 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs getting the right answer just about choosing the right words? The role of syntactically-informed features in short answer scoring
Paper and Code
Mar 05, 2014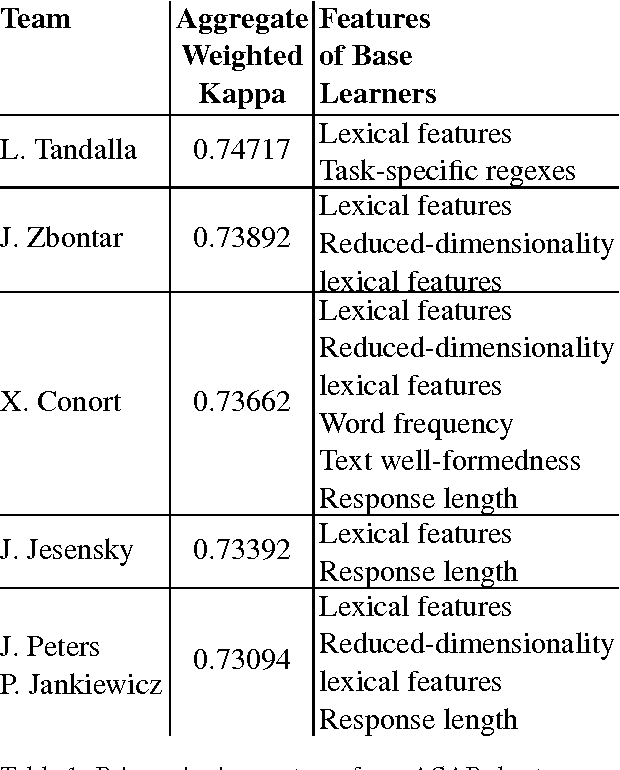
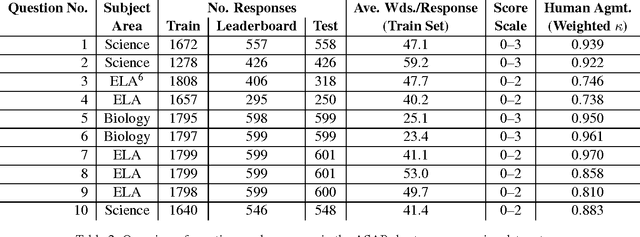
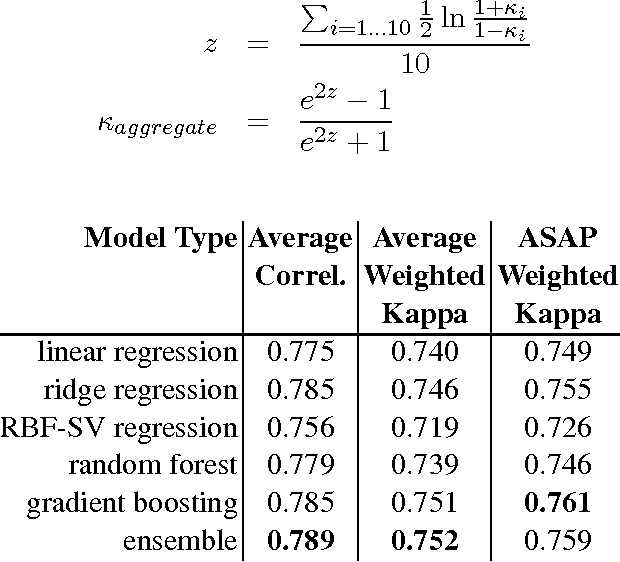
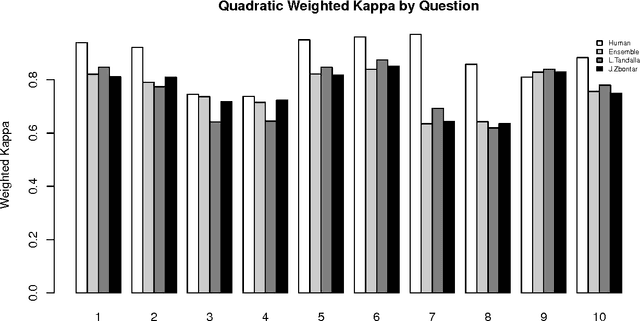
Developments in the educational landscape have spurred greater interest in the problem of automatically scoring short answer questions. A recent shared task on this topic revealed a fundamental divide in the modeling approaches that have been applied to this problem, with the best-performing systems split between those that employ a knowledge engineering approach and those that almost solely leverage lexical information (as opposed to higher-level syntactic information) in assigning a score to a given response. This paper aims to introduce the NLP community to the largest corpus currently available for short-answer scoring, provide an overview of methods used in the shared task using this data, and explore the extent to which more syntactically-informed features can contribute to the short answer scoring task in a way that avoids the question-specific manual effort of the knowledge engineering approach.