 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTILT: Target-induced loss tilting under covariate shift
May 14, 2026We introduce and analyze Target-Induced Loss Tilting (TILT) for unsupervised domain adaptation under covariate shift. It is based on a novel objective function that decomposes the source predictor as $f+b$, fits $f+b$ on labeled source data while simultaneously penalizing the auxiliary component $b$ on unlabeled target inputs. The resulting fit $f$ is deployed as the final target predictor. At the population level, we show that this target-side penalty implicitly induces relative importance weighting at the population level, but in terms of an estimand $b^*_f$ that is self-localized to the current error, and remains uniformly bounded for any source-target pair (even those with disjoint supports). We prove a general finite-sample oracle inequality on the excess risk, and use it to give an end-to-end guarantee for training with sparse ReLU networks. Experiments on controlled regression problems and shifted CIFAR-100 distillation show that TILT improves target-domain performance over source-only training, exact importance weighting, and relative density-ratio baselines, with a stable dependence on the regularization parameter.
Residual-as-Teacher: Mitigating Bias Propagation in Student--Teacher Estimation
Mar 26, 2026We study statistical estimation in a student--teacher setting, where predictions from a pre-trained teacher are used to guide a student model. A standard approach is to train the student to directly match the teacher's outputs, which we refer to as student soft matching (SM). This approach directly propagates any systematic bias or mis-specification present in the teacher, thereby degrading the student's predictions. We propose and analyze an alternative scheme, known as residual-as-teacher (RaT), in which the teacher is used to estimate residuals in the student's predictions. Our analysis shows how the student can thereby emulate a proximal gradient scheme for solving an oracle optimization problem, and this provably reduces the effect of teacher bias. For general student--teacher pairs, we establish non-asymptotic excess risk bounds for any RaT fixed point, along with convergence guarantees for the student-teacher iterative scheme. For kernel-based student--teacher pairs, we prove a sharp separation: the RaT method achieves the minimax-optimal rate, while the SM method incurs constant prediction error for any sample size. Experiments on both synthetic data and ImageNette classification under covariate shift corroborate our theoretical findings.
Wild refitting for black box prediction
Jun 26, 2025We describe and analyze a computionally efficient refitting procedure for computing high-probability upper bounds on the instance-wise mean-squared prediction error of penalized nonparametric estimates based on least-squares minimization. Requiring only a single dataset and black box access to the prediction method, it consists of three steps: computing suitable residuals, symmetrizing and scaling them with a pre-factor $\rho$, and using them to define and solve a modified prediction problem recentered at the current estimate. We refer to it as wild refitting, since it uses Rademacher residual symmetrization as in a wild bootstrap variant. Under relatively mild conditions allowing for noise heterogeneity, we establish a high probability guarantee on its performance, showing that the wild refit with a suitably chosen wild noise scale $\rho$ gives an upper bound on prediction error. This theoretical analysis provides guidance into the design of such procedures, including how the residuals should be formed, the amount of noise rescaling in the wild sub-problem needed for upper bounds, and the local stability properties of the block-box procedure. We illustrate the applicability of this procedure to various problems, including non-rigid structure-from-motion recovery with structured matrix penalties; plug-and-play image restoration with deep neural network priors; and randomized sketching with kernel methods.
Sharp Results for Hypothesis Testing with Risk-Sensitive Agents
Dec 21, 2024Statistical protocols are often used for decision-making involving multiple parties, each with their own incentives, private information, and ability to influence the distributional properties of the data. We study a game-theoretic version of hypothesis testing in which a statistician, also known as a principal, interacts with strategic agents that can generate data. The statistician seeks to design a testing protocol with controlled error, while the data-generating agents, guided by their utility and prior information, choose whether or not to opt in based on expected utility maximization. This strategic behavior affects the data observed by the statistician and, consequently, the associated testing error. We analyze this problem for general concave and monotonic utility functions and prove an upper bound on the Bayes false discovery rate (FDR). Underlying this bound is a form of prior elicitation: we show how an agent's choice to opt in implies a certain upper bound on their prior null probability. Our FDR bound is unimprovable in a strong sense, achieving equality at a single point for an individual agent and at any countable number of points for a population of agents. We also demonstrate that our testing protocols exhibit a desirable maximin property when the principal's utility is considered. To illustrate the qualitative predictions of our theory, we examine the effects of risk aversion, reward stochasticity, and signal-to-noise ratio, as well as the implications for the Food and Drug Administration's testing protocols.
