 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language, AI, and Quantum Computing in 2024: Research Ingredients and Directions in QNLP
Mar 28, 2024Language processing is at the heart of current developments in artificial intelligence, and quantum computers are becoming available at the same time. This has led to great interest in quantum natural language processing, and several early proposals and experiments. This paper surveys the state of this area, showing how NLP-related techniques including word embeddings, sequential models, attention, and grammatical parsing have been used in quantum language processing. We introduce a new quantum design for the basic task of text encoding (representing a string of characters in memory), which has not been addressed in detail before. As well as motivating new technologies, quantum theory has made key contributions to the challenging questions of 'What is uncertainty?' and 'What is intelligence?' As these questions are taking on fresh urgency with artificial systems, the paper also considers some of the ways facts are conceptualized and presented in language. In particular, we argue that the problem of 'hallucinations' arises through a basic misunderstanding: language expresses any number of plausible hypotheses, only a few of which become actual, a distinction that is ignored in classical mechanics, but present (albeit confusing) in quantum mechanics.
Spatial Entity Resolution between Restaurant Locations and Transportation Destinations in Southeast Asia
Jan 16, 2024

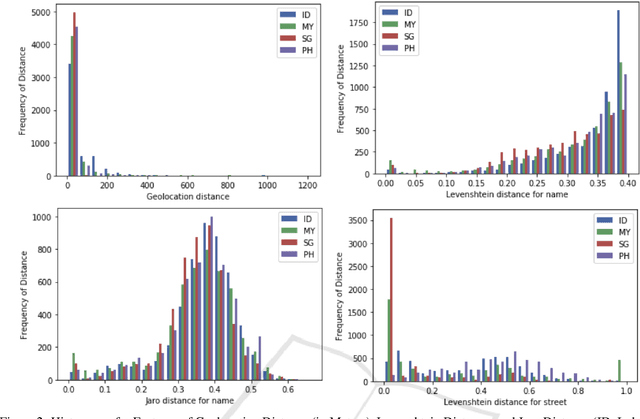
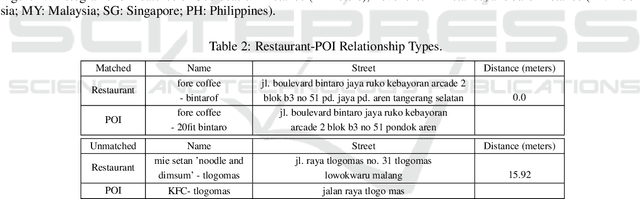
As a tech company, Grab has expanded from transportation to food delivery, aiming to serve Southeast Asia with hyperlocalized applications. Information about places as transportation destinations can help to improve our knowledge about places as restaurants, so long as the spatial entity resolution problem between these datasets can be solved. In this project, we attempted to recognize identical place entities from databases of Points-of-Interest (POI) and GrabFood restaurants, using their spatial and textual attributes, i.e., latitude, longitude, place name, and street address. Distance metrics were calculated for these attributes and fed to tree-based classifiers. POI-restaurant matching was conducted separately for Singapore, Philippines, Indonesia, and Malaysia. Experimental estimates demonstrate that a matching POI can be found for over 35% of restaurants in these countries. As part of these estimates, test datasets were manually created, and RandomForest, AdaBoost, Gradient Boosting, and XGBoost perform well, with most accuracy, precision, and recall scores close to or higher than 90% for matched vs. unmatched classification. To the authors' knowledge, there are no previous published scientific papers devoted to matching of spatial entities for the Southeast Asia region.
Quantum Circuit Components for Cognitive Decision-Making
Feb 06, 2023



Since the 1990's, many observed cognitive behaviors have been shown to violate rules based on classical probability and set theory. For example, the order in which questions are posed affects whether participants answer 'yes' or 'no', so the population that answers 'yes' to both questions cannot be modeled as the intersection of two fixed sets. It can however be modeled as a sequence of projections carried out in different orders. This and other examples have been described successfully using quantum probability, which relies on comparing angles between subspaces rather than volumes between subsets. Now in the early 2020's, quantum computers have reached the point where some of these quantum cognitive models can be implemented and investigated on quantum hardware, representing the mental states in qubit registers, and the cognitive operations and decisions using different gates and measurements. This paper develops such quantum circuit representations for quantum cognitive models, focusing particularly on modeling order effects and decision-making under uncertainty. The claim is not that the human brain uses qubits and quantum circuits explicitly (just like the use of Boolean set theory does not require the brain to be using classical bits), but that the mathematics shared between quantum cognition and quantum computing motivates the exploration of quantum computers for cognition modelling. Key quantum properties include superposition, entanglement, and collapse, as these mathematical elements provide a common language between cognitive models, quantum hardware, and circuit implementations.
