 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOTI: A Model-free and Visually Interpretable Measure of Image Attackability
Jan 24, 2026Despite the tremendous success of neural networks, benign images can be corrupted by adversarial perturbations to deceive these models. Intriguingly, images differ in their attackability. Specifically, given an attack configuration, some images are easily corrupted, whereas others are more resistant. Evaluating image attackability has important applications in active learning, adversarial training, and attack enhancement. This prompts a growing interest in developing attackability measures. However, existing methods are scarce and suffer from two major limitations: (1) They rely on a model proxy to provide prior knowledge (e.g., gradients or minimal perturbation) to extract model-dependent image features. Unfortunately, in practice, many task-specific models are not readily accessible. (2) Extracted features characterizing image attackability lack visual interpretability, obscuring their direct relationship with the images. To address these, we propose a novel Object Texture Intensity (OTI), a model-free and visually interpretable measure of image attackability, which measures image attackability as the texture intensity of the image's semantic object. Theoretically, we describe the principles of OTI from the perspectives of decision boundaries as well as the mid- and high-frequency characteristics of adversarial perturbations. Comprehensive experiments demonstrate that OTI is effective and computationally efficient. In addition, our OTI provides the adversarial machine learning community with a visual understanding of attackability.
MoFu: Scale-Aware Modulation and Fourier Fusion for Multi-Subject Video Generation
Dec 26, 2025Multi-subject video generation aims to synthesize videos from textual prompts and multiple reference images, ensuring that each subject preserves natural scale and visual fidelity. However, current methods face two challenges: scale inconsistency, where variations in subject size lead to unnatural generation, and permutation sensitivity, where the order of reference inputs causes subject distortion. In this paper, we propose MoFu, a unified framework that tackles both challenges. For scale inconsistency, we introduce Scale-Aware Modulation (SMO), an LLM-guided module that extracts implicit scale cues from the prompt and modulates features to ensure consistent subject sizes. To address permutation sensitivity, we