 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Conversational Quality Indicators for Improving Task-Oriented Dialog Systems
Sep 22, 2021
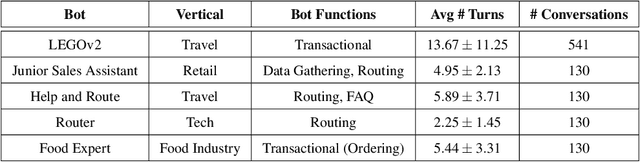
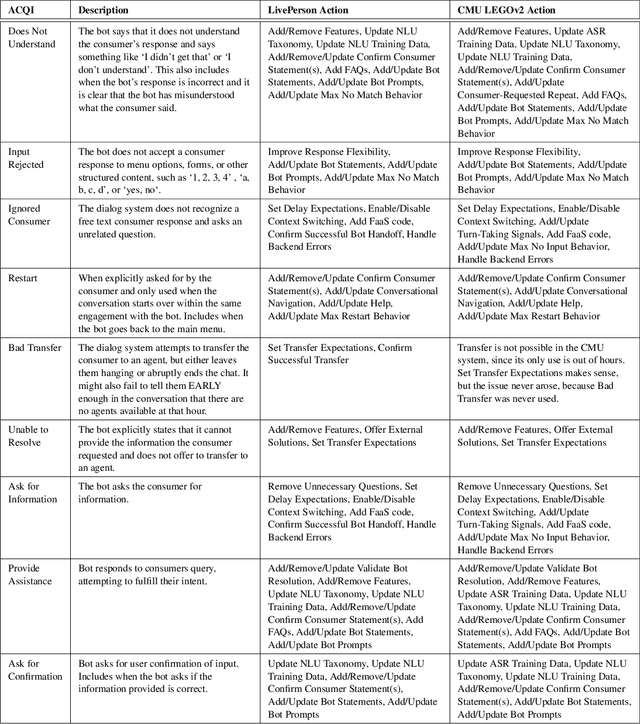

Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved, and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications, and on the publicly available CMU LEGOv2 conversational dataset (Raux et al. 2005). We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves an 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
Language Identification with a Reciprocal Rank Classifier
Sep 20, 2021
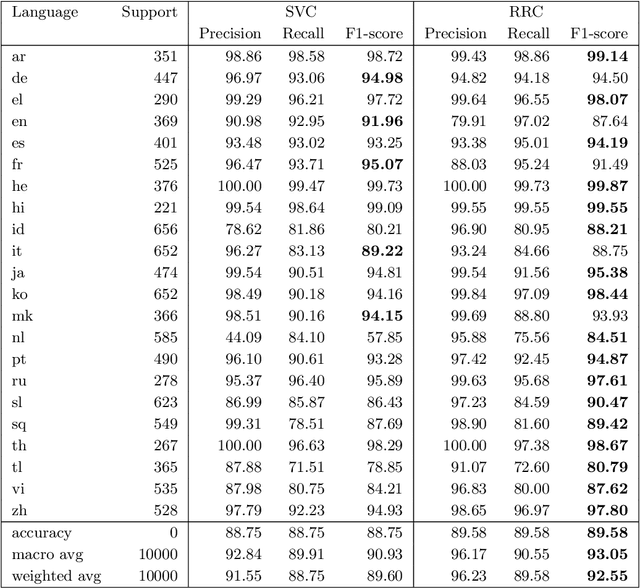
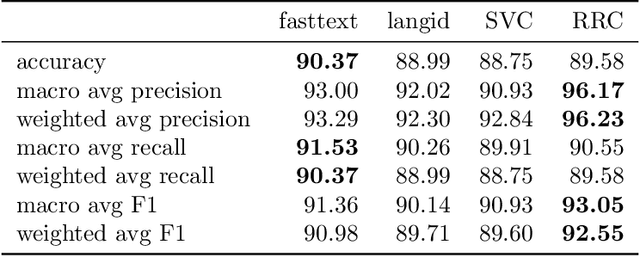
Language identification is a critical component of language processing pipelines (Jauhiainen et al.,2019) and is not a solved problem in real-world settings. We present a lightweight and effective language identifier that is robust to changes of domain and to the absence of copious training data. The key idea for classification is that the reciprocal of the rank in a frequency table makes an effective additive feature score, hence the term Reciprocal Rank Classifier (RRC). The key finding for language classification is that ranked lists of words and frequencies of characters form a sufficient and robust representation of the regularities of key languages and their orthographies. We test this on two 22-language data sets and demonstrate zero-effort domain adaptation from a Wikipedia training set to a Twitter test set. When trained on Wikipedia but applied to Twitter the macro-averaged F1-score of a conventionally trained SVM classifier drops from 90.9% to 77.7%. By contrast, the macro F1-score of RRC drops only from 93.1% to 90.6%. These classifiers are compared with those from fastText and langid. The RRC performs better than these established systems in most experiments, especially on short Wikipedia texts and Twitter. The RRC classifier can be improved for particular domains and conversational situations by adding words to the ranked lists. Using new terms learned from such conversations, we demonstrate a further 7.9% increase in accuracy of sample message classification, and 1.7% increase for conversation classification. Surprisingly, this made results on Twitter data slightly worse. The RRC classifier is available as an open source Python package (https://github.com/LivePersonInc/lplangid).
