 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCEHA: A Dataset of Conflict Events in the Horn of Africa
Dec 18, 2024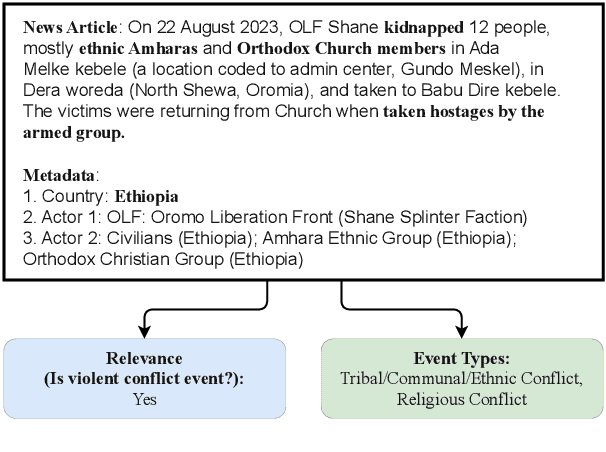


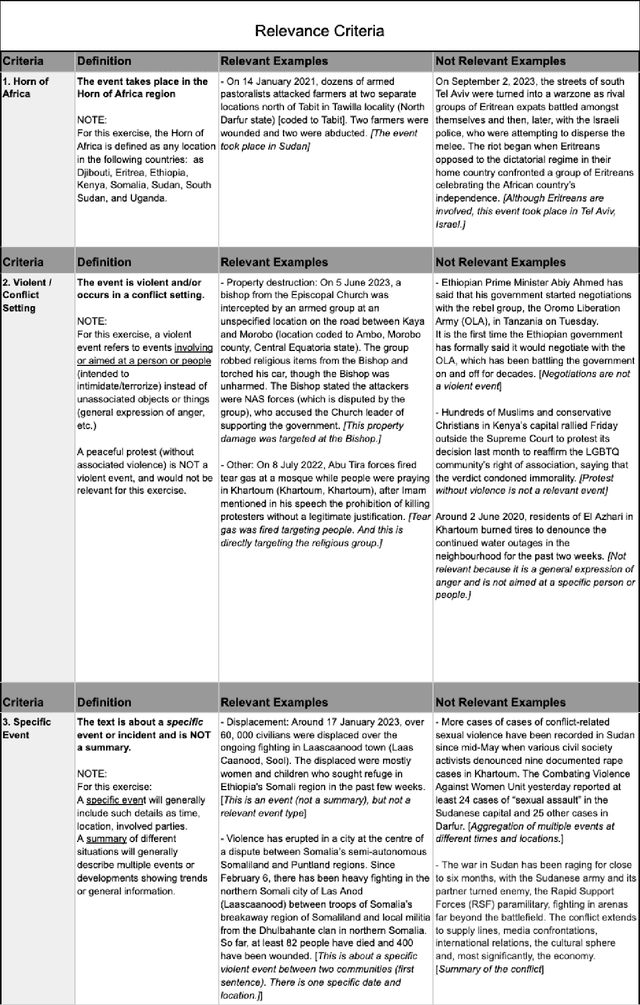
Natural Language Processing (NLP) of news articles can play an important role in understanding the dynamics and causes of violent conflict. Despite the availability of datasets categorizing various conflict events, the existing labels often do not cover all of the fine-grained violent conflict event types relevant to areas like the Horn of Africa. In this paper, we introduce a new benchmark dataset Conflict Events in the Horn of Africa region (CEHA) and propose a new task for identifying violent conflict events using online resources with this dataset. The dataset consists of 500 English event descriptions regarding conflict events in the Horn of Africa region with fine-grained event-type definitions that emphasize the cause of the conflict. This dataset categorizes the key types of conflict risk according to specific areas required by stakeholders in the Humanitarian-Peace-Development Nexus. Additionally, we conduct extensive experiments on two tasks supported by this dataset: Event-relevance Classification and Event-type Classification. Our baseline models demonstrate the challenging nature of these tasks and the usefulness of our dataset for model evaluations in low-resource settings with limited number of training data.
Uchaguzi-2022: A Dataset of Citizen Reports on the 2022 Kenyan Election
Dec 17, 2024