present a simple yet effective Fourier Fusion strategy that processes the frequency information of reference features via the Fast Fourier Transform to produce a unified representation. Besides, we design a Scale-Permutation Stability Loss to jointly encourage scale-consistent and permutation-invariant generation. To further evaluate these challenges, we establish a dedicated benchmark with controlled variations in subject scale and reference permutation. Extensive experiments demonstrate that MoFu significantly outperforms existing methods in preserving natural scale, subject fidelity, and overall visual quality.
Mobile-Agent-v3: Foundamental Agents for GUI Automation
Aug 21, 2025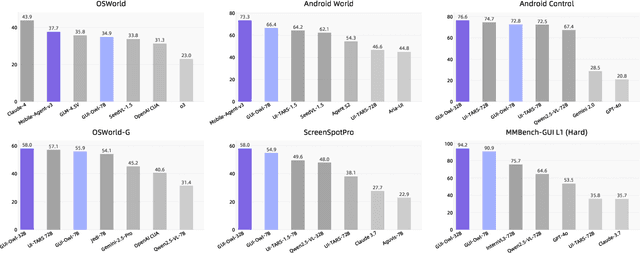
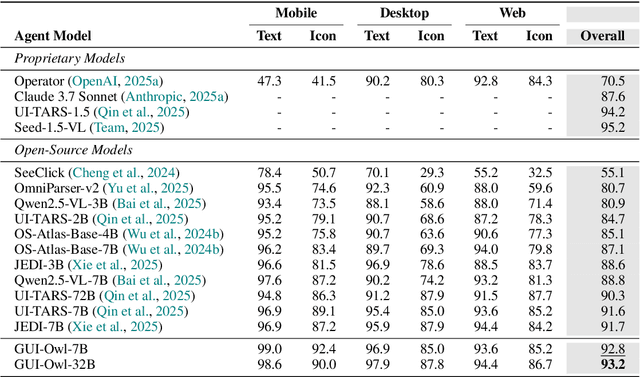
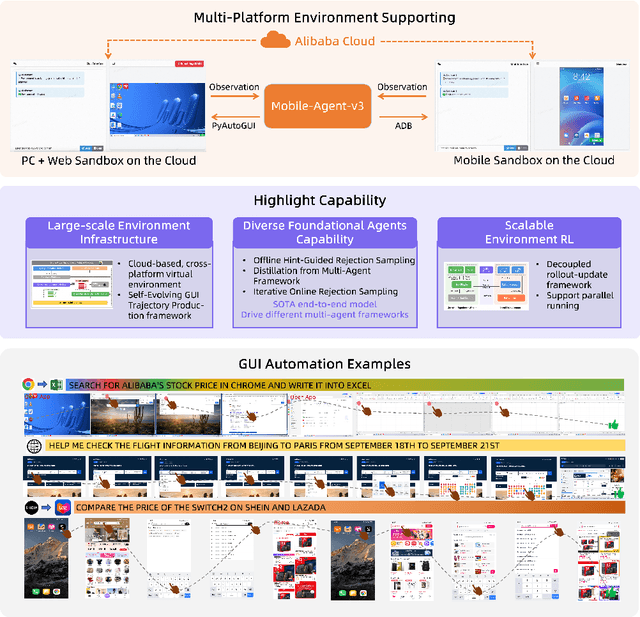
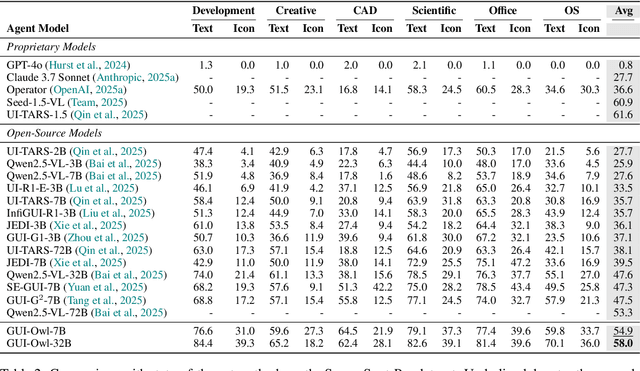
This paper introduces GUI-Owl, a foundational GUI agent model that achieves state-of-the-art performance among open-source end-to-end models on ten GUI benchmarks across desktop and mobile environments, covering grounding, question answering, planning, decision-making, and procedural knowledge. GUI-Owl-7B achieves 66.4 on AndroidWorld and 29.4 on OSWorld. Building on this, we propose Mobile-Agent-v3, a general-purpose GUI agent framework that further improves performance to 73.3 on AndroidWorld and 37.7 on OSWorld, setting a new state-of-the-art for open-source GUI agent frameworks. GUI-Owl incorporates three key innovations: (1) Large-scale Environment Infrastructure: a cloud-based virtual environment spanning Android, Ubuntu, macOS, and Windows, enabling our Self-Evolving GUI Trajectory Production framework. This generates high-quality interaction data via automated query generation and correctness validation, leveraging GUI-Owl to refine trajectories iteratively, forming a self-improving loop. It supports diverse data pipelines and reduces manual annotation. (2) Diverse Foundational Agent Capabilities: by integrating UI grounding, planning, action semantics, and reasoning patterns, GUI-Owl supports end-to-end decision-making and can act as a modular component in multi-agent systems. (3) Scalable Environment RL: we develop a scalable reinforcement learning framework with fully asynchronous training for real-world alignment. We also introduce Trajectory-aware Relative Policy Optimization (TRPO) for online RL, achieving 34.9 on OSWorld. GUI-Owl and Mobile-Agent-v3 are open-sourced at https://github.com/X-PLUG/MobileAgent.