Is getting the right answer just about choosing the right words? The role of syntactically-informed features in short answer scoring
Mar 05, 2014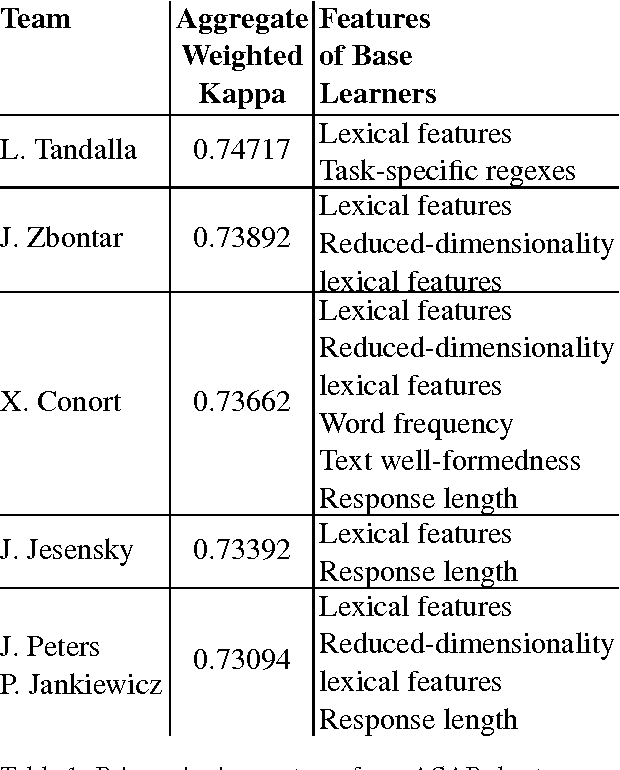
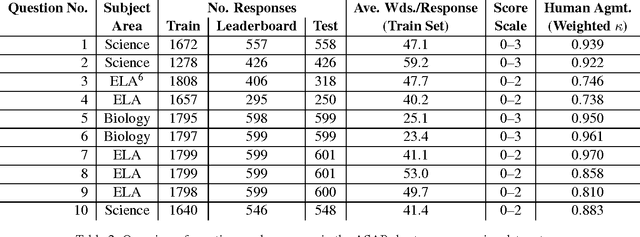
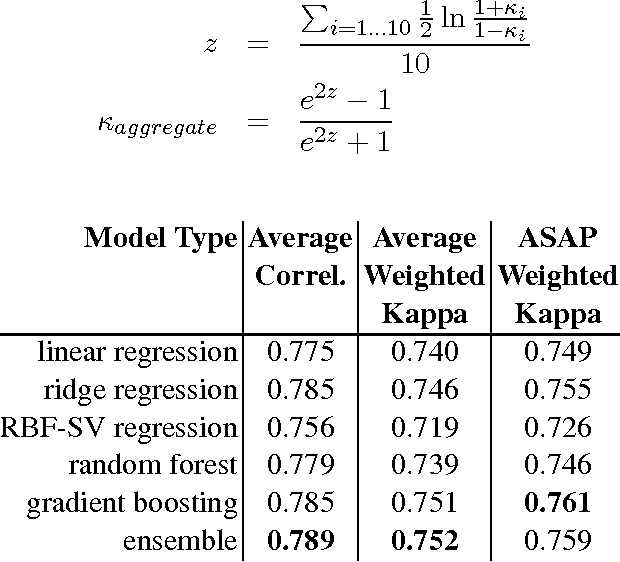
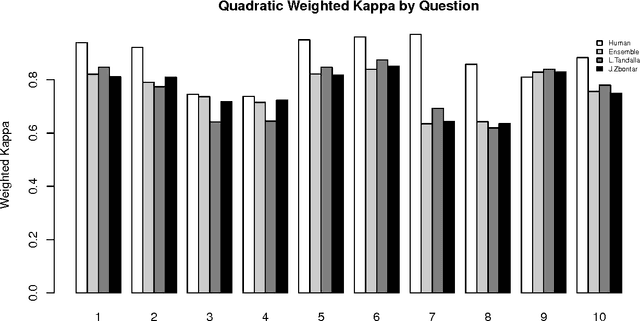
Developments in the educational landscape have spurred greater interest in the problem of automatically scoring short answer questions. A recent shared task on this topic revealed a fundamental divide in the modeling approaches that have been applied to this problem, with the best-performing systems split between those that employ a knowledge engineering approach and those that almost solely leverage lexical information (as opposed to higher-level syntactic information) in assigning a score to a given response. This paper aims to introduce the NLP community to the largest corpus currently available for short-answer scoring, provide an overview of methods used in the shared task using this data, and explore the extent to which more syntactically-informed features can contribute to the short answer scoring task in a way that avoids the question-specific manual effort of the knowledge engineering approach.
Letting the Cat out of the Bag: Generation for Shake-and-Bake MT
Nov 13, 1995


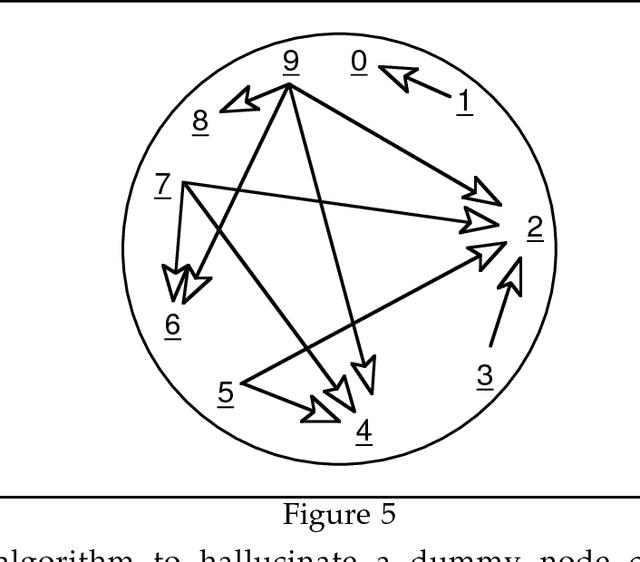