Exploiting Exogenous Structure for Sample-Efficient Reinforcement Learning
Sep 22, 2024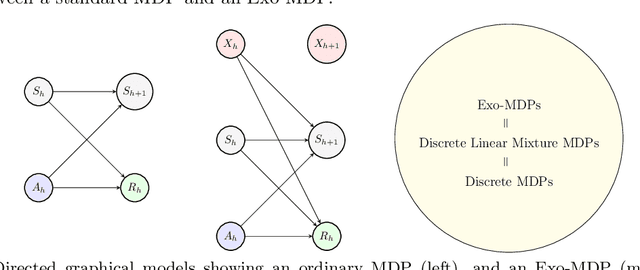
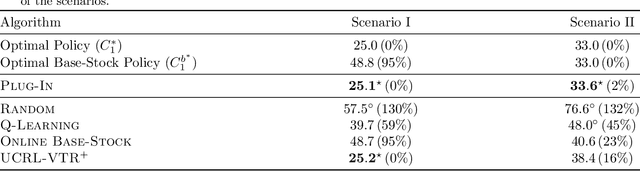
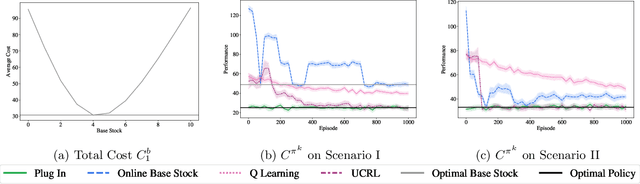
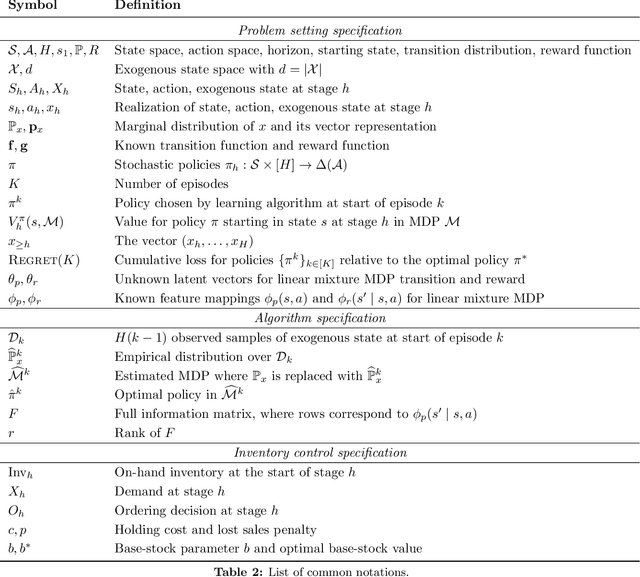
We study a class of structured Markov Decision Processes (MDPs) known as Exo-MDPs, characterized by a partition of the state space into two components. The exogenous states evolve stochastically in a manner not affected by the agent's actions, whereas the endogenous states are affected by the actions, and evolve in a deterministic and known way conditional on the exogenous states. Exo-MDPs are a natural model for various applications including inventory control, finance, power systems, ride sharing, among others. Despite seeming restrictive, this work establishes that any discrete MDP can be represented as an Exo-MDP. Further, Exo-MDPs induce a natural representation of the transition and reward dynamics as linear functions of the exogenous state distribution. This linear representation leads to near-optimal algorithms with regret guarantees scaling only with the (effective) size of the exogenous state space $d$, independent of the sizes of the endogenous state and action spaces. Specifically, when the exogenous state is fully observed, a simple plug-in approach achieves a regret upper bound of $O(H^{3/2}\sqrt{dK})$, where $H$ denotes the horizon and $K$ denotes the total number of episodes. When the exogenous state is unobserved, the linear representation leads to a regret upper bound of $O(H^{3/2}d\sqrt{K})$. We also establish a nearly matching regret lower bound of $\Omega(Hd\sqrt{K})$ for the no observation regime. We complement our theoretical findings with an experimental study on inventory control problems.
