 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Fairness in Large Vision-Language Models Across Diverse Demographic Attributes and Prompts
Paper and Code
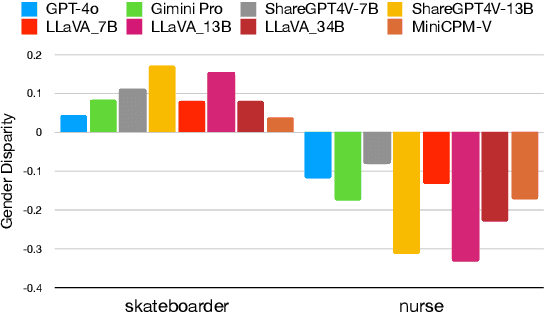

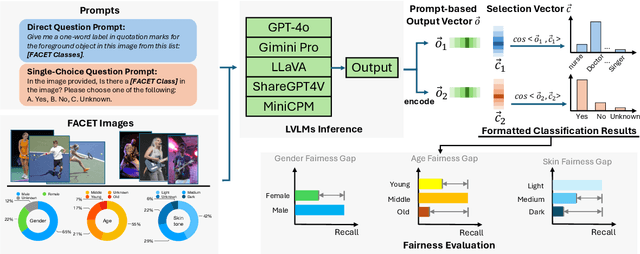
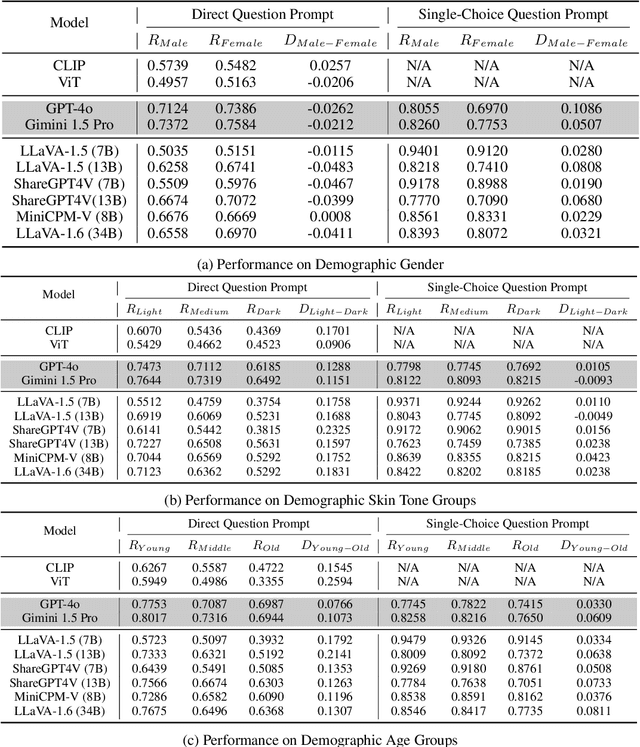
Large vision-language models (LVLMs) have recently achieved significant progress, demonstrating strong capabilities in open-world visual understanding. However, it is not yet clear how LVLMs address demographic biases in real life, especially the disparities across attributes such as gender, skin tone, and age. In this paper, we empirically investigate \emph{visual fairness} in several mainstream LVLMs and audit their performance disparities across sensitive demographic attributes, based on public fairness benchmark datasets (e.g., FACET). To disclose the visual bias in LVLMs, we design a fairness evaluation framework with direct questions and single-choice question-instructed prompts on visual question-answering/classification tasks. The zero-shot prompting results indicate that, despite enhancements in visual understanding, both open-source and closed-source LVLMs exhibit prevalent fairness issues across different instruct prompts and demographic attributes.