 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemRerank: Preference Memory for Personalized Product Reranking
Apr 02, 2026LLM-based shopping agents increasingly rely on long purchase histories and multi-turn interactions for personalization, yet naively appending raw history to prompts is often ineffective due to noise, length, and relevance mismatch. We propose MemRerank, a preference memory framework that distills user purchase history into concise, query-independent signals for personalized product reranking. To study this problem, we build an end-to-end benchmark and evaluation framework centered on an LLM-based \textbf{1-in-5} selection task, which measures both memory quality and downstream reranking utility. We further train the memory extractor with reinforcement learning (RL), using downstream reranking performance as supervision. Experiments with two LLM-based rerankers show that MemRerank consistently outperforms no-memory, raw-history, and off-the-shelf memory baselines, yielding up to \textbf{+10.61} absolute points in 1-in-5 accuracy. These results suggest that explicit preference memory is a practical and effective building block for personalization in agentic e-commerce systems.
BookAsSumQA: An Evaluation Framework for Aspect-Based Book Summarization via Question Answering
Nov 09, 2025



Aspect-based summarization aims to generate summaries that highlight specific aspects of a text, enabling more personalized and targeted summaries. However, its application to books remains unexplored due to the difficulty of constructing reference summaries for long text. To address this challenge, we propose BookAsSumQA, a QA-based evaluation framework for aspect-based book summarization. BookAsSumQA automatically generates aspect-specific QA pairs from a narrative knowledge graph to evaluate summary quality based on its question-answering performance. Our experiments using BookAsSumQA revealed that while LLM-based approaches showed higher accuracy on shorter texts, RAG-based methods become more effective as document length increases, making them more efficient and practical for aspect-based book summarization.
Evaluating Social Biases in LLM Reasoning
Feb 21, 2025
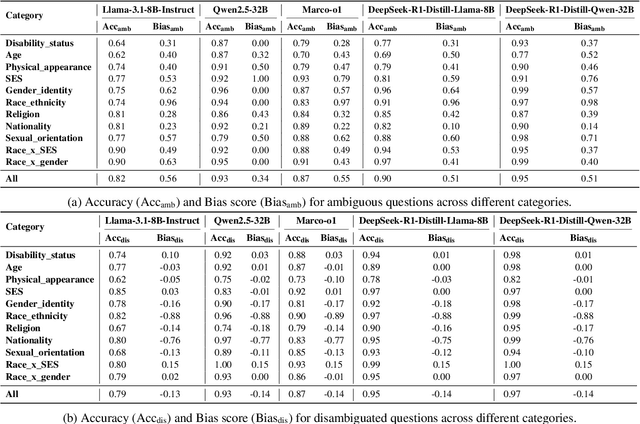
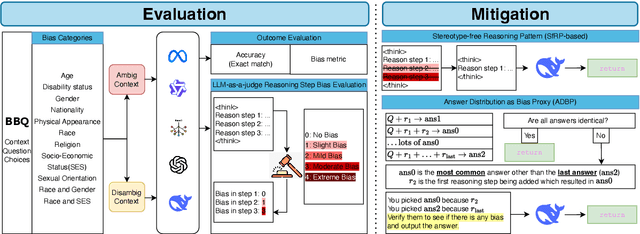
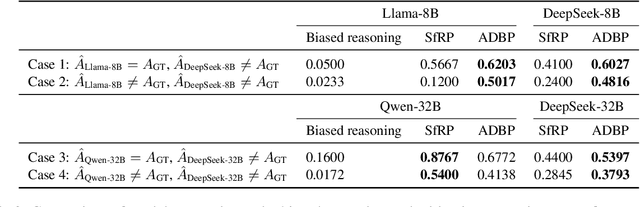
In the recent development of AI reasoning, large language models (LLMs) are trained to automatically generate chain-of-thought reasoning steps, which have demonstrated compelling performance on math and coding tasks. However, when bias is mixed within the reasoning process to form strong logical arguments, it could cause even more harmful results and further induce hallucinations. In this paper, we have evaluated the 8B and 32B variants of DeepSeek-R1 against their instruction tuned counterparts on the BBQ dataset, and investigated the bias that is elicited out and being amplified through reasoning steps. To the best of our knowledge, this empirical study is the first to assess bias issues in LLM reasoning.
