 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActionable Conversational Quality Indicators for Improving Task-Oriented Dialog Systems
Sep 22, 2021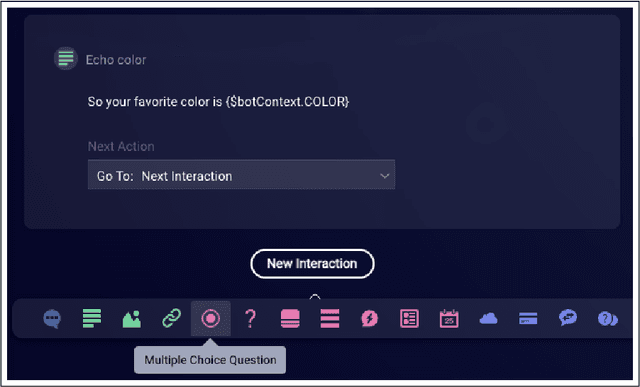
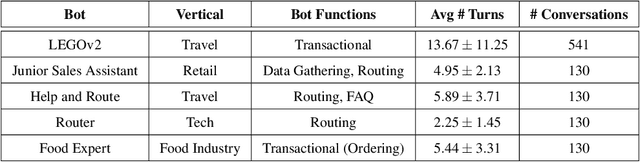
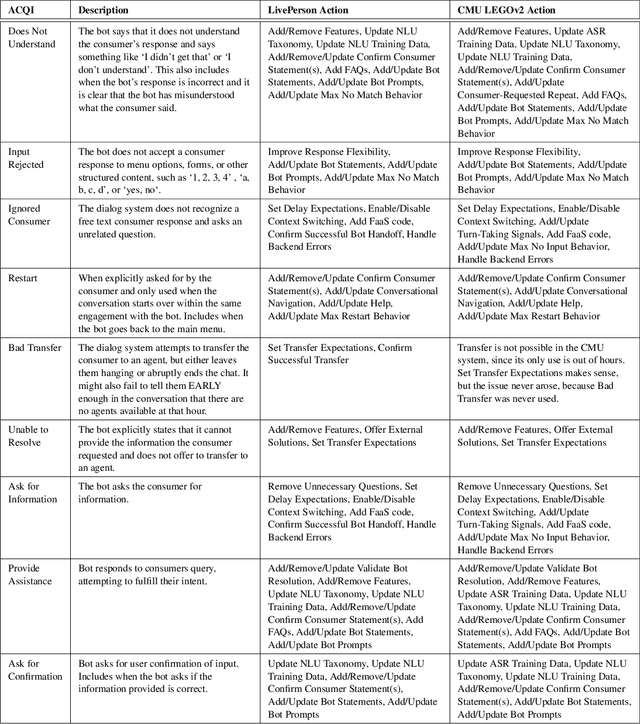

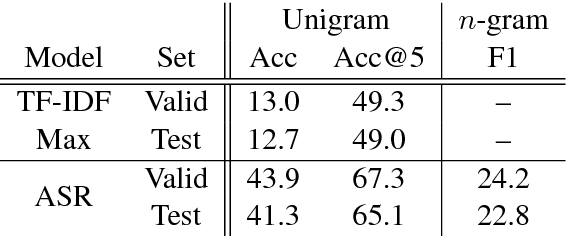
Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved, and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications, and on the publicly available CMU LEGOv2 conversational dataset (Raux et al. 2005). We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves an 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
SearchQA: A New Q&A Dataset Augmented with Context from a Search Engine
Jun 11, 2017

We publicly release a new large-scale dataset, called SearchQA, for machine comprehension, or question-answering. Unlike recently released datasets, such as DeepMind CNN/DailyMail and SQuAD, the proposed SearchQA was constructed to reflect a full pipeline of general question-answering. That is, we start not from an existing article and generate a question-answer pair, but start from an existing question-answer pair, crawled from J! Archive, and augment it with text snippets retrieved by Google. Following this approach, we built SearchQA, which consists of more than 140k question-answer pairs with each pair having 49.6 snippets on average. Each question-answer-context tuple of the SearchQA comes with additional meta-data such as the snippet's URL, which we believe will be valuable resources for future research. We conduct human evaluation as well as test two baseline methods, one simple word selection and the other deep learning based, on the SearchQA. We show that there is a meaningful gap between the human and machine performances. This suggests that the proposed dataset could well serve as a benchmark for question-answering.