 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Survey on Feedback-based Multi-step Reasoning for Large Language Models on Mathematics
Paper and Code
Feb 20, 2025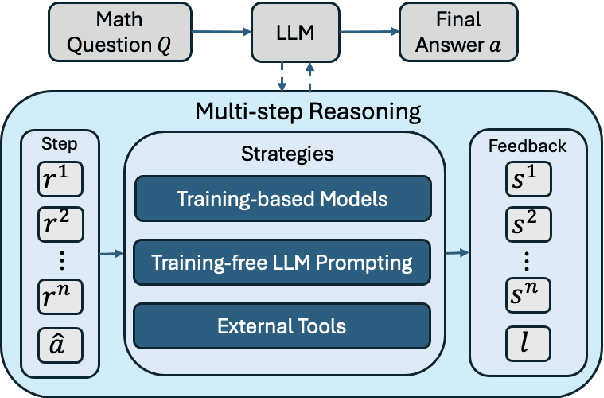
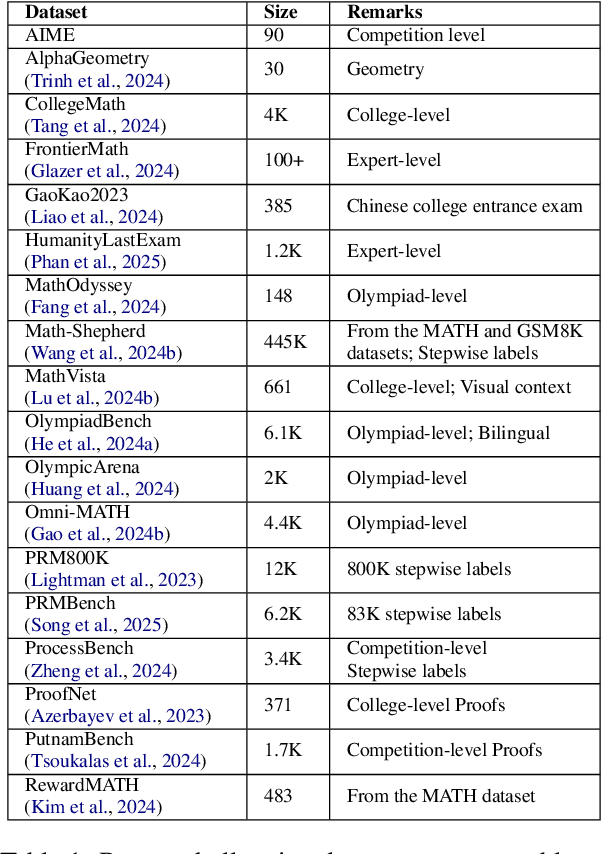

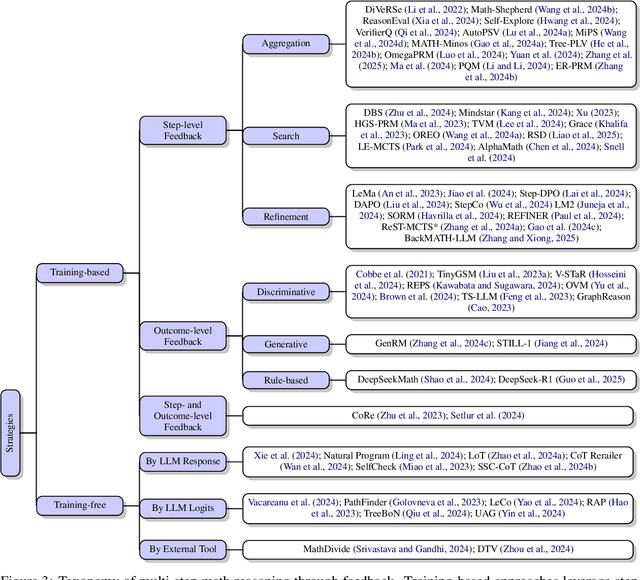
Recent progress in large language models (LLM) found chain-of-thought prompting strategies to improve the reasoning ability of LLMs by encouraging problem solving through multiple steps. Therefore, subsequent research aimed to integrate the multi-step reasoning process into the LLM itself through process rewards as feedback and achieved improvements over prompting strategies. Due to the cost of step-level annotation, some turn to outcome rewards as feedback. Aside from these training-based approaches, training-free techniques leverage frozen LLMs or external tools for feedback at each step to enhance the reasoning process. With the abundance of work in mathematics due to its logical nature, we present a survey of strategies utilizing feedback at the step and outcome levels to enhance multi-step math reasoning for LLMs. As multi-step reasoning emerges a crucial component in scaling LLMs, we hope to establish its foundation for easier understanding and empower further research.