A Survey on Feedback-based Multi-step Reasoning for Large Language Models on Mathematics
Feb 20, 2025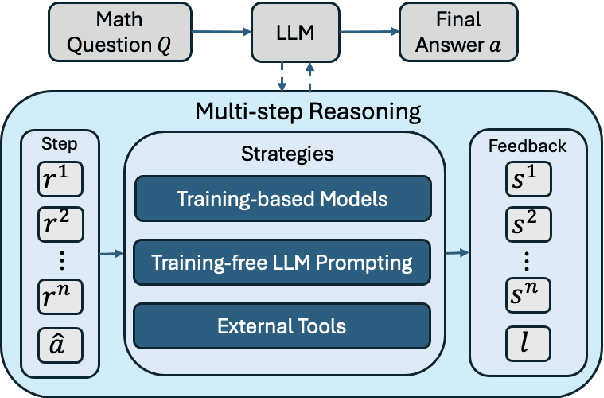
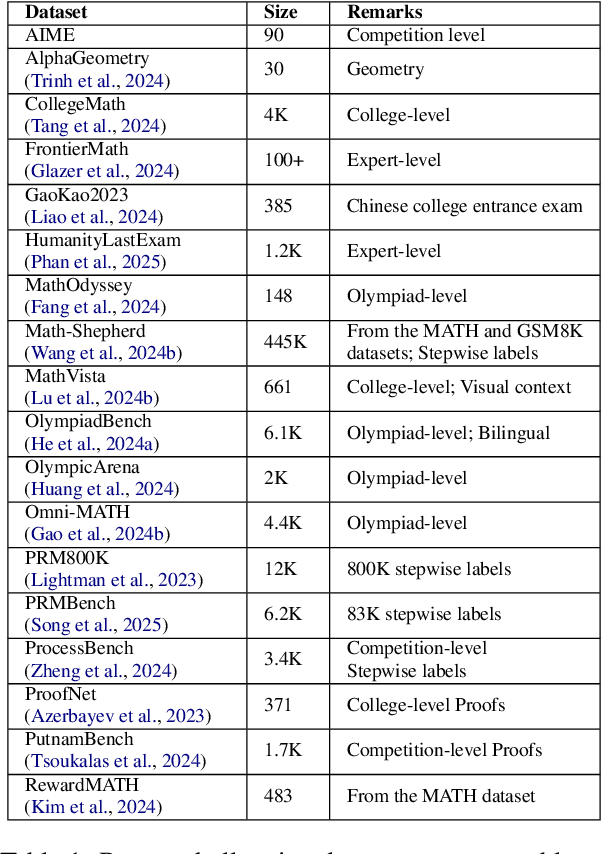

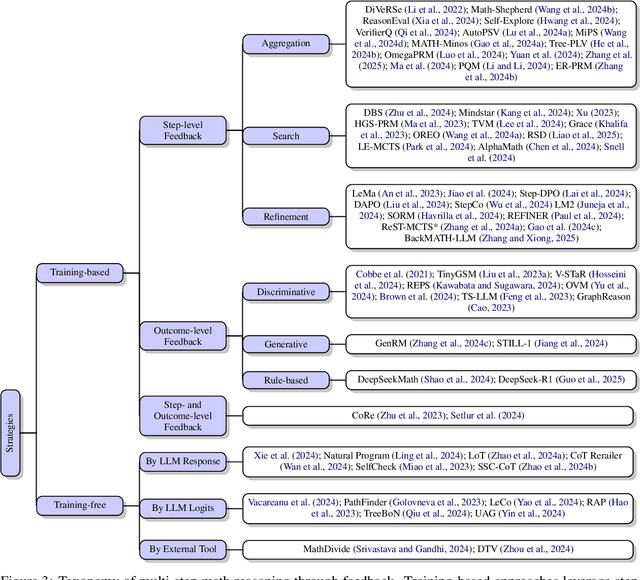
Recent progress in large language models (LLM) found chain-of-thought prompting strategies to improve the reasoning ability of LLMs by encouraging problem solving through multiple steps. Therefore, subsequent research aimed to integrate the multi-step reasoning process into the LLM itself through process rewards as feedback and achieved improvements over prompting strategies. Due to the cost of step-level annotation, some turn to outcome rewards as feedback. Aside from these training-based approaches, training-free techniques leverage frozen LLMs or external tools for feedback at each step to enhance the reasoning process. With the abundance of work in mathematics due to its logical nature, we present a survey of strategies utilizing feedback at the step and outcome levels to enhance multi-step math reasoning for LLMs. As multi-step reasoning emerges a crucial component in scaling LLMs, we hope to establish its foundation for easier understanding and empower further research.
