 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYOTOnet: Zero-Shot Cross-Domain Fault Diagnosis via Domain-Conditioned Mixture of Experts
May 06, 2026Mechanical equipment forms the critical backbone of modern industrial production, yet domain shift severely limits the generalization of deep learning based fault diagnosis models across different equipment and operating conditions.Inspired by the success of foundation models in achieving zero-shotgeneralization, we propose YOTOnet (You Only Train Once), a novel architecture specifically designed for cross-domain fault diagnosis in mechanical equipment.YOTOnet comprises three core components: (1) a physics-aware Invariant Feature Distiller that extracts domain-agnostic representations using multi-scale dilated convolutions and FFT-based time-frequency fusion,(2) Domain-Conditioned Sparse Experts (DC-MoE) that adaptively route inputs to specialized processors via learned gating without external meta-data, and (3) a dual-head classification system with auxiliary supervision.Extensive validation on five public bearing datasets (CWRU, MFPT, XJTU,OTTAWA, HUST) through 30 cross-dataset protocols demonstrates the superiority of YOTOnet compared with other state-of-the-art methods. Critically, we observe a clear scaling effect-average test F1 improves from 0.5339(1 training dataset) to 0.705 (4 datasets), with a clear gain when moving from 3 to 4 datasets. These findings provide empirical evidence that foundation model principles can enable robust, train-once deployment for industrial fault diagnosis.
Controlled disagreement improves generalization in decentralized training
Feb 02, 2026Decentralized training is often regarded as inferior to centralized training because the consensus errors between workers are thought to undermine convergence and generalization, even with homogeneous data distributions. This work challenges this view by introducing decentralized SGD with Adaptive Consensus (DSGD-AC), which intentionally preserves non-vanishing consensus errors through a time-dependent scaling mechanism. We prove that these errors are not random noise but systematically align with the dominant Hessian subspace, acting as structured perturbations that guide optimization toward flatter minima. Across image classification and machine translation benchmarks, DSGD-AC consistently surpasses both standard DSGD and centralized SGD in test accuracy and solution flatness. Together, these results establish consensus errors as a useful implicit regularizer and open a new perspective on the design of decentralized learning algorithms.
Regression generation adversarial network based on dual data evaluation strategy for industrial application
Dec 22, 2025Soft sensing infers hard-to-measure data through a large number of easily obtainable variables. However, in complex industrial scenarios, the issue of insufficient data volume persists, which diminishes the reliability of soft sensing. Generative Adversarial Networks (GAN) are one of the effective solutions for addressing insufficient samples. Nevertheless, traditional GAN fail to account for the mapping relationship between labels and features, which limits further performance improvement. Although some studies have proposed solutions, none have considered both performance and efficiency simultaneously. To address these problems, this paper proposes the multi-task learning-based regression GAN framework that integrates regression information into both the discriminator and generator, and implements a shallow sharing mechanism between the discriminator and regressor. This approach significantly enhances the quality of generated samples while improving the algorithm's operational efficiency. Moreover, considering the importance of training samples and generated samples, a dual data evaluation strategy is designed to make GAN generate more diverse samples, thereby increasing the generalization of subsequent modeling. The superiority of method is validated through four classic industrial soft sensing cases: wastewater treatment plants, surface water, $CO_2$ absorption towers, and industrial gas turbines.
From promise to practice: realizing high-performance decentralized training
Oct 15, 2024Decentralized training of deep neural networks has attracted significant attention for its theoretically superior scalability over synchronous data-parallel methods like All-Reduce. However, realizing this potential in multi-node training is challenging due to the complex design space that involves communication topologies, computation patterns, and optimization algorithms. This paper identifies three key factors that can lead to speedups over All-Reduce training and constructs a runtime model to determine when, how, and to what degree decentralization can yield shorter per-iteration runtimes. Furthermore, to support the decentralized training of transformer-based models, we study a decentralized Adam algorithm that allows for overlapping communications and computations, prove its convergence, and propose an accumulation technique to mitigate the high variance caused by small local batch sizes. We deploy the proposed approach in clusters with up to 64 GPUs and demonstrate its practicality and advantages in both runtime and generalization performance under a fixed iteration budget.
Bringing regularized optimal transport to lightspeed: a splitting method adapted for GPUs
May 29, 2023
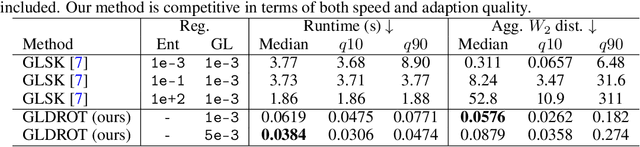

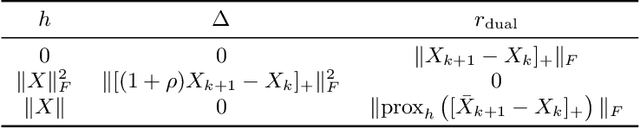
We present an efficient algorithm for regularized optimal transport. In contrast to previous methods, we use the Douglas-Rachford splitting technique to develop an efficient solver that can handle a broad class of regularizers. The algorithm has strong global convergence guarantees, low per-iteration cost, and can exploit GPU parallelization, making it considerably faster than the state-of-the-art for many problems. We illustrate its competitiveness in several applications, including domain adaptation and learning of generative models.