauge relevance probabilities from LLMs and incorporating natural language explanations (NLEs) to articulate this uncertainty, we carry out comprehensive tests on two major document ranking datasets. Our findings reveal that the approach leveraging NLEs outperforms existing calibration methods under various training scenarios, leading to better calibrated neural rankers.
Dissecting users' needs for search result explanations
Jan 29, 2024
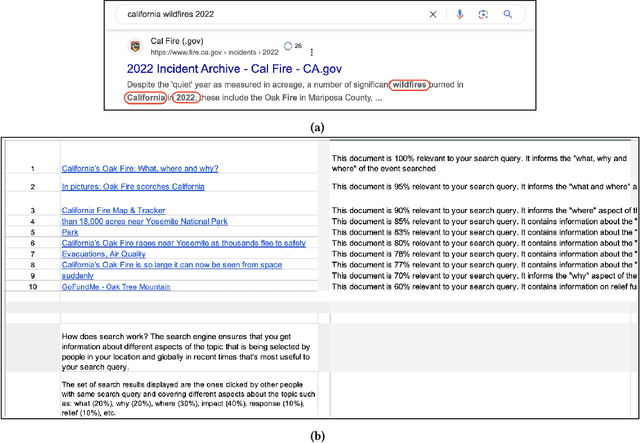
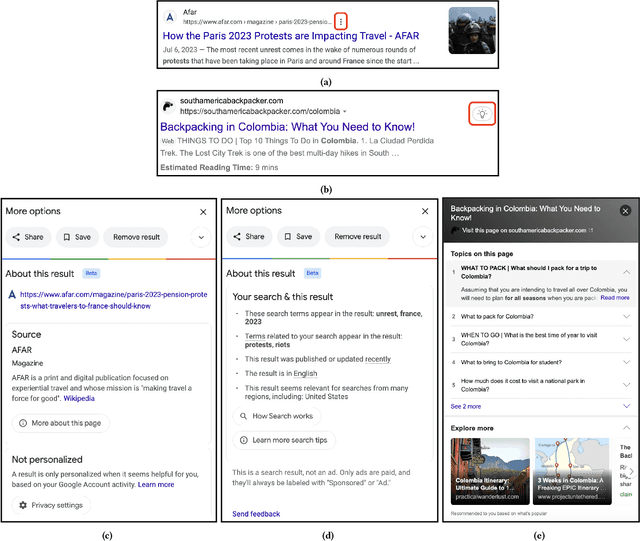
There is a growing demand for transparency in search engines to understand how search results are curated and to enhance users' trust. Prior research has introduced search result explanations with a focus on how to explain, assuming explanations are beneficial. Our study takes a step back to examine if search explanations are needed and when they are likely to provide benefits. Additionally, we summarize key characteristics of helpful explanations and share users' perspectives on explanation features provided by Google and Bing. Interviews with non-technical individuals reveal that users do not always seek or understand search explanations and mostly desire them for complex and critical tasks. They find Google's search explanations too obvious but appreciate the ability to contest search results. Based on our findings, we offer design recommendations for search engines and explanations to help users better evaluate search results and enhance their search experience.
Counterfactual Editing for Search Result Explanation
Jan 25, 2023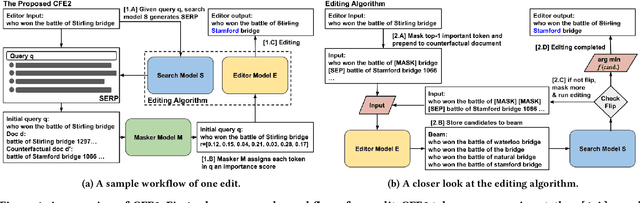



Recently substantial improvements in neural retrieval methods also bring to light the inherent blackbox nature of these methods, especially when viewed from an explainability perspective. Most of existing works on Search Result Explanation (SeRE) are designed to provide factual explanation, i.e. to find/generate supporting evidence about documents' relevance to search queries. However, research in cognitive sciences have shown that human explanations are contrastive i.e. people explain an observed event using some counterfactual events; such explanations reduce cognitive load, and provide actionable insights. Though already proven effective in machine learning and NLP communities, the formulation and impact of counterfactual explanations have not been well studied for search systems. In this work, we aim to investigate the effectiveness of this perspective via proposing and evaluating counterfactual explanations for the task of SeRE. Specifically, we first conduct a user study where we investigate if counterfactual explanations indeed improve search sessions' effectiveness. Taking this as a motivation, we discuss the desiderata that an ideal counterfactual explanation method for SeRE should adhere to. Next, we propose a method $\text{CFE}^2$ (\textbf{C}ounter\textbf{F}actual \textbf{E}xplanation with \textbf{E}diting) to provide pairwise explanations to search engine result page. Finally, we showcase that the proposed method when evaluated on four publicly available datasets outperforms baselines on both metrics and human evaluation.
