 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Efficient Online Exploration for Reinforcement Learning with Human Feedback
Sep 26, 2025Reinforcement learning with human feedback (RLHF), which learns a reward model from human preference data and then optimizes a policy to favor preferred responses, has emerged as a central paradigm for aligning large language models (LLMs) with human preferences. In this paper, we investigate exploration principles for online RLHF, where one seeks to adaptively collect new preference data to refine both the reward model and the policy in a data-efficient manner. By examining existing optimism-based exploration algorithms, we identify a drawback in their sampling protocol: they tend to gather comparisons that fail to reduce the most informative uncertainties in reward differences, and we prove lower bounds showing that such methods can incur linear regret over exponentially long horizons. Motivated by this insight, we propose a new exploration scheme that directs preference queries toward reducing uncertainty in reward differences most relevant to policy improvement. Under a multi-armed bandit model of RLHF, we establish regret bounds of order $T^{(\beta+1)/(\beta+2)}$, where $\beta>0$ is a hyperparameter that balances reward maximization against mitigating distribution shift. To our knowledge, this is the first online RLHF algorithm with regret scaling polynomially in all model parameters.
Gaussian mixture layers for neural networks
Aug 06, 2025The mean-field theory for two-layer neural networks considers infinitely wide networks that are linearly parameterized by a probability measure over the parameter space. This nonparametric perspective has significantly advanced both the theoretical and conceptual understanding of neural networks, with substantial efforts made to validate its applicability to networks of moderate width. In this work, we explore the opposite direction, investigating whether dynamics can be directly implemented over probability measures. Specifically, we employ Gaussian mixture models as a flexible and expressive parametric family of distributions together with the theory of Wasserstein gradient flows to derive training dynamics for such measures. Our approach introduces a new type of layer -- the Gaussian mixture (GM) layer -- that can be integrated into neural network architectures. As a proof of concept, we validate our proposal through experiments on simple classification tasks, where a GM layer achieves test performance comparable to that of a two-layer fully connected network. Furthermore, we examine the behavior of these dynamics and demonstrate numerically that GM layers exhibit markedly different behavior compared to classical fully connected layers, even when the latter are large enough to be considered in the mean-field regime.
Adaptivity and Convergence of Probability Flow ODEs in Diffusion Generative Models
Jan 31, 2025Score-based generative models, which transform noise into data by learning to reverse a diffusion process, have become a cornerstone of modern generative AI. This paper contributes to establishing theoretical guarantees for the probability flow ODE, a widely used diffusion-based sampler known for its practical efficiency. While a number of prior works address its general convergence theory, it remains unclear whether the probability flow ODE sampler can adapt to the low-dimensional structures commonly present in natural image data. We demonstrate that, with accurate score function estimation, the probability flow ODE sampler achieves a convergence rate of $O(k/T)$ in total variation distance (ignoring logarithmic factors), where $k$ is the intrinsic dimension of the target distribution and $T$ is the number of iterations. This dimension-free convergence rate improves upon existing results that scale with the typically much larger ambient dimension, highlighting the ability of the probability flow ODE sampler to exploit intrinsic low-dimensional structures in the target distribution for faster sampling.
$O(d/T)$ Convergence Theory for Diffusion Probabilistic Models under Minimal Assumptions
Sep 27, 2024

Score-based diffusion models, which generate new data by learning to reverse a diffusion process that perturbs data from the target distribution into noise, have achieved remarkable success across various generative tasks. Despite their superior empirical performance, existing theoretical guarantees are often constrained by stringent assumptions or suboptimal convergence rates. In this paper, we establish a fast convergence theory for a popular SDE-based sampler under minimal assumptions. Our analysis shows that, provided $\ell_{2}$-accurate estimates of the score functions, the total variation distance between the target and generated distributions is upper bounded by $O(d/T)$ (ignoring logarithmic factors), where $d$ is the data dimensionality and $T$ is the number of steps. This result holds for any target distribution with finite first-order moment. To our knowledge, this improves upon existing convergence theory for both the SDE-based sampler and another ODE-based sampler, while imposing minimal assumptions on the target data distribution and score estimates. This is achieved through a novel set of analytical tools that provides a fine-grained characterization of how the error propagates at each step of the reverse process.