Finite-Sample Guarantees for Best-Response Learning Dynamics in Zero-Sum Matrix Games
Jul 29, 2024We study best-response type learning dynamics for two player zero-sum matrix games. We consider two settings that are distinguished by the type of information that each player has about the game and their opponent's strategy. The first setting is the full information case, in which each player knows their own and the opponent's payoff matrices and observes the opponent's mixed strategy. The second setting is the minimal information case, where players do not observe the opponent's strategy and are not aware of either of the payoff matrices (instead they only observe their realized payoffs). For this setting, also known as the radically uncoupled case in the learning in games literature, we study a two-timescale learning dynamics that combine smoothed best-response type updates for strategy estimates with a TD-learning update to estimate a local payoff function. For these dynamics, without additional exploration, we provide polynomial-time finite-sample guarantees for convergence to an $\epsilon$-Nash equilibrium.
Entrywise Inference for Causal Panel Data: A Simple and Instance-Optimal Approach
Jan 24, 2024



In causal inference with panel data under staggered adoption, the goal is to estimate and derive confidence intervals for potential outcomes and treatment effects. We propose a computationally efficient procedure, involving only simple matrix algebra and singular value decomposition. We derive non-asymptotic bounds on the entrywise error, establishing its proximity to a suitably scaled Gaussian variable. Despite its simplicity, our procedure turns out to be instance-optimal, in that our theoretical scaling matches a local instance-wise lower bound derived via a Bayesian Cram\'{e}r-Rao argument. Using our insights, we develop a data-driven procedure for constructing entrywise confidence intervals with pre-specified coverage guarantees. Our analysis is based on a general inferential toolbox for the SVD algorithm applied to the matrix denoising model, which might be of independent interest.
Taming "data-hungry" reinforcement learning? Stability in continuous state-action spaces
Jan 10, 2024We introduce a novel framework for analyzing reinforcement learning (RL) in continuous state-action spaces, and use it to prove fast rates of convergence in both off-line and on-line settings. Our analysis highlights two key stability properties, relating to how changes in value functions and/or policies affect the Bellman operator and occupation measures. We argue that these properties are satisfied in many continuous state-action Markov decision processes, and demonstrate how they arise naturally when using linear function approximation methods. Our analysis offers fresh perspectives on the roles of pessimism and optimism in off-line and on-line RL, and highlights the connection between off-line RL and transfer learning.
Doubly High-Dimensional Contextual Bandits: An Interpretable Model for Joint Assortment-Pricing
Sep 14, 2023



Key challenges in running a retail business include how to select products to present to consumers (the assortment problem), and how to price products (the pricing problem) to maximize revenue or profit. Instead of considering these problems in isolation, we propose a joint approach to assortment-pricing based on contextual bandits. Our model is doubly high-dimensional, in that both context vectors and actions are allowed to take values in high-dimensional spaces. In order to circumvent the curse of dimensionality, we propose a simple yet flexible model that captures the interactions between covariates and actions via a (near) low-rank representation matrix. The resulting class of models is reasonably expressive while remaining interpretable through latent factors, and includes various structured linear bandit and pricing models as particular cases. We propose a computationally tractable procedure that combines an exploration/exploitation protocol with an efficient low-rank matrix estimator, and we prove bounds on its regret. Simulation results show that this method has lower regret than state-of-the-art methods applied to various standard bandit and pricing models. Real-world case studies on the assortment-pricing problem, from an industry-leading instant noodles company to an emerging beauty start-up, underscore the gains achievable using our method. In each case, we show at least three-fold gains in revenue or profit by our bandit method, as well as the interpretability of the latent factor models that are learned.
Semi-parametric inference based on adaptively collected data
Mar 05, 2023Many standard estimators, when applied to adaptively collected data, fail to be asymptotically normal, thereby complicating the construction of confidence intervals. We address this challenge in a semi-parametric context: estimating the parameter vector of a generalized linear regression model contaminated by a non-parametric nuisance component. We construct suitably weighted estimating equations that account for adaptivity in data collection, and provide conditions under which the associated estimates are asymptotically normal. Our results characterize the degree of "explorability" required for asymptotic normality to hold. For the simpler problem of estimating a linear functional, we provide similar guarantees under much weaker assumptions. We illustrate our general theory with concrete consequences for various problems, including standard linear bandits and sparse generalized bandits, and compare with other methods via simulation studies.