 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe economic trade-offs of large language models: A case study
Jun 08, 2023Contacting customer service via chat is a common practice. Because employing customer service agents is expensive, many companies are turning to NLP that assists human agents by auto-generating responses that can be used directly or with modifications. Large Language Models (LLMs) are a natural fit for this use case; however, their efficacy must be balanced with the cost of training and serving them. This paper assesses the practical cost and impact of LLMs for the enterprise as a function of the usefulness of the responses that they generate. We present a cost framework for evaluating an NLP model's utility for this use case and apply it to a single brand as a case study in the context of an existing agent assistance product. We compare three strategies for specializing an LLM - prompt engineering, fine-tuning, and knowledge distillation - using feedback from the brand's customer service agents. We find that the usability of a model's responses can make up for a large difference in inference cost for our case study brand, and we extrapolate our findings to the broader enterprise space.
Behind the Mask: Demographic bias in name detection for PII masking
May 09, 2022
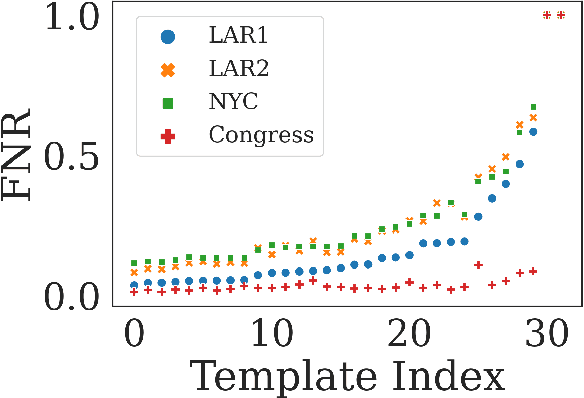
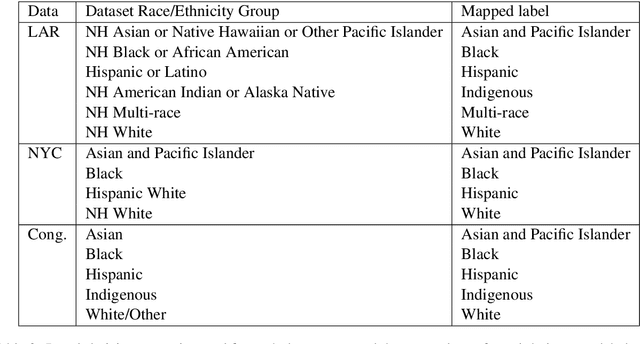
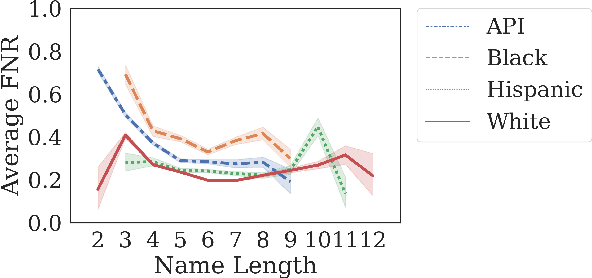
Many datasets contain personally identifiable information, or PII, which poses privacy risks to individuals. PII masking is commonly used to redact personal information such as names, addresses, and phone numbers from text data. Most modern PII masking pipelines involve machine learning algorithms. However, these systems may vary in performance, such that individuals from particular demographic groups bear a higher risk for having their personal information exposed. In this paper, we evaluate the performance of three off-the-shelf PII masking systems on name detection and redaction. We generate data using names and templates from the customer service domain. We find that an open-source RoBERTa-based system shows fewer disparities than the commercial models we test. However, all systems demonstrate significant differences in error rate based on demographics. In particular, the highest error rates occurred for names associated with Black and Asian/Pacific Islander individuals.