A Score-Based Density Formula, with Applications in Diffusion Generative Models
Aug 29, 2024Score-based generative models (SGMs) have revolutionized the field of generative modeling, achieving unprecedented success in generating realistic and diverse content. Despite empirical advances, the theoretical basis for why optimizing the evidence lower bound (ELBO) on the log-likelihood is effective for training diffusion generative models, such as DDPMs, remains largely unexplored. In this paper, we address this question by establishing a density formula for a continuous-time diffusion process, which can be viewed as the continuous-time limit of the forward process in an SGM. This formula reveals the connection between the target density and the score function associated with each step of the forward process. Building on this, we demonstrate that the minimizer of the optimization objective for training DDPMs nearly coincides with that of the true objective, providing a theoretical foundation for optimizing DDPMs using the ELBO. Furthermore, we offer new insights into the role of score-matching regularization in training GANs, the use of ELBO in diffusion classifiers, and the recently proposed diffusion loss.
Analysis of the ICML 2023 Ranking Data: Can Authors' Opinions of Their Own Papers Assist Peer Review in Machine Learning?
Aug 24, 2024We conducted an experiment during the review process of the 2023 International Conference on Machine Learning (ICML) that requested authors with multiple submissions to rank their own papers based on perceived quality. We received 1,342 rankings, each from a distinct author, pertaining to 2,592 submissions. In this paper, we present an empirical analysis of how author-provided rankings could be leveraged to improve peer review processes at machine learning conferences. We focus on the Isotonic Mechanism, which calibrates raw review scores using author-provided rankings. Our analysis demonstrates that the ranking-calibrated scores outperform raw scores in estimating the ground truth ``expected review scores'' in both squared and absolute error metrics. Moreover, we propose several cautious, low-risk approaches to using the Isotonic Mechanism and author-provided rankings in peer review processes, including assisting senior area chairs' oversight of area chairs' recommendations, supporting the selection of paper awards, and guiding the recruitment of emergency reviewers. We conclude the paper by addressing the study's limitations and proposing future research directions.
When can weak latent factors be statistically inferred?
Jul 04, 2024



This article establishes a new and comprehensive estimation and inference theory for principal component analysis (PCA) under the weak factor model that allow for cross-sectional dependent idiosyncratic components under nearly minimal the factor strength relative to the noise level or signal-to-noise ratio. Our theory is applicable regardless of the relative growth rate between the cross-sectional dimension $N$ and temporal dimension $T$. This more realistic assumption and noticeable result requires completely new technical device, as the commonly-used leave-one-out trick is no longer applicable to the case with cross-sectional dependence. Another notable advancement of our theory is on PCA inference $ - $ for example, under the regime where $N\asymp T$, we show that the asymptotic normality for the PCA-based estimator holds as long as the signal-to-noise ratio (SNR) grows faster than a polynomial rate of $\log N$. This finding significantly surpasses prior work that required a polynomial rate of $N$. Our theory is entirely non-asymptotic, offering finite-sample characterizations for both the estimation error and the uncertainty level of statistical inference. A notable technical innovation is our closed-form first-order approximation of PCA-based estimator, which paves the way for various statistical tests. Furthermore, we apply our theories to design easy-to-implement statistics for validating whether given factors fall in the linear spans of unknown latent factors, testing structural breaks in the factor loadings for an individual unit, checking whether two units have the same risk exposures, and constructing confidence intervals for systematic risks. Our empirical studies uncover insightful correlations between our test results and economic cycles.
Adapting to Unknown Low-Dimensional Structures in Score-Based Diffusion Models
May 23, 2024This paper investigates score-based diffusion models when the underlying target distribution is concentrated on or near low-dimensional manifolds within the higher-dimensional space in which they formally reside, a common characteristic of natural image distributions. Despite previous efforts to understand the data generation process of diffusion models, existing theoretical support remains highly suboptimal in the presence of low-dimensional structure, which we strengthen in this paper. For the popular Denoising Diffusion Probabilistic Model (DDPM), we find that the dependency of the error incurred within each denoising step on the ambient dimension $d$ is in general unavoidable. We further identify a unique design of coefficients that yields a converges rate at the order of $O(k^{2}/\sqrt{T})$ (up to log factors), where $k$ is the intrinsic dimension of the target distribution and $T$ is the number of steps. This represents the first theoretical demonstration that the DDPM sampler can adapt to unknown low-dimensional structures in the target distribution, highlighting the critical importance of coefficient design. All of this is achieved by a novel set of analysis tools that characterize the algorithmic dynamics in a more deterministic manner.
