 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBookAsSumQA: An Evaluation Framework for Aspect-Based Book Summarization via Question Answering
Nov 09, 2025



Aspect-based summarization aims to generate summaries that highlight specific aspects of a text, enabling more personalized and targeted summaries. However, its application to books remains unexplored due to the difficulty of constructing reference summaries for long text. To address this challenge, we propose BookAsSumQA, a QA-based evaluation framework for aspect-based book summarization. BookAsSumQA automatically generates aspect-specific QA pairs from a narrative knowledge graph to evaluate summary quality based on its question-answering performance. Our experiments using BookAsSumQA revealed that while LLM-based approaches showed higher accuracy on shorter texts, RAG-based methods become more effective as document length increases, making them more efficient and practical for aspect-based book summarization.
A Survey on Feedback-based Multi-step Reasoning for Large Language Models on Mathematics
Feb 20, 2025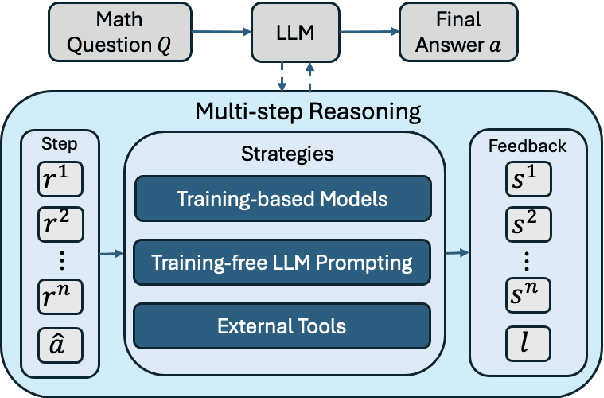
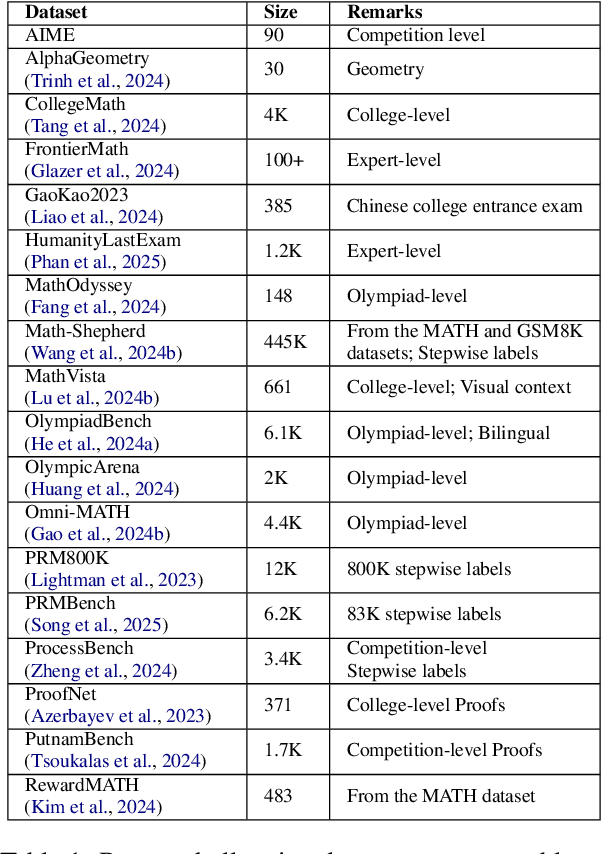

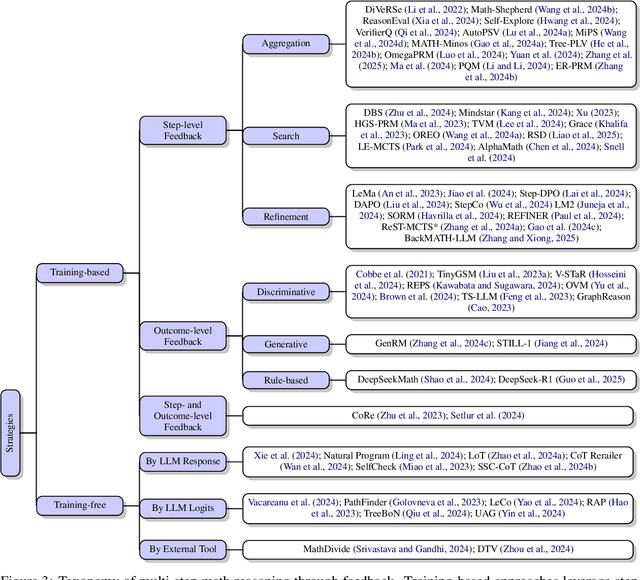
Recent progress in large language models (LLM) found chain-of-thought prompting strategies to improve the reasoning ability of LLMs by encouraging problem solving through multiple steps. Therefore, subsequent research aimed to integrate the multi-step reasoning process into the LLM itself through process rewards as feedback and achieved improvements over prompting strategies. Due to the cost of step-level annotation, some turn to outcome rewards as feedback. Aside from these training-based approaches, training-free techniques leverage frozen LLMs or external tools for feedback at each step to enhance the reasoning process. With the abundance of work in mathematics due to its logical nature, we present a survey of strategies utilizing feedback at the step and outcome levels to enhance multi-step math reasoning for LLMs. As multi-step reasoning emerges a crucial component in scaling LLMs, we hope to establish its foundation for easier understanding and empower further research.