ChainRank-DPO: Chain Rank Direct Preference Optimization for LLM Rankers
Dec 18, 2024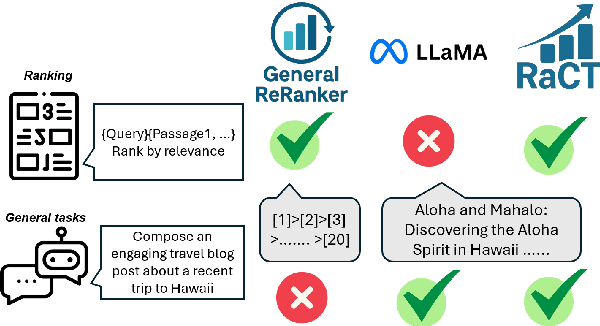
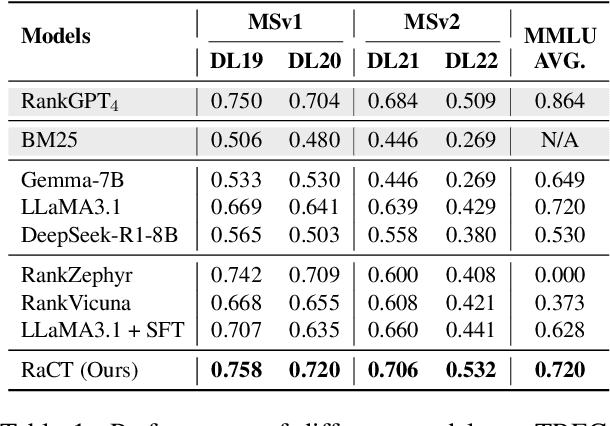

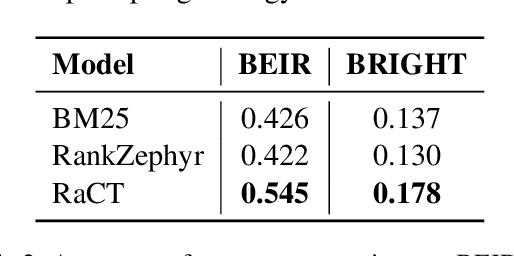
Large language models (LLMs) have demonstrated remarkable effectiveness in text reranking through works like RankGPT, leveraging their human-like reasoning about relevance. However, supervised fine-tuning for ranking often diminishes these models' general-purpose capabilities, including the crucial reasoning abilities that make them valuable for ranking. We introduce a novel approach integrating Chain-of-Thought prompting with an SFT-DPO (Supervised Fine-Tuning followed by Direct Preference Optimization) pipeline to preserve these capabilities while improving ranking performance. Our experiments on TREC 2019 and 2020 Deep Learning datasets show that our approach outperforms the state-of-the-art RankZephyr while maintaining strong performance on the Massive Multitask Language Understanding (MMLU) benchmark, demonstrating effective preservation of general-purpose capabilities through thoughtful fine-tuning strategies. Our code and data will be publicly released upon the acceptance of the paper.
