 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHPE-CogVLM: New Head Pose Grounding Task Exploration on Vision Language Model
Paper and Code

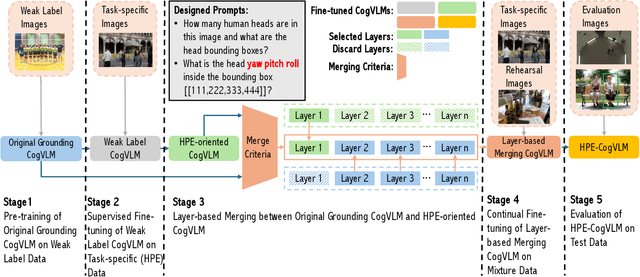
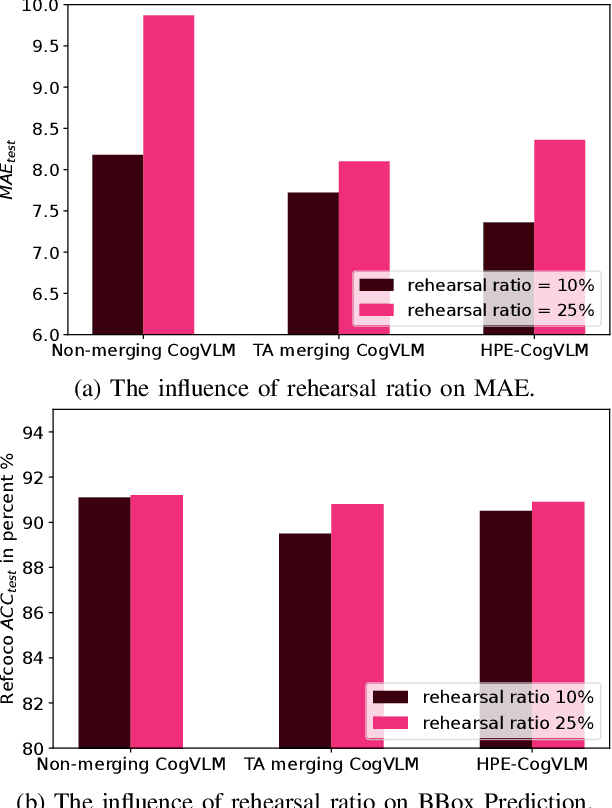

Head pose estimation (HPE) task requires a sophisticated understanding of 3D spatial relationships and precise numerical output of yaw, pitch, and roll Euler angles. Previous HPE studies are mainly based on Non-large language models (Non-LLMs), which rely on close-up human heads cropped from the full image as inputs and lack robustness in real-world scenario. In this paper, we present a novel framework to enhance the HPE prediction task by leveraging the visual grounding capability of CogVLM. CogVLM is a vision language model (VLM) with grounding capability of predicting object bounding boxes (BBoxes), which enables HPE training and prediction using full image information input. To integrate the HPE task into the VLM, we first cop with the catastrophic forgetting problem in large language models (LLMs) by investigating the rehearsal ratio in the data rehearsal method. Then, we propose and validate a LoRA layer-based model merging method, which keeps the integrity of parameters, to enhance the HPE performance in the framework. The results show our HPE-CogVLM achieves a 31.5\% reduction in Mean Absolute Error for HPE prediction over the current Non-LLM based state-of-the-art in cross-dataset evaluation. Furthermore, we compare our LoRA layer-based model merging method with LoRA fine-tuning only and other merging methods in CogVLM. The results demonstrate our framework outperforms them in all HPE metrics.