Diffusion Models in Recommendation Systems: A Survey
Jan 17, 2025Recommender systems remain an essential topic due to its wide application in various domains and the business potential behind them. With the rise of deep learning, common solutions have leveraged neural networks to facilitate collaborative filtering, and some have turned to generative adversarial networks to augment the dataset and tackle the data sparsity issue. However, they are limited in learning the complex user and item distribution and still suffer from model collapse. Given the great generation capability exhibited by diffusion models in computer vision recently, many recommender systems have adopted diffusion models and found improvements in performance for various tasks. Diffusion models in recommender systems excel in managing complex user and item distributions and do not suffer from mode collapse. With these advantages, the amount of research in this domain have been growing rapidly and calling for a systematic survey. In this survey paper, we present and propose a taxonomy on past research papers in recommender systems that utilize diffusion models. Distinct from a prior survey paper that categorizes based on the role of the diffusion model, we categorize based on the recommendation task at hand. The decision originates from the rationale that after all, the adoption of diffusion models is to enhance the recommendation performance, not vice versa: adapting the recommendation task to enable diffusion models. Nonetheless, we offer a unique perspective for diffusion models in recommender systems complementary to existing surveys. We present the foundation algorithms in diffusion models and their applications in recommender systems to summarize the rapid development in this field. Finally, we discuss open research directions to prepare and encourage further efforts to advance the field. We compile the relevant papers in a public GitHub repository.