Online reporting platforms have enabled citizens around the world to collectively share their opinions and report in real time on events impacting their local communities. Systematically organizing (e.g., categorizing by attributes) and geotagging large amounts of crowdsourced information is crucial to ensuring that accurate and meaningful insights can be drawn from this data and used by policy makers to bring about positive change. These tasks, however, typically require extensive manual annotation efforts. In this paper we present Uchaguzi-2022, a dataset of 14k categorized and geotagged citizen reports related to the 2022 Kenyan General Election containing mentions of election-related issues such as official misconduct, vote count irregularities, and acts of violence. We use this dataset to investigate whether language models can assist in scalably categorizing and geotagging reports, thus highlighting its potential application in the AI for Social Good space.
HumVI: A Multilingual Dataset for Detecting Violent Incidents Impacting Humanitarian Aid
Oct 08, 2024



Humanitarian organizations can enhance their effectiveness by analyzing data to discover trends, gather aggregated insights, manage their security risks, support decision-making, and inform advocacy and funding proposals. However, data about violent incidents with direct impact and relevance for humanitarian aid operations is not readily available. An automatic data collection and NLP-backed classification framework aligned with humanitarian perspectives can help bridge this gap. In this paper, we present HumVI - a dataset comprising news articles in three languages (English, French, Arabic) containing instances of different types of violent incidents categorized by the humanitarian sector they impact, e.g., aid security, education, food security, health, and protection. Reliable labels were obtained for the dataset by partnering with a data-backed humanitarian organization, Insecurity Insight. We provide multiple benchmarks for the dataset, employing various deep learning architectures and techniques, including data augmentation and mask loss, to address different task-related challenges, e.g., domain expansion. The dataset is publicly available at https://github.com/dataminr-ai/humvi-dataset.
A New Task and Dataset on Detecting Attacks on Human Rights Defenders
Jun 30, 2023



The ability to conduct retrospective analyses of attacks on human rights defenders over time and by location is important for humanitarian organizations to better understand historical or ongoing human rights violations and thus better manage the global impact of such events. We hypothesize that NLP can support such efforts by quickly processing large collections of news articles to detect and summarize the characteristics of attacks on human rights defenders. To that end, we propose a new dataset for detecting Attacks on Human Rights Defenders (HRDsAttack) consisting of crowdsourced annotations on 500 online news articles. The annotations include fine-grained information about the type and location of the attacks, as well as information about the victim(s). We demonstrate the usefulness of the dataset by using it to train and evaluate baseline models on several sub-tasks to predict the annotated characteristics.
BUMP: A Benchmark of Unfaithful Minimal Pairs for Meta-Evaluation of Faithfulness Metrics
Dec 20, 2022
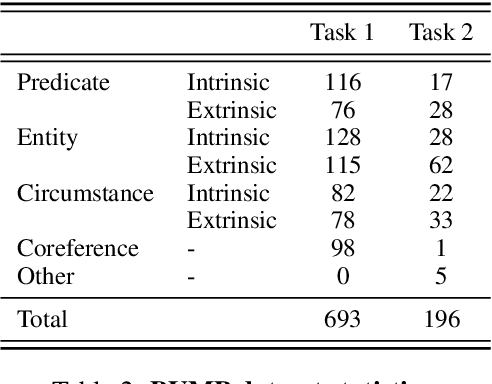