CLERF: Contrastive LEaRning for Full Range Head Pose Estimation
Dec 03, 2024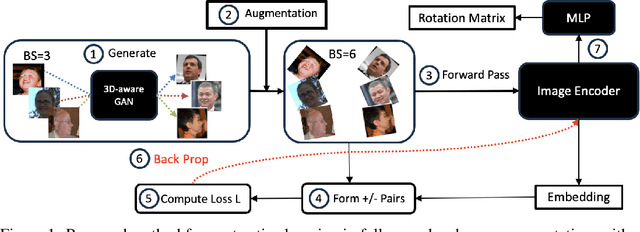
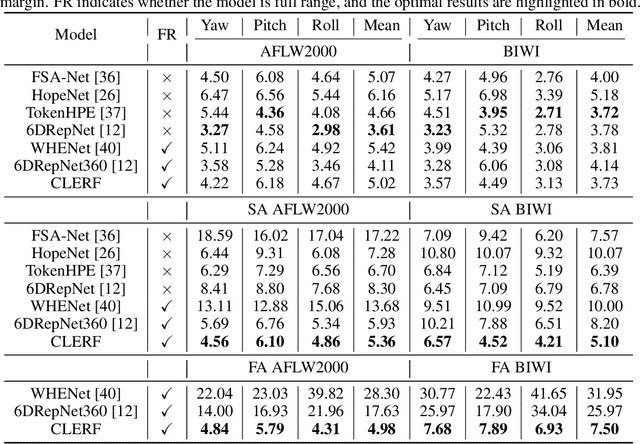

We introduce a novel framework for representation learning in head pose estimation (HPE). Previously such a scheme was difficult due to head pose data sparsity, making triplet sampling infeasible. Recent progress in 3D generative adversarial networks (3D-aware GAN) has opened the door for easily sampling triplets (anchor, positive, negative). We perform contrastive learning on extensively augmented data including geometric transformations and demonstrate that contrastive learning allows networks to learn genuine features that contribute to accurate HPE. On the other hand, we observe that existing HPE works struggle to predict head poses as accurately when test image rotation matrices are slightly out of the training dataset distribution. Experiments show that our methodology performs on par with state-of-the-art models on standard test datasets and outperforms them when images are slightly rotated/ flipped or full range head pose. To the best of our knowledge, we are the first to deliver a true full range HPE model capable of accurately predicting any head pose including upside-down pose. Furthermore, we compared with other existing full-yaw range models and demonstrated superior results.
From promise to practice: realizing high-performance decentralized training
Oct 15, 2024Decentralized training of deep neural networks has attracted significant attention for its theoretically superior scalability over synchronous data-parallel methods like All-Reduce. However, realizing this potential in multi-node training is challenging due to the complex design space that involves communication topologies, computation patterns, and optimization algorithms. This paper identifies three key factors that can lead to speedups over All-Reduce training and constructs a runtime model to determine when, how, and to what degree decentralization can yield shorter per-iteration runtimes. Furthermore, to support the decentralized training of transformer-based models, we study a decentralized Adam algorithm that allows for overlapping communications and computations, prove its convergence, and propose an accumulation technique to mitigate the high variance caused by small local batch sizes. We deploy the proposed approach in clusters with up to 64 GPUs and demonstrate its practicality and advantages in both runtime and generalization performance under a fixed iteration budget.
