 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubmodular Evaluation Subset Selection in Automatic Prompt Optimization
Jan 07, 2026Automatic prompt optimization reduces manual prompt engineering, but relies on task performance measured on a small, often randomly sampled evaluation subset as its main source of feedback signal. Despite this, how to select that evaluation subset is usually treated as an implementation detail. We study evaluation subset selection for prompt optimization from a principled perspective and propose SESS, a submodular evaluation subset selection method. We frame selection as maximizing an objective set function and show that, under mild conditions, it is monotone and submodular, enabling greedy selection with theoretical guarantees. Across GSM8K, MATH, and GPQA-Diamond, submodularly selected evaluation subsets can yield better optimized prompts than random or heuristic baselines.
Generating Query-Relevant Document Summaries via Reinforcement Learning
Aug 11, 2025E-commerce search engines often rely solely on product titles as input for ranking models with latency constraints. However, this approach can result in suboptimal relevance predictions, as product titles often lack sufficient detail to capture query intent. While product descriptions provide richer information, their verbosity and length make them unsuitable for real-time ranking, particularly for computationally expensive architectures like cross-encoder ranking models. To address this challenge, we propose ReLSum, a novel reinforcement learning framework designed to generate concise, query-relevant summaries of product descriptions optimized for search relevance. ReLSum leverages relevance scores as rewards to align the objectives of summarization and ranking, effectively overcoming limitations of prior methods, such as misaligned learning targets. The framework employs a trainable large language model (LLM) to produce summaries, which are then used as input for a cross-encoder ranking model. Experimental results demonstrate significant improvements in offline metrics, including recall and NDCG, as well as online user engagement metrics. ReLSum provides a scalable and efficient solution for enhancing search relevance in large-scale e-commerce systems.
Knowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
May 11, 2025
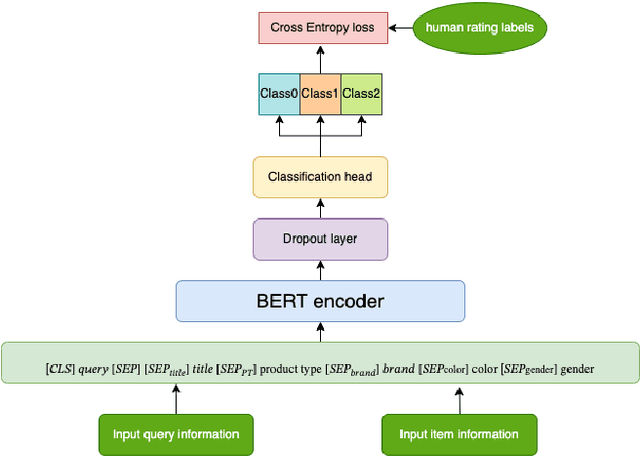
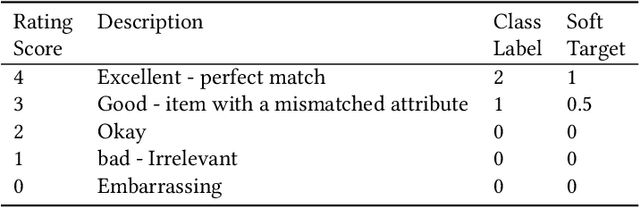
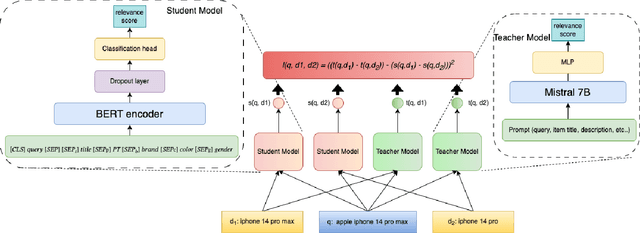
Ensuring the products displayed in e-commerce search results are relevant to users queries is crucial for improving the user experience. With their advanced semantic understanding, deep learning models have been widely used for relevance matching in search tasks. While large language models (LLMs) offer superior ranking capabilities, it is challenging to deploy LLMs in real-time systems due to the high-latency requirements. To leverage the ranking power of LLMs while meeting the low-latency demands of production systems, we propose a novel framework that distills a high performing LLM into a more efficient, low-latency student model. To help the student model learn more effectively from the teacher model, we first train the teacher LLM as a classification model with soft targets. Then, we train the student model to capture the relevance margin between pairs of products for a given query using mean squared error loss. Instead of using the same training data as the teacher model, we significantly expand the student model dataset by generating unlabeled data and labeling it with the teacher model predictions. Experimental results show that the student model performance continues to improve as the size of the augmented training data increases. In fact, with enough augmented data, the student model can outperform the teacher model. The student model has been successfully deployed in production at Walmart.com with significantly positive metrics.
* 9 pages, published at WWWW'25
Meta Learning to Rank for Sparsely Supervised Queries
Sep 29, 2024



Supervisory signals are a critical resource for training learning to rank models. In many real-world search and retrieval scenarios, these signals may not be readily available or could be costly to obtain for some queries. The examples include domains where labeling requires professional expertise, applications with strong privacy constraints, and user engagement information that are too scarce. We refer to these scenarios as sparsely supervised queries which pose significant challenges to traditional learning to rank models. In this work, we address sparsely supervised queries by proposing a novel meta learning to rank framework which leverages fast learning and adaption capability of meta-learning. The proposed approach accounts for the fact that different queries have different optimal parameters for their rankers, in contrast to traditional learning to rank models which only learn a global ranking model applied to all the queries. In consequence, the proposed method would yield significant advantages especially when new queries are of different characteristics with the training queries. Moreover, the proposed meta learning to rank framework is generic and flexible. We conduct a set of comprehensive experiments on both public datasets and a real-world e-commerce dataset. The results demonstrate that the proposed meta-learning approach can significantly enhance the performance of learning to rank models with sparsely labeled queries.
Classifying Emails into Human vs Machine Category
Dec 14, 2021



It is an essential product requirement of Yahoo Mail to distinguish between personal and machine-generated emails. The old production classifier in Yahoo Mail was based on a simple logistic regression model. That model was trained by aggregating features at the SMTP address level. We propose building deep learning models at the message level. We built and trained four individual CNN models: (1) a content model with subject and content as input; (2) a sender model with sender email address and name as input; (3) an action model by analyzing email recipients' action patterns and correspondingly generating target labels based on senders' opening/deleting behaviors; (4) a salutation model by utilizing senders' "explicit salutation" signal as positive labels. Next, we built a final full model after exploring different combinations of the above four models. Experimental results on editorial data show that our full model improves the adjusted-recall from 70.5% to 78.8% compared to the old production model, while at the same time lifts the precision from 94.7% to 96.0%. Our full model also significantly beats the state-of-the-art Bert model at this task. This full model has been deployed into the current production system (Yahoo Mail 6).