CLERF: Contrastive LEaRning for Full Range Head Pose Estimation
Dec 03, 2024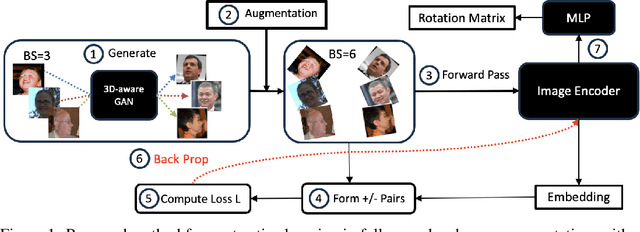
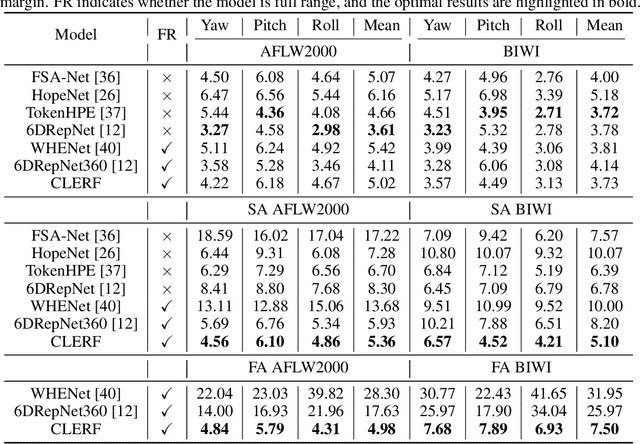

We introduce a novel framework for representation learning in head pose estimation (HPE). Previously such a scheme was difficult due to head pose data sparsity, making triplet sampling infeasible. Recent progress in 3D generative adversarial networks (3D-aware GAN) has opened the door for easily sampling triplets (anchor, positive, negative). We perform contrastive learning on extensively augmented data including geometric transformations and demonstrate that contrastive learning allows networks to learn genuine features that contribute to accurate HPE. On the other hand, we observe that existing HPE works struggle to predict head poses as accurately when test image rotation matrices are slightly out of the training dataset distribution. Experiments show that our methodology performs on par with state-of-the-art models on standard test datasets and outperforms them when images are slightly rotated/ flipped or full range head pose. To the best of our knowledge, we are the first to deliver a true full range HPE model capable of accurately predicting any head pose including upside-down pose. Furthermore, we compared with other existing full-yaw range models and demonstrated superior results.
Table Transformers for Imputing Textual Attributes
Aug 04, 2024Missing data in tabular dataset is a common issue as the performance of downstream tasks usually depends on the completeness of the training dataset. Previous missing data imputation methods focus on numeric and categorical columns, but we propose a novel end-to-end approach called Table Transformers for Imputing Textual Attributes (TTITA) based on the transformer to impute unstructured textual columns using other columns in the table. We conduct extensive experiments on two Amazon Reviews datasets, and our approach shows competitive performance outperforming baseline models such as recurrent neural networks and Llama2. The performance improvement is more significant when the target sequence has a longer length. Additionally, we incorporated multi-task learning to simultaneously impute for heterogeneous columns, boosting the performance for text imputation. We also qualitatively compare with ChatGPT for realistic applications.
Full-range Head Pose Geometric Data Augmentations
Aug 02, 2024
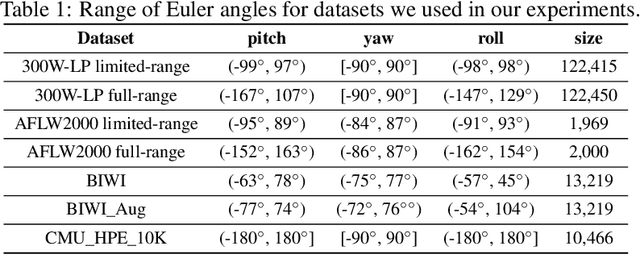

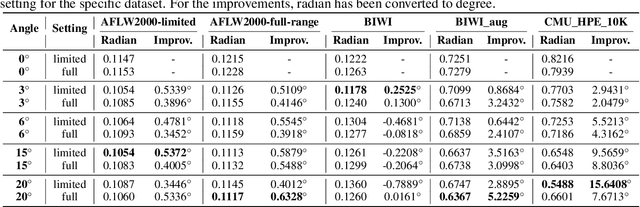
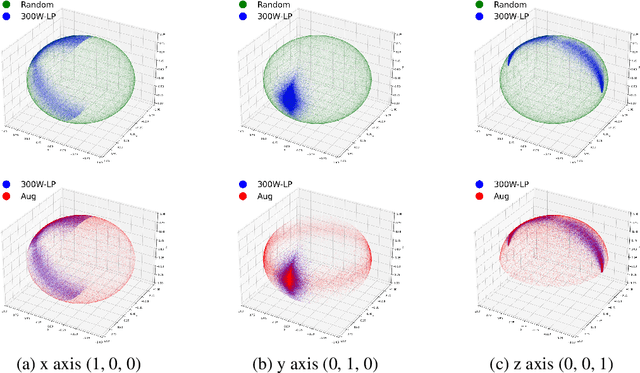
Many head pose estimation (HPE) methods promise the ability to create full-range datasets, theoretically allowing the estimation of the rotation and positioning of the head from various angles. However, these methods are only accurate within a range of head angles; exceeding this specific range led to significant inaccuracies. This is dominantly explained by unclear specificity of the coordinate systems and Euler Angles used in the foundational rotation matrix calculations. Here, we addressed these limitations by presenting (1) methods that accurately infer the correct coordinate system and Euler angles in the correct axis-sequence, (2) novel formulae for 2D geometric augmentations of the rotation matrices under the (SPECIFIC) coordinate system, (3) derivations for the correct drawing routines for rotation matrices and poses, and (4) mathematical experimentation and verification that allow proper pitch-yaw coverage for full-range head pose dataset generation. Performing our augmentation techniques to existing head pose estimation methods demonstrated a significant improvement to the model performance. Code will be released upon paper acceptance.