Enhancing AI Diagnostics: Autonomous Lesion Masking via Semi-Supervised Deep Learning
Apr 18, 2024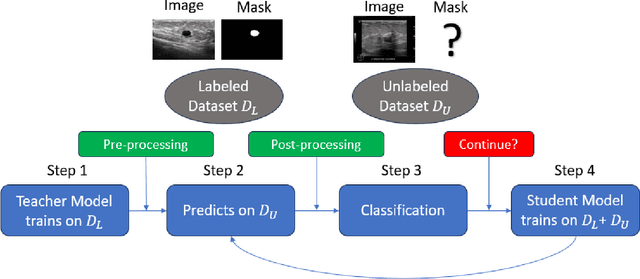
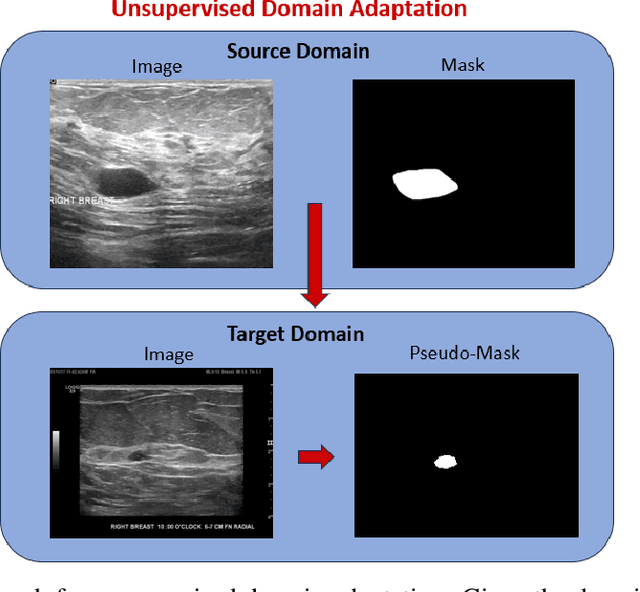


This study presents an unsupervised domain adaptation method aimed at autonomously generating image masks outlining regions of interest (ROIs) for differentiating breast lesions in breast ultrasound (US) imaging. Our semi-supervised learning approach utilizes a primitive model trained on a small public breast US dataset with true annotations. This model is then iteratively refined for the domain adaptation task, generating pseudo-masks for our private, unannotated breast US dataset. The dataset, twice the size of the public one, exhibits considerable variability in image acquisition perspectives and demographic representation, posing a domain-shift challenge. Unlike typical domain adversarial training, we employ downstream classification outcomes as a benchmark to guide the updating of pseudo-masks in subsequent iterations. We found the classification precision to be highly correlated with the completeness of the generated ROIs, which promotes the explainability of the deep learning classification model. Preliminary findings demonstrate the efficacy and reliability of this approach in streamlining the ROI annotation process, thereby enhancing the classification and localization of breast lesions for more precise and interpretable diagnoses.
Entrywise Inference for Causal Panel Data: A Simple and Instance-Optimal Approach
Jan 24, 2024



In causal inference with panel data under staggered adoption, the goal is to estimate and derive confidence intervals for potential outcomes and treatment effects. We propose a computationally efficient procedure, involving only simple matrix algebra and singular value decomposition. We derive non-asymptotic bounds on the entrywise error, establishing its proximity to a suitably scaled Gaussian variable. Despite its simplicity, our procedure turns out to be instance-optimal, in that our theoretical scaling matches a local instance-wise lower bound derived via a Bayesian Cram\'{e}r-Rao argument. Using our insights, we develop a data-driven procedure for constructing entrywise confidence intervals with pre-specified coverage guarantees. Our analysis is based on a general inferential toolbox for the SVD algorithm applied to the matrix denoising model, which might be of independent interest.