Describes an algorithm for the generation phase of a Shake-and-Bake Machine Translation system. Since the problem is NP-complete, it is unlikely that the algorithm will be efficient in all cases, but for the cases tested it offers an improvement over Whitelock's previously published algorithm. The work was carried out while the author was employed at Sharp Laboratories of Europe Ltd.
Stochastic HPSG
Feb 17, 1995In this paper we provide a probabilistic interpretation for typed feature structures very similar to those used by Pollard and Sag. We begin with a version of the interpretation which lacks a treatment of re-entrant feature structures, then provide an extended interpretation which allows them. We sketch algorithms allowing the numerical parameters of our probabilistic interpretations of HPSG to be estimated from corpora.
Priority Union and Generalization in Discourse Grammars
May 30, 1994We describe an implementation in Carpenter's typed feature formalism, ALE, of a discourse grammar of the kind proposed by Scha, Polanyi, et al. We examine their method for resolving parallelism-dependent anaphora and show that there is a coherent feature-structural rendition of this type of grammar which uses the operations of priority union and generalization. We describe an augmentation of the ALE system to encompass these operations and we show that an appropriate choice of definition for priority union gives the desired multiple output for examples of VP-ellipsis which exhibit a strict/sloppy ambiguity.
* 8 pages, Unix compressed and uuencoded Postscript file To appear in ACL-94