XLTime: A Cross-Lingual Knowledge Transfer Framework for Temporal Expression Extraction
May 03, 2022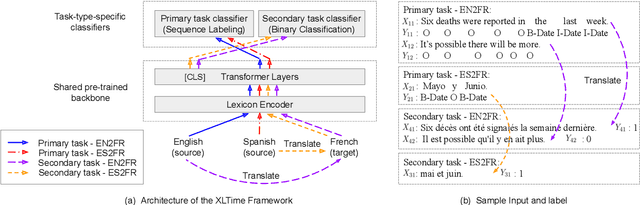
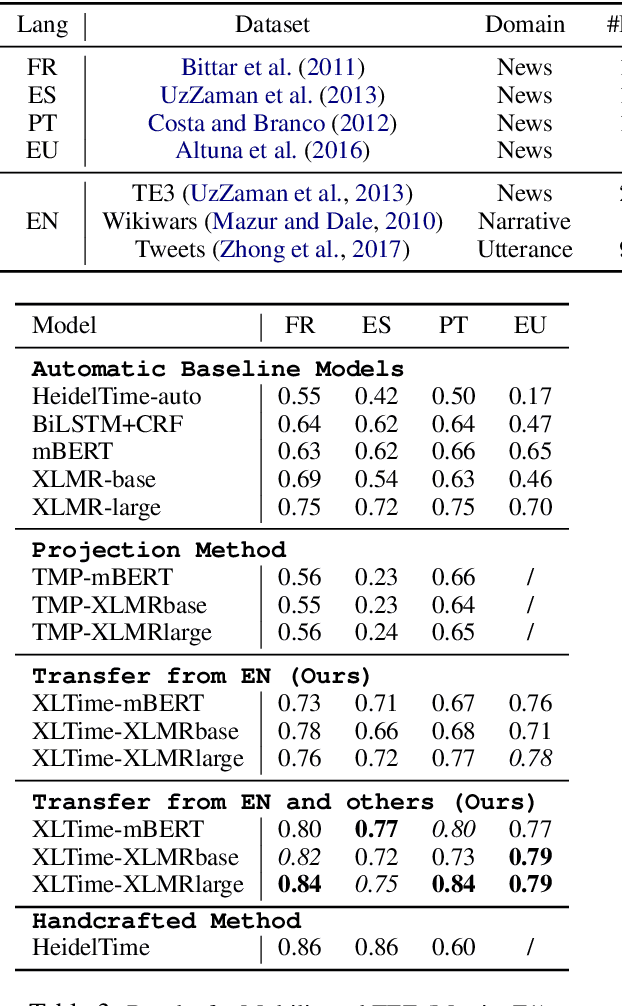
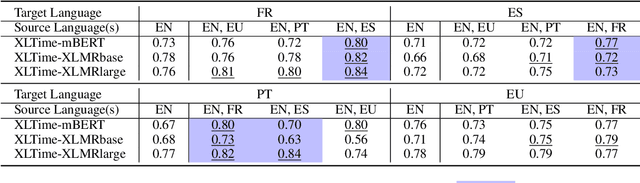
Temporal Expression Extraction (TEE) is essential for understanding time in natural language. It has applications in Natural Language Processing (NLP) tasks such as question answering, information retrieval, and causal inference. To date, work in this area has mostly focused on English as there is a scarcity of labeled data for other languages. We propose XLTime, a novel framework for multilingual TEE. XLTime works on top of pre-trained language models and leverages multi-task learning to prompt cross-language knowledge transfer both from English and within the non-English languages. XLTime alleviates problems caused by a shortage of data in the target language. We apply XLTime with different language models and show that it outperforms the previous automatic SOTA methods on French, Spanish, Portuguese, and Basque, by large margins. XLTime also closes the gap considerably on the handcrafted HeidelTime method.
Journalistic Guidelines Aware News Image Captioning
Sep 10, 2021
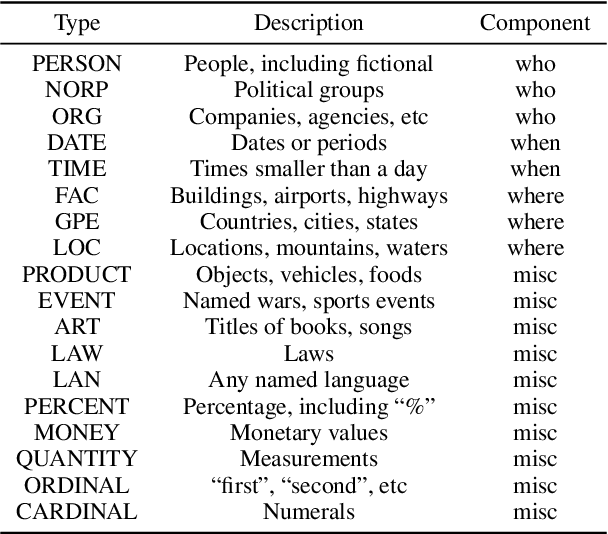

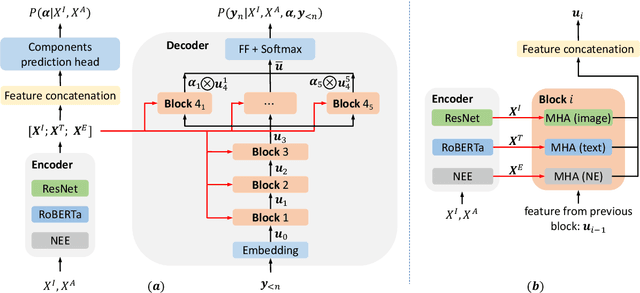
The task of news article image captioning aims to generate descriptive and informative captions for news article images. Unlike conventional image captions that simply describe the content of the image in general terms, news image captions follow journalistic guidelines and rely heavily on named entities to describe the image content, often drawing context from the whole article they are associated with. In this work, we propose a new approach to this task, motivated by caption guidelines that journalists follow. Our approach, Journalistic Guidelines Aware News Image Captioning (JoGANIC), leverages the structure of captions to improve the generation quality and guide our representation design. Experimental results, including detailed ablation studies, on two large-scale publicly available datasets show that JoGANIC substantially outperforms state-of-the-art methods both on caption generation and named entity related metrics.