The proliferation of automatic faithfulness metrics for summarization has produced a need for benchmarks to evaluate them. While existing benchmarks measure the correlation with human judgements of faithfulness on model-generated summaries, they are insufficient for diagnosing whether metrics are: 1) consistent, i.e., decrease as errors are introduced into a summary, 2) effective on human-written texts, and 3) sensitive to different error types (as summaries can contain multiple errors). To address these needs, we present a benchmark of unfaithful minimal pairs (BUMP), a dataset of 889 human-written, minimally different summary pairs, where a single error (from an ontology of 7 types) is introduced to a summary from the CNN/DailyMail dataset to produce an unfaithful summary. We find BUMP complements existing benchmarks in a number of ways: 1) the summaries in BUMP are harder to discriminate and less probable under SOTA summarization models, 2) BUMP enables measuring the consistency of metrics, and reveals that the most discriminative metrics tend not to be the most consistent, 3) BUMP enables the measurement of metrics' performance on individual error types and highlights areas of weakness for future work.
Is getting the right answer just about choosing the right words? The role of syntactically-informed features in short answer scoring
Mar 05, 2014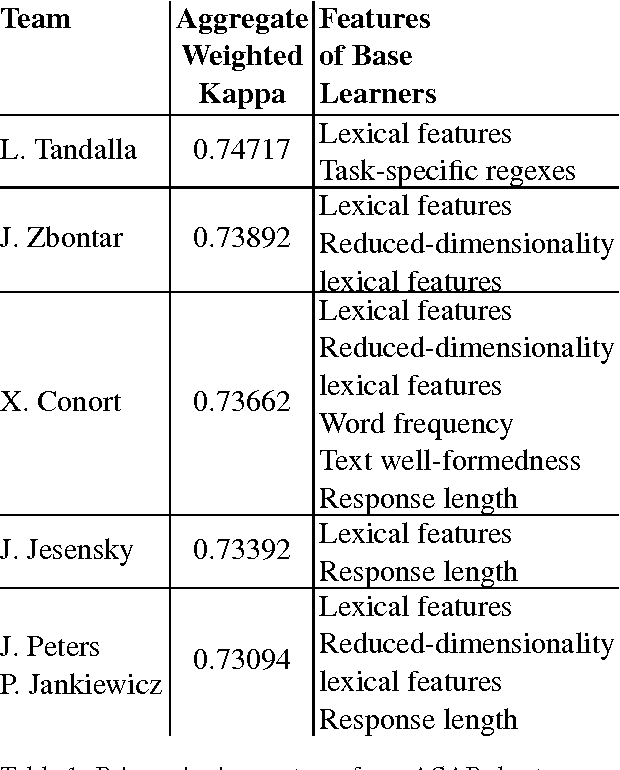
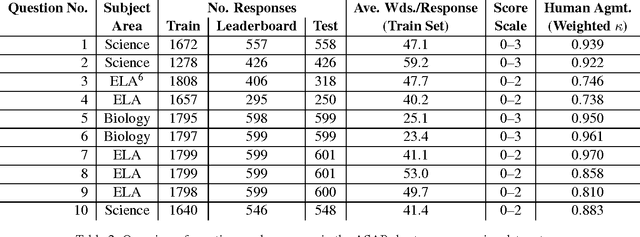
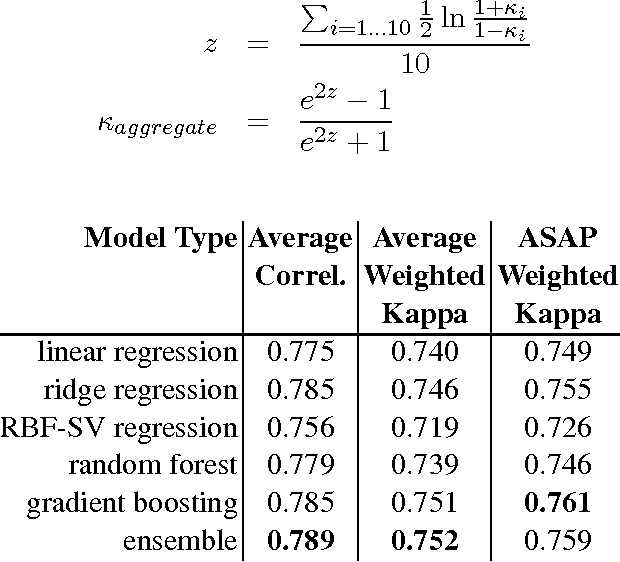
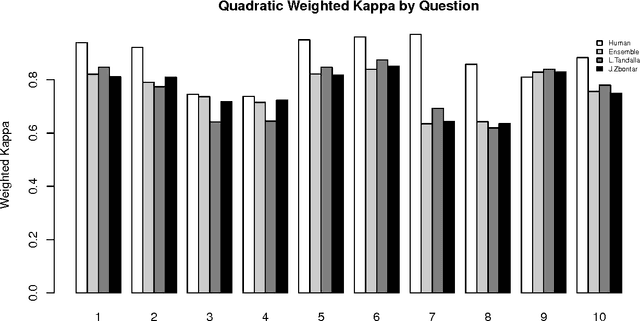
Developments in the educational landscape have spurred greater interest in the problem of automatically scoring short answer questions. A recent shared task on this topic revealed a fundamental divide in the modeling approaches that have been applied to this problem, with the best-performing systems split between those that employ a knowledge engineering approach and those that almost solely leverage lexical information (as opposed to higher-level syntactic information) in assigning a score to a given response. This paper aims to introduce the NLP community to the largest corpus currently available for short-answer scoring, provide an overview of methods used in the shared task using this data, and explore the extent to which more syntactically-informed features can contribute to the short answer scoring task in a way that avoids the question-specific manual effort of the knowledge engineering approach.