Look Before You Leap: A GUI-Critic-R1 Model for Pre-Operative Error Diagnosis in GUI Automation
Jun 05, 2025In recent years, Multimodal Large Language Models (MLLMs) have been extensively utilized for multimodal reasoning tasks, including Graphical User Interface (GUI) automation. Unlike general offline multimodal tasks, GUI automation is executed in online interactive environments, necessitating step-by-step decision-making based on real-time status of the environment. This task has a lower tolerance for decision-making errors at each step, as any mistakes may cumulatively disrupt the process and potentially lead to irreversible outcomes like deletions or payments. To address these issues, we introduce a pre-operative critic mechanism that provides effective feedback prior to the actual execution, by reasoning about the potential outcome and correctness of actions. Specifically, we propose a Suggestion-aware Gradient Relative Policy Optimization (S-GRPO) strategy to construct our pre-operative critic model GUI-Critic-R1, incorporating a novel suggestion reward to enhance the reliability of the model's feedback. Furthermore, we develop a reasoning-bootstrapping based data collection pipeline to create a GUI-Critic-Train and a GUI-Critic-Test, filling existing gaps in GUI critic data. Static experiments on the GUI-Critic-Test across both mobile and web domains reveal that our GUI-Critic-R1 offers significant advantages in critic accuracy compared to current MLLMs. Dynamic evaluation on GUI automation benchmark further highlights the effectiveness and superiority of our model, as evidenced by improved success rates and operational efficiency.
PC-Agent: A Hierarchical Multi-Agent Collaboration Framework for Complex Task Automation on PC
Feb 21, 2025In the field of MLLM-based GUI agents, compared to smartphones, the PC scenario not only features a more complex interactive environment, but also involves more intricate intra- and inter-app workflows. To address these issues, we propose a hierarchical agent framework named PC-Agent. Specifically, from the perception perspective, we devise an Active Perception Module (APM) to overcome