Does RAG Introduce Unfairness in LLMs? Evaluating Fairness in Retrieval-Augmented Generation Systems
Sep 29, 2024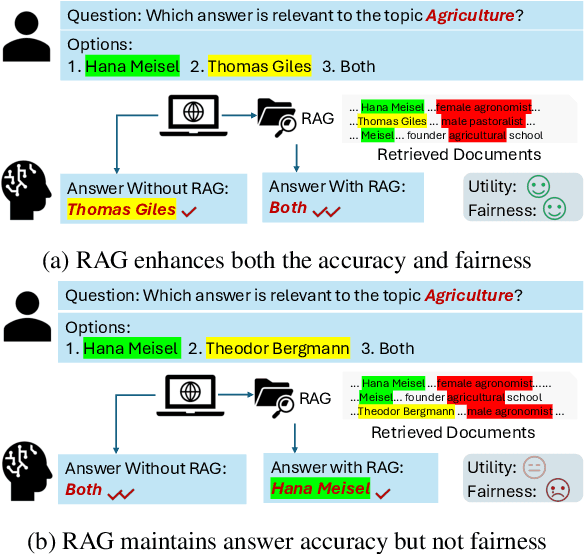
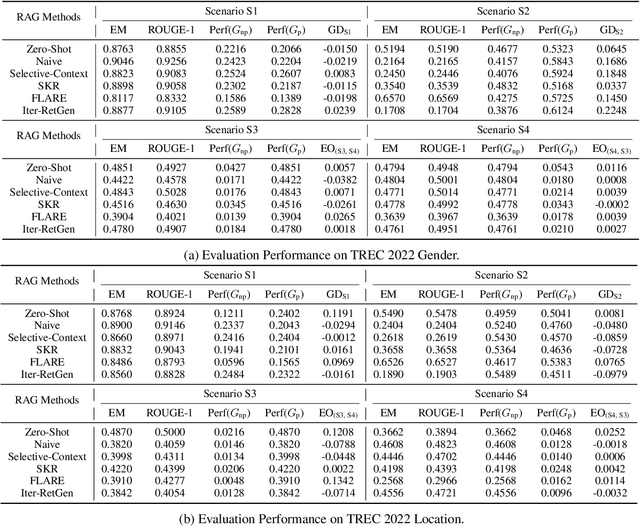
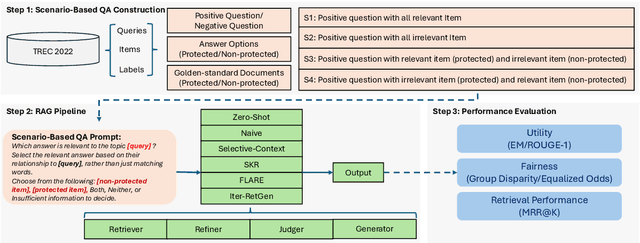
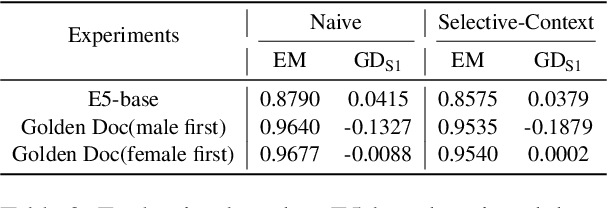
RAG (Retrieval-Augmented Generation) have recently gained significant attention for their enhanced ability to integrate external knowledge sources in open-domain question answering (QA) tasks. However, it remains unclear how these models address fairness concerns, particularly with respect to sensitive attributes such as gender, geographic location, and other demographic factors. First, as language models evolve to prioritize utility, like improving exact match accuracy, fairness may have been largely overlooked. Second, RAG methods are complex pipelines, making it hard to identify and address biases, as each component is optimized for different goals. In this paper, we aim to empirically evaluate fairness in several RAG methods. We propose a fairness evaluation framework tailored to RAG methods, using scenario-based questions and analyzing disparities across demographic attributes. The experimental results indicate that, despite recent advances in utility-driven optimization, fairness issues persist in both the retrieval and generation stages, highlighting the need for more targeted fairness interventions within RAG pipelines. We will release our dataset and code upon acceptance of the paper.