Near-Term Advances in Quantum Natural Language Processing
Jun 05, 2022
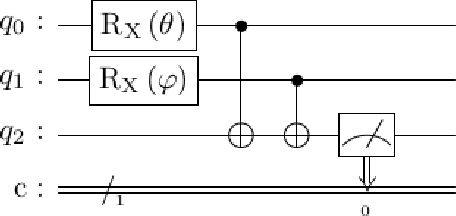
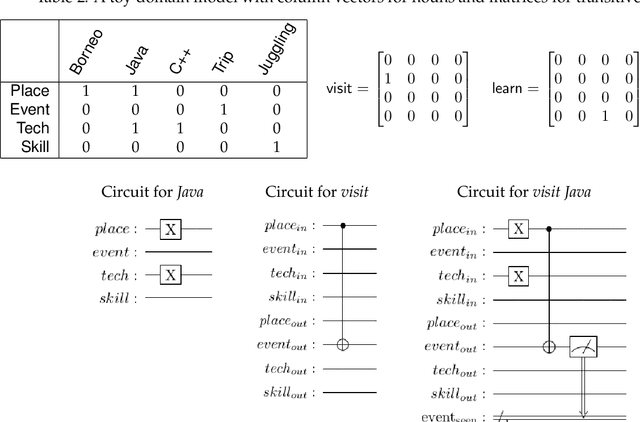
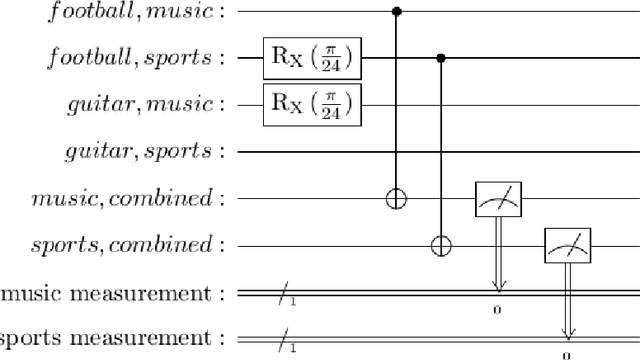
This paper describes experiments showing that some problems in natural language processing can already be addressed using quantum computers. The examples presented here include topic classification using both a quantum support vector machine and a bag-of-words approach, bigram modeling that can be applied to sequences of words and formal concepts, and ambiguity resolution in verb-noun composition. While the datasets used are still small, the systems described have been run on physical quantum computers. These implementations and their results are described along with the algorithms and mathematical approaches used.
Actionable Conversational Quality Indicators for Improving Task-Oriented Dialog Systems
Sep 22, 2021
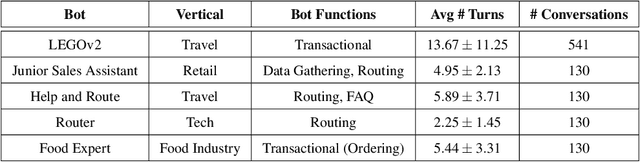
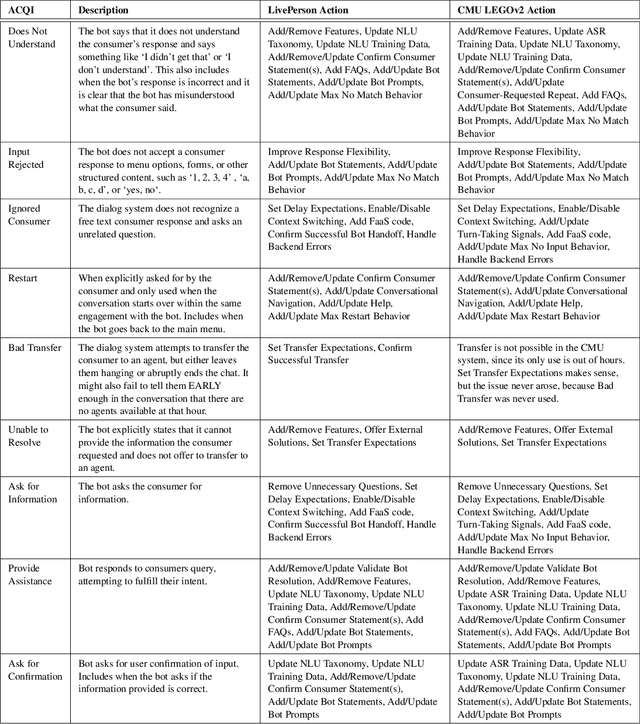

Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved, and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications, and on the publicly available CMU LEGOv2 conversational dataset (Raux et al. 2005). We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves an 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
Language Identification with a Reciprocal Rank Classifier
Sep 20, 2021
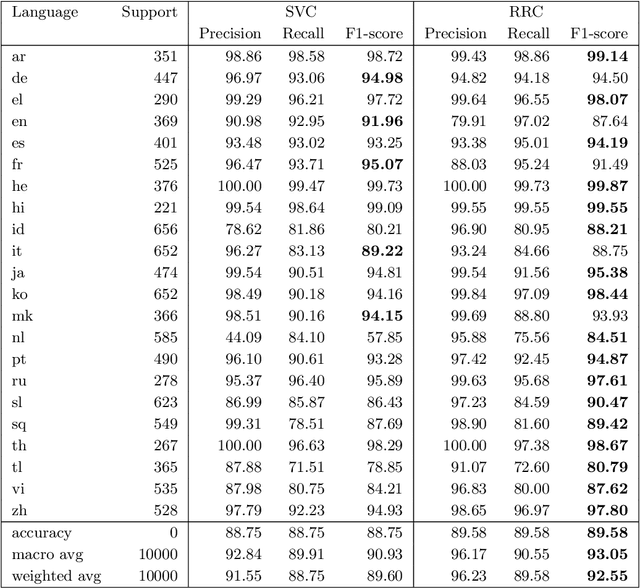
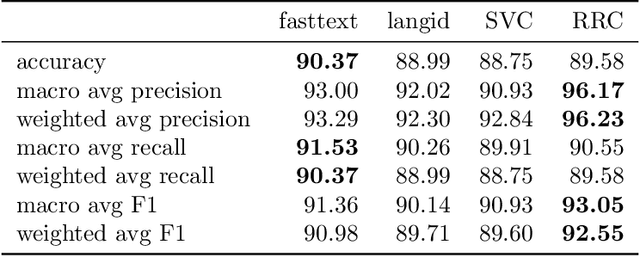