Enhancing AI Diagnostics: Autonomous Lesion Masking via Semi-Supervised Deep Learning
Apr 18, 2024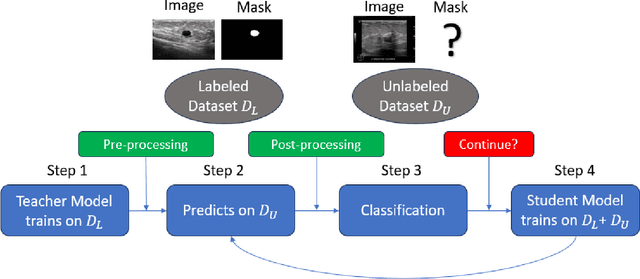
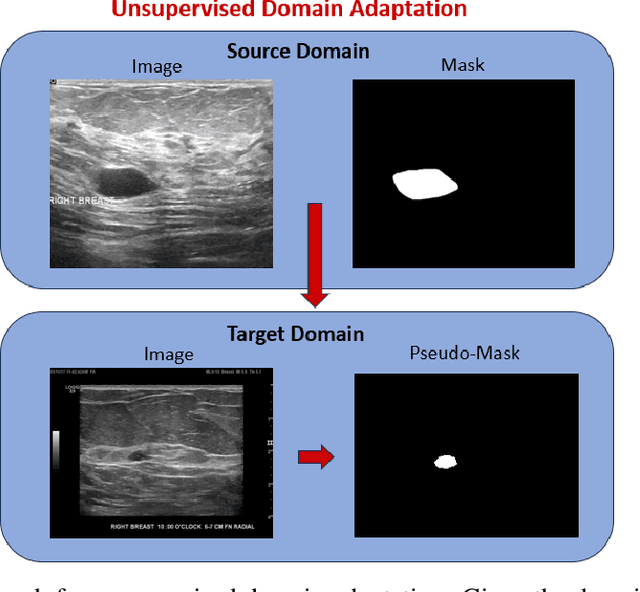


This study presents an unsupervised domain adaptation method aimed at autonomously generating image masks outlining regions of interest (ROIs) for differentiating breast lesions in breast ultrasound (US) imaging. Our semi-supervised learning approach utilizes a primitive model trained on a small public breast US dataset with true annotations. This model is then iteratively refined for the domain adaptation task, generating pseudo-masks for our private, unannotated breast US dataset. The dataset, twice the size of the public one, exhibits considerable variability in image acquisition perspectives and demographic representation, posing a domain-shift challenge. Unlike typical domain adversarial training, we employ downstream classification outcomes as a benchmark to guide the updating of pseudo-masks in subsequent iterations. We found the classification precision to be highly correlated with the completeness of the generated ROIs, which promotes the explainability of the deep learning classification model. Preliminary findings demonstrate the efficacy and reliability of this approach in streamlining the ROI annotation process, thereby enhancing the classification and localization of breast lesions for more precise and interpretable diagnoses.