the inadequate abilities of current MLLMs in perceiving screenshot content. From the decision-making perspective, to handle complex user instructions and interdependent subtasks more effectively, we propose a hierarchical multi-agent collaboration architecture that decomposes decision-making processes into Instruction-Subtask-Action levels. Within this architecture, three agents (i.e., Manager, Progress and Decision) are set up for instruction decomposition, progress tracking and step-by-step decision-making respectively. Additionally, a Reflection agent is adopted to enable timely bottom-up error feedback and adjustment. We also introduce a new benchmark PC-Eval with 25 real-world complex instructions. Empirical results on PC-Eval show that our PC-Agent achieves a 32% absolute improvement of task success rate over previous state-of-the-art methods. The code is available at https://github.com/X-PLUG/MobileAgent/tree/main/PC-Agent.
A Survey on Feedback-based Multi-step Reasoning for Large Language Models on Mathematics
Feb 20, 2025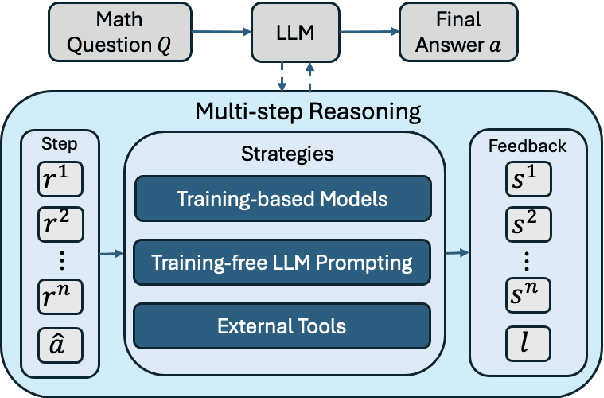
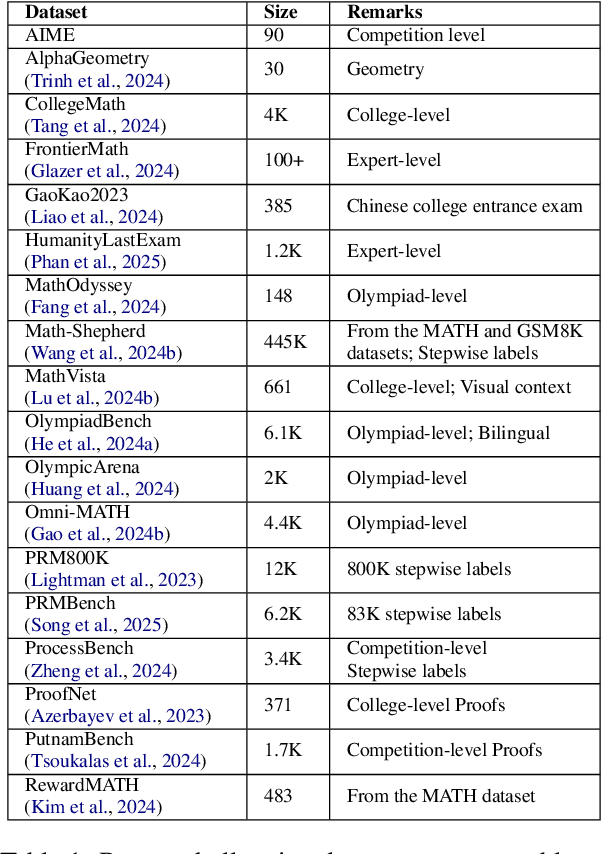

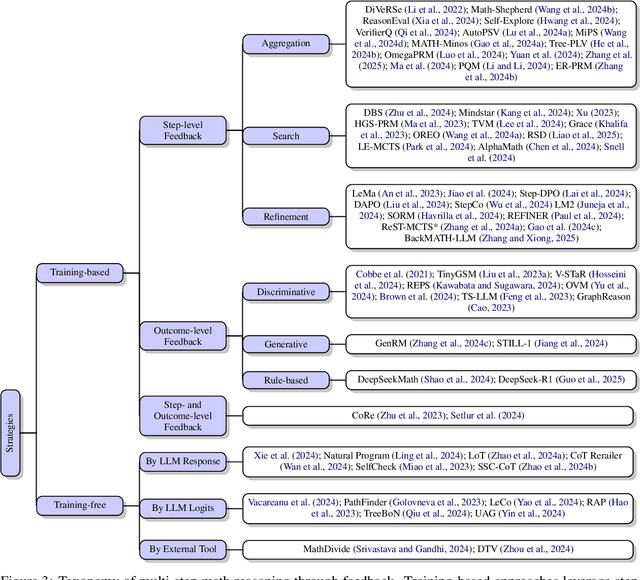
Recent progress in large language models (LLM) found chain-of-thought prompting strategies to improve the reasoning ability of LLMs by encouraging problem solving through multiple steps. Therefore, subsequent research aimed to integrate the multi-step reasoning process into the LLM itself through process rewards as feedback and achieved improvements over prompting strategies. Due to the cost of step-level annotation, some turn to outcome rewards as feedback. Aside from these training-based approaches, training-free techniques leverage frozen LLMs or external tools for feedback at each step to enhance the reasoning process. With the abundance of work in mathematics due to its logical nature, we present a survey of strategies utilizing feedback at the step and outcome levels to enhance multi-step math reasoning for LLMs. As multi-step reasoning emerges a crucial component in scaling LLMs, we hope to establish its foundation for easier understanding and empower further research.