Language identification is a critical component of language processing pipelines (Jauhiainen et al.,2019) and is not a solved problem in real-world settings. We present a lightweight and effective language identifier that is robust to changes of domain and to the absence of copious training data. The key idea for classification is that the reciprocal of the rank in a frequency table makes an effective additive feature score, hence the term Reciprocal Rank Classifier (RRC). The key finding for language classification is that ranked lists of words and frequencies of characters form a sufficient and robust representation of the regularities of key languages and their orthographies. We test this on two 22-language data sets and demonstrate zero-effort domain adaptation from a Wikipedia training set to a Twitter test set. When trained on Wikipedia but applied to Twitter the macro-averaged F1-score of a conventionally trained SVM classifier drops from 90.9% to 77.7%. By contrast, the macro F1-score of RRC drops only from 93.1% to 90.6%. These classifiers are compared with those from fastText and langid. The RRC performs better than these established systems in most experiments, especially on short Wikipedia texts and Twitter. The RRC classifier can be improved for particular domains and conversational situations by adding words to the ranked lists. Using new terms learned from such conversations, we demonstrate a further 7.9% increase in accuracy of sample message classification, and 1.7% increase for conversation classification. Surprisingly, this made results on Twitter data slightly worse. The RRC classifier is available as an open source Python package (https://github.com/LivePersonInc/lplangid).
Should Semantic Vector Composition be Explicit? Can it be Linear?
