 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe economic trade-offs of large language models: A case study
Jun 08, 2023



Contacting customer service via chat is a common practice. Because employing customer service agents is expensive, many companies are turning to NLP that assists human agents by auto-generating responses that can be used directly or with modifications. Large Language Models (LLMs) are a natural fit for this use case; however, their efficacy must be balanced with the cost of training and serving them. This paper assesses the practical cost and impact of LLMs for the enterprise as a function of the usefulness of the responses that they generate. We present a cost framework for evaluating an NLP model's utility for this use case and apply it to a single brand as a case study in the context of an existing agent assistance product. We compare three strategies for specializing an LLM - prompt engineering, fine-tuning, and knowledge distillation - using feedback from the brand's customer service agents. We find that the usability of a model's responses can make up for a large difference in inference cost for our case study brand, and we extrapolate our findings to the broader enterprise space.
MLlib: Machine Learning in Apache Spark
May 26, 2015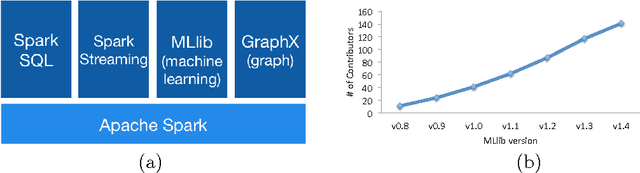
Apache Spark is a popular open-source platform for large-scale data processing that is well-suited for iterative machine learning tasks. In this paper we present MLlib, Spark's open-source distributed machine learning library. MLlib provides efficient functionality for a wide range of learning settings and includes several underlying statistical, optimization, and linear algebra primitives. Shipped with Spark, MLlib supports several languages and provides a high-level API that leverages Spark's rich ecosystem to simplify the development of end-to-end machine learning pipelines. MLlib has experienced a rapid growth due to its vibrant open-source community of over 140 contributors, and includes extensive documentation to support further growth and to let users quickly get up to speed.
Estimation from Pairwise Comparisons: Sharp Minimax Bounds with Topology Dependence
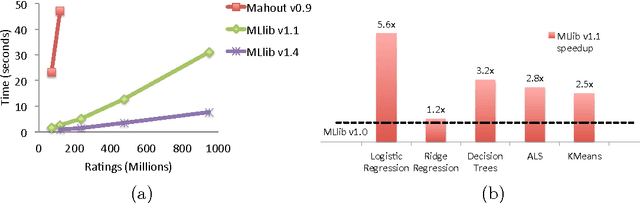
May 06, 2015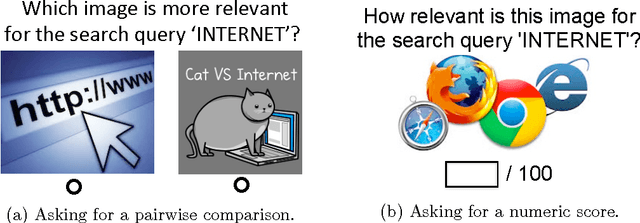
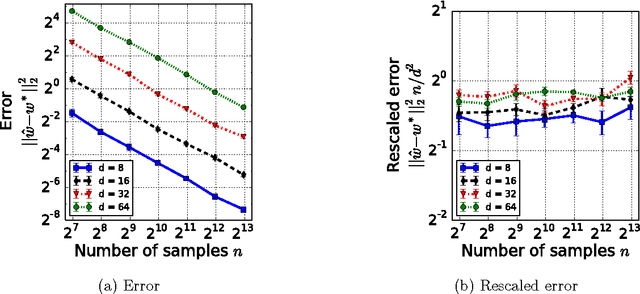

Data in the form of pairwise comparisons arises in many domains, including preference elicitation, sporting competitions, and peer grading among others. We consider parametric ordinal models for such pairwise comparison data involving a latent vector $w^* \in \mathbb{R}^d$ that represents the "qualities" of the $d$ items being compared; this class of models includes the two most widely used parametric models--the Bradley-Terry-Luce (BTL) and the Thurstone models. Working within a standard minimax framework, we provide tight upper and lower bounds on the optimal error in estimating the quality score vector $w^*$ under this class of models. The bounds depend on the topology of the comparison graph induced by the subset of pairs being compared via its Laplacian spectrum. Thus, in settings where the subset of pairs may be chosen, our results provide principled guidelines for making this choice. Finally, we compare these error rates to those under cardinal measurement models and show that the error rates in the ordinal and cardinal settings have identical scalings apart from constant pre-factors.
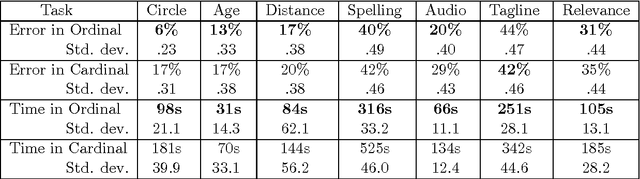
When is it Better to Compare than to Score?
Jun 25, 2014

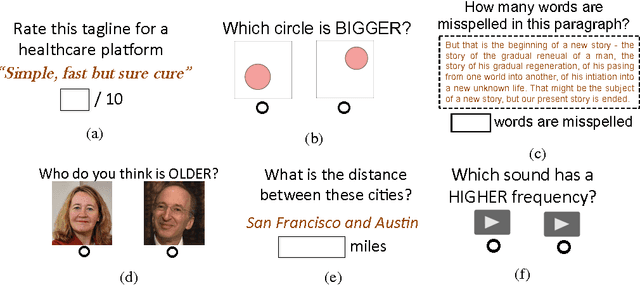

When eliciting judgements from humans for an unknown quantity, one often has the choice of making direct-scoring (cardinal) or comparative (ordinal) measurements. In this paper we study the relative merits of either choice, providing empirical and theoretical guidelines for the selection of a measurement scheme. We provide empirical evidence based on experiments on Amazon Mechanical Turk that in a variety of tasks, (pairwise-comparative) ordinal measurements have lower per sample noise and are typically faster to elicit than cardinal ones. Ordinal measurements however typically provide less information. We then consider the popular Thurstone and Bradley-Terry-Luce (BTL) models for ordinal measurements and characterize the minimax error rates for estimating the unknown quantity. We compare these minimax error rates to those under cardinal measurement models and quantify for what noise levels ordinal measurements are better. Finally, we revisit the data collected from our experiments and show that fitting these models confirms this prediction: for tasks where the noise in ordinal measurements is sufficiently low, the ordinal approach results in smaller errors in the estimation.