ChainRank-DPO: Chain Rank Direct Preference Optimization for LLM Rankers
Dec 18, 2024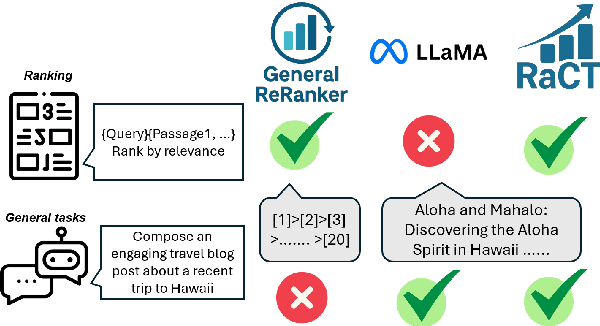
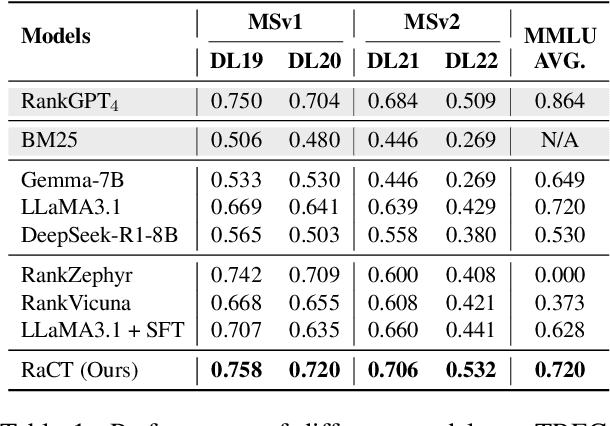

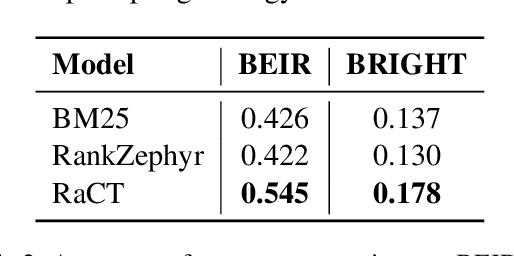
Large language models (LLMs) have demonstrated remarkable effectiveness in text reranking through works like RankGPT, leveraging their human-like reasoning about relevance. However, supervised fine-tuning for ranking often diminishes these models' general-purpose capabilities, including the crucial reasoning abilities that make them valuable for ranking. We introduce a novel approach integrating Chain-of-Thought prompting with an SFT-DPO (Supervised Fine-Tuning followed by Direct Preference Optimization) pipeline to preserve these capabilities while improving ranking performance. Our experiments on TREC 2019 and 2020 Deep Learning datasets show that our approach outperforms the state-of-the-art RankZephyr while maintaining strong performance on the Massive Multitask Language Understanding (MMLU) benchmark, demonstrating effective preservation of general-purpose capabilities through thoughtful fine-tuning strategies. Our code and data will be publicly released upon the acceptance of the paper.
CLERF: Contrastive LEaRning for Full Range Head Pose Estimation
Dec 03, 2024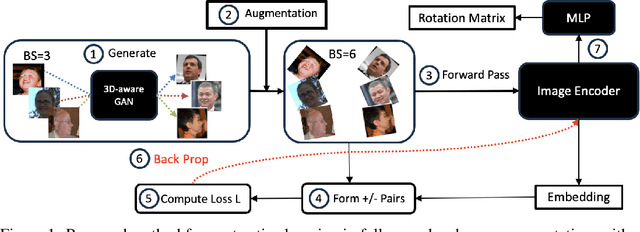
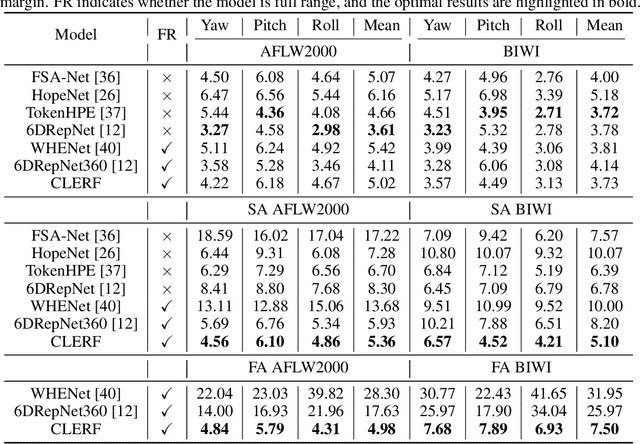
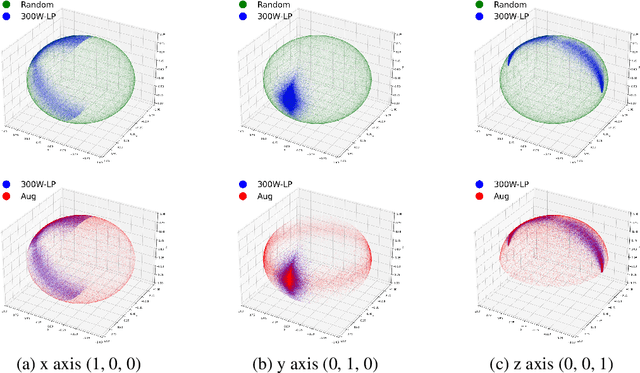

We introduce a novel framework for representation learning in head pose estimation (HPE). Previously such a scheme was difficult due to head pose data sparsity, making triplet sampling infeasible. Recent progress in 3D generative adversarial networks (3D-aware GAN) has opened the door for easily sampling triplets (anchor, positive, negative). We perform contrastive learning on extensively augmented data including geometric transformations and demonstrate that contrastive learning allows networks to learn genuine features that contribute to accurate HPE. On the other hand, we observe that existing HPE works struggle to predict head poses as accurately when test image rotation matrices are slightly out of the training dataset distribution. Experiments show that our methodology performs on par with state-of-the-art models on standard test datasets and outperforms them when images are slightly rotated/ flipped or full range head pose. To the best of our knowledge, we are the first to deliver a true full range HPE model capable of accurately predicting any head pose including upside-down pose. Furthermore, we compared with other existing full-yaw range models and demonstrated superior results.