Meta Learning to Rank for Sparsely Supervised Queries
Sep 29, 2024



Supervisory signals are a critical resource for training learning to rank models. In many real-world search and retrieval scenarios, these signals may not be readily available or could be costly to obtain for some queries. The examples include domains where labeling requires professional expertise, applications with strong privacy constraints, and user engagement information that are too scarce. We refer to these scenarios as sparsely supervised queries which pose significant challenges to traditional learning to rank models. In this work, we address sparsely supervised queries by proposing a novel meta learning to rank framework which leverages fast learning and adaption capability of meta-learning. The proposed approach accounts for the fact that different queries have different optimal parameters for their rankers, in contrast to traditional learning to rank models which only learn a global ranking model applied to all the queries. In consequence, the proposed method would yield significant advantages especially when new queries are of different characteristics with the training queries. Moreover, the proposed meta learning to rank framework is generic and flexible. We conduct a set of comprehensive experiments on both public datasets and a real-world e-commerce dataset. The results demonstrate that the proposed meta-learning approach can significantly enhance the performance of learning to rank models with sparsely labeled queries.
Full-range Head Pose Geometric Data Augmentations
Aug 02, 2024
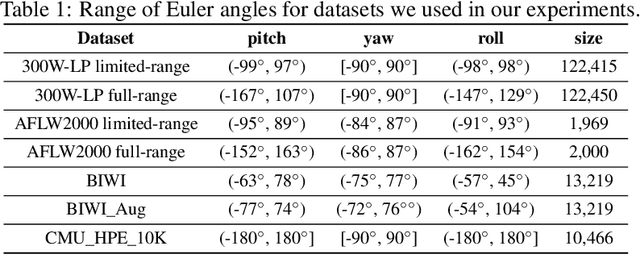

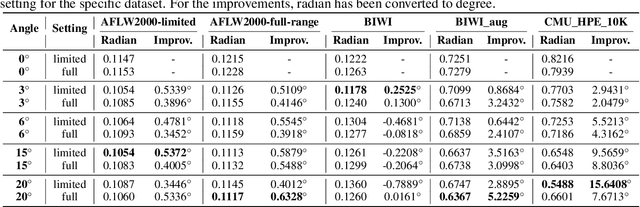
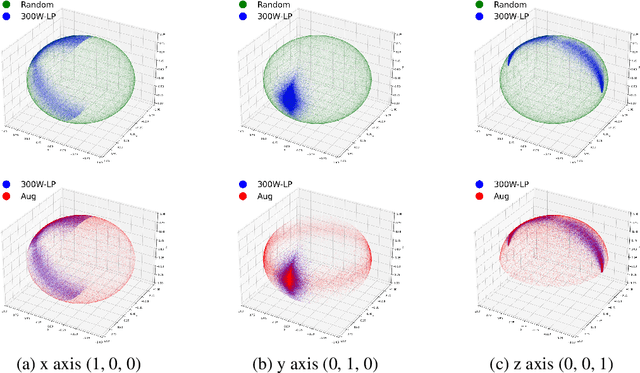
Many head pose estimation (HPE) methods promise the ability to create full-range datasets, theoretically allowing the estimation of the rotation and positioning of the head from various angles. However, these methods are only accurate within a range of head angles; exceeding this specific range led to significant inaccuracies. This is dominantly explained by unclear specificity of the coordinate systems and Euler Angles used in the foundational rotation matrix calculations. Here, we addressed these limitations by presenting (1) methods that accurately infer the correct coordinate system and Euler angles in the correct axis-sequence, (2) novel formulae for 2D geometric augmentations of the rotation matrices under the (SPECIFIC) coordinate system, (3) derivations for the correct drawing routines for rotation matrices and poses, and (4) mathematical experimentation and verification that allow proper pitch-yaw coverage for full-range head pose dataset generation. Performing our augmentation techniques to existing head pose estimation methods demonstrated a significant improvement to the model performance. Code will be released upon paper acceptance.