Actionable Conversational Quality Indicators for Improving Task-Oriented Dialog Systems
Sep 22, 2021
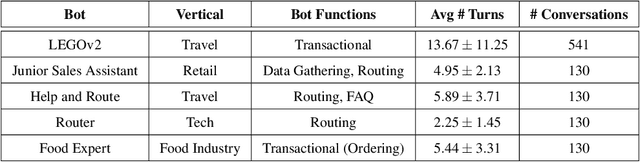
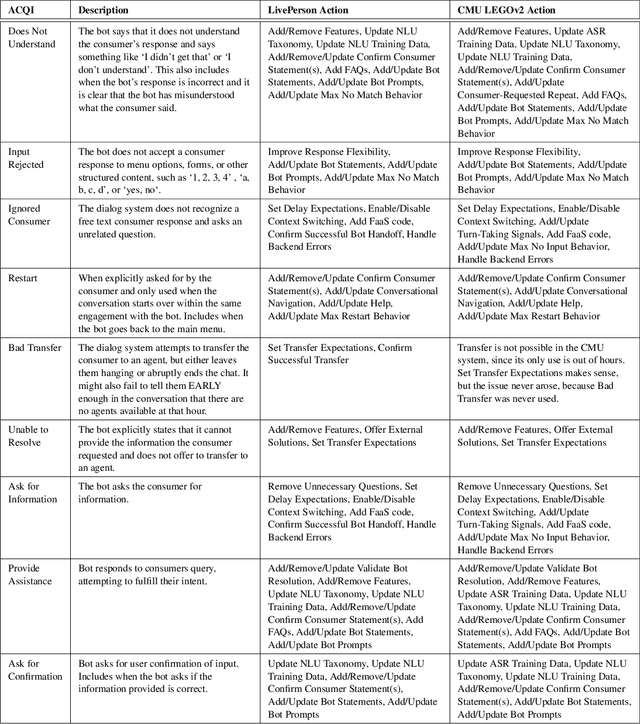

Automatic dialog systems have become a mainstream part of online customer service. Many such systems are built, maintained, and improved by customer service specialists, rather than dialog systems engineers and computer programmers. As conversations between people and machines become commonplace, it is critical to understand what is working, what is not, and what actions can be taken to reduce the frequency of inappropriate system responses. These analyses and recommendations need to be presented in terms that directly reflect the user experience rather than the internal dialog processing. This paper introduces and explains the use of Actionable Conversational Quality Indicators (ACQIs), which are used both to recognize parts of dialogs that can be improved, and to recommend how to improve them. This combines benefits of previous approaches, some of which have focused on producing dialog quality scoring while others have sought to categorize the types of errors the dialog system is making. We demonstrate the effectiveness of using ACQIs on LivePerson internal dialog systems used in commercial customer service applications, and on the publicly available CMU LEGOv2 conversational dataset (Raux et al. 2005). We report on the annotation and analysis of conversational datasets showing which ACQIs are important to fix in various situations. The annotated datasets are then used to build a predictive model which uses a turn-based vector embedding of the message texts and achieves an 79% weighted average f1-measure at the task of finding the correct ACQI for a given conversation. We predict that if such a model worked perfectly, the range of potential improvement actions a bot-builder must consider at each turn could be reduced by an average of 81%.
Should Semantic Vector Composition be Explicit? Can it be Linear?
May 11, 2021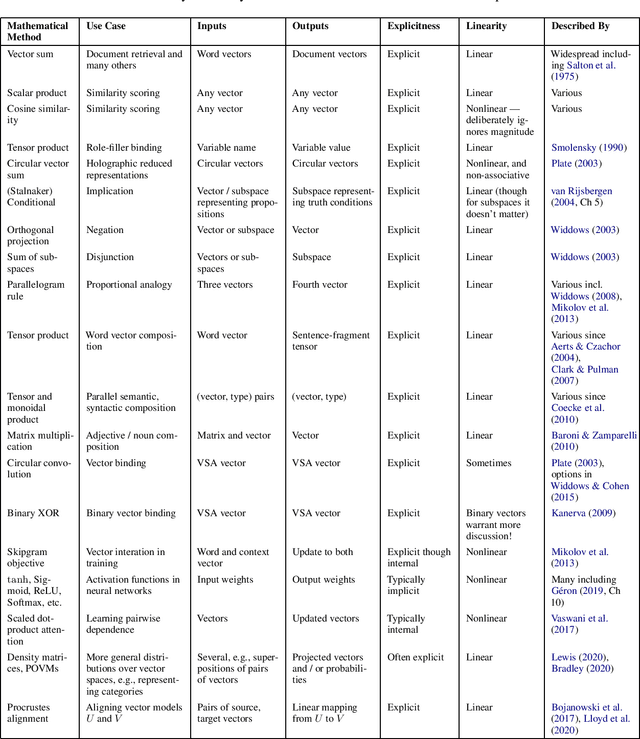
Vector representations have become a central element in semantic language modelling, leading to mathematical overlaps with many fields including quantum theory. Compositionality is a core goal for such representations: given representations for 'wet' and 'fish', how should the concept 'wet fish' be represented? This position paper surveys this question from two points of view. The first considers the question of whether an explicit mathematical representation can be successful using only tools from within linear algebra, or whether other mathematical tools are needed. The second considers whether semantic vector composition should be explicitly described mathematically, or whether it can be a model-internal side-effect of training a neural network. A third and newer question is whether a compositional model can be implemented on a quantum computer. Given the fundamentally linear nature of quantum mechanics, we propose that these questions are related, and that this survey may help to highlight candidate operations for future quantum implementation.