May 11, 2021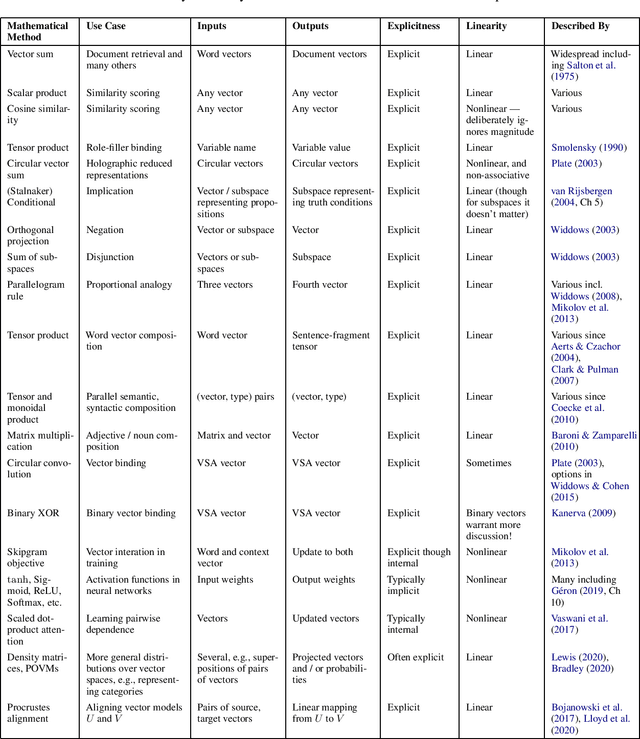
Vector representations have become a central element in semantic language modelling, leading to mathematical overlaps with many fields including quantum theory. Compositionality is a core goal for such representations: given representations for 'wet' and 'fish', how should the concept 'wet fish' be represented? This position paper surveys this question from two points of view. The first considers the question of whether an explicit mathematical representation can be successful using only tools from within linear algebra, or whether other mathematical tools are needed. The second considers whether semantic vector composition should be explicitly described mathematically, or whether it can be a model-internal side-effect of training a neural network. A third and newer question is whether a compositional model can be implemented on a quantum computer. Given the fundamentally linear nature of quantum mechanics, we propose that these questions are related, and that this survey may help to highlight candidate operations for future quantum implementation.
Quantum Mathematics in Artificial Intelligence
Feb 01, 2021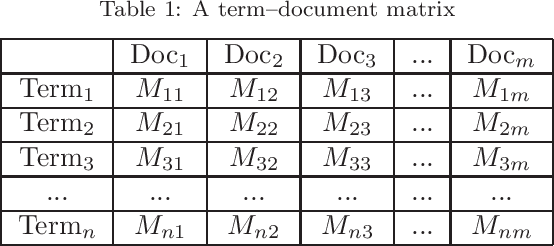
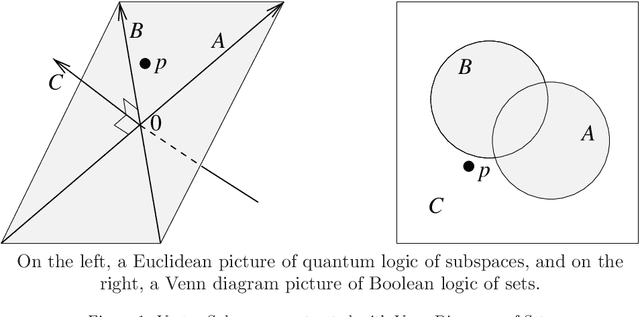
In the decade since 2010, successes in artificial intelligence have been at the forefront of computer science and technology, and vector space models have solidified a position at the forefront of artificial intelligence. At the same time, quantum computers have become much more powerful, and announcements of major advances are frequently in the news. The mathematical techniques underlying both these areas have more in common than is sometimes realized. Vector spaces took a position at the axiomatic heart of quantum mechanics in the 1930s, and this adoption was a key motivation for the derivation of logic and probability from the linear geometry of vector spaces. Quantum interactions between particles are modelled using the tensor product, which is also used to express objects and operations in artificial neural networks. This paper describes some of these common mathematical areas, including examples of how they are used in artificial intelligence (AI), particularly in automated reasoning and natural language processing (NLP). Techniques discussed include vector spaces, scalar products, subspaces and implication, orthogonal projection and negation, dual vectors, density matrices, positive operators, and tensor products. Application areas include information retrieval, categorization and implication, modelling word-senses and disambiguation, inference in knowledge bases, and semantic composition. Some of these approaches can potentially be implemented on quantum hardware. Many of the practical steps in this implementation are in early stages, and some are already realized. Explaining some of the common mathematical tools can help researchers in both AI and quantum computing further exploit these overlaps, recognizing and exploring new directions along the way.