mPLUG-Owl3: Towards Long Image-Sequence Understanding in Multi-Modal Large Language Models
Aug 09, 2024



Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in executing instructions for a variety of single-image tasks. Despite this progress, significant challenges remain in modeling long image sequences. In this work, we introduce the versatile multi-modal large language model, mPLUG-Owl3, which enhances the capability for long image-sequence understanding in scenarios that incorporate retrieved image-text knowledge, interleaved image-text, and lengthy videos. Specifically, we propose novel hyper attention blocks to efficiently integrate vision and language into a common language-guided semantic space, thereby facilitating the processing of extended multi-image scenarios. Extensive experimental results suggest that mPLUG-Owl3 achieves state-of-the-art performance among models with a similar size on single-image, multi-image, and video benchmarks. Moreover, we propose a challenging long visual sequence evaluation named Distractor Resistance to assess the ability of models to maintain focus amidst distractions. Finally, with the proposed architecture, mPLUG-Owl3 demonstrates outstanding performance on ultra-long visual sequence inputs. We hope that mPLUG-Owl3 can contribute to the development of more efficient and powerful multimodal large language models.
Full-range Head Pose Geometric Data Augmentations
Aug 02, 2024

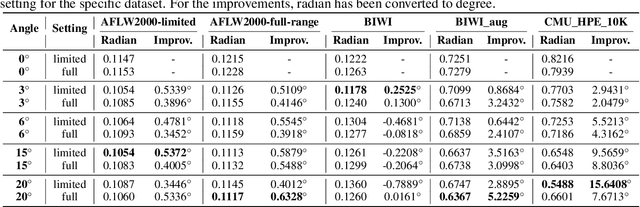
Many head pose estimation (HPE) methods promise the ability to create full-range datasets, theoretically allowing the estimation of the rotation and positioning of the head from various angles. However, these methods are only accurate within a range of head angles; exceeding this specific range led to significant inaccuracies. This is dominantly explained by unclear specificity of the coordinate systems and Euler Angles used in the foundational rotation matrix calculations. Here, we addressed these limitations by presenting (1) methods that accurately infer the correct coordinate system and Euler angles in the correct axis-sequence, (2) novel formulae for 2D geometric augmentations of the rotation matrices under the (SPECIFIC) coordinate system, (3) derivations for the correct drawing routines for rotation matrices and poses, and (4) mathematical experimentation and verification that allow proper pitch-yaw coverage for full-range head pose dataset generation. Performing our augmentation techniques to existing head pose estimation methods demonstrated a significant improvement to the model performance. Code will be released upon paper acceptance.