 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation for Enhancing Walmart E-commerce Search Relevance Using Large Language Models
May 11, 2025
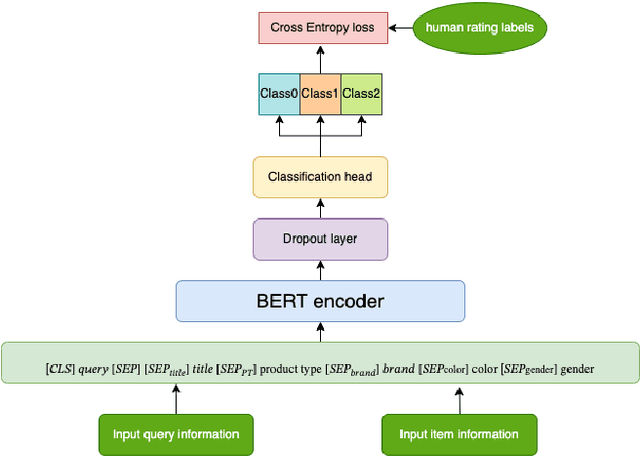
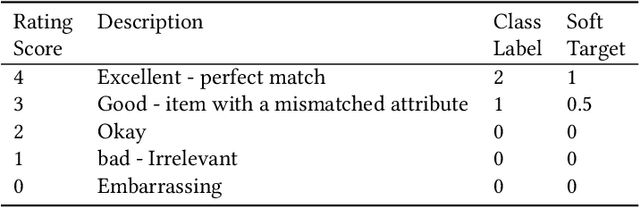
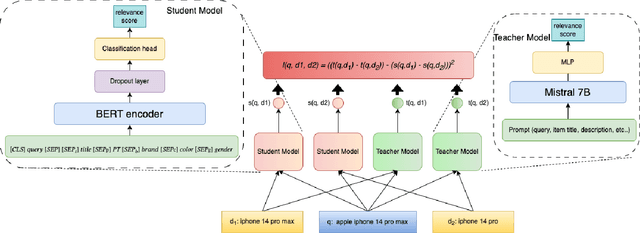
Ensuring the products displayed in e-commerce search results are relevant to users queries is crucial for improving the user experience. With their advanced semantic understanding, deep learning models have been widely used for relevance matching in search tasks. While large language models (LLMs) offer superior ranking capabilities, it is challenging to deploy LLMs in real-time systems due to the high-latency requirements. To leverage the ranking power of LLMs while meeting the low-latency demands of production systems, we propose a novel framework that distills a high performing LLM into a more efficient, low-latency student model. To help the student model learn more effectively from the teacher model, we first train the teacher LLM as a classification model with soft targets. Then, we train the student model to capture the relevance margin between pairs of products for a given query using mean squared error loss. Instead of using the same training data as the teacher model, we significantly expand the student model dataset by generating unlabeled data and labeling it with the teacher model predictions. Experimental results show that the student model performance continues to improve as the size of the augmented training data increases. In fact, with enough augmented data, the student model can outperform the teacher model. The student model has been successfully deployed in production at Walmart.com with significantly positive metrics.
* 9 pages, published at WWWW'25
Semantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
Meta Learning to Rank for Sparsely Supervised Queries
Sep 29, 2024



Supervisory signals are a critical resource for training learning to rank models. In many real-world search and retrieval scenarios, these signals may not be readily available or could be costly to obtain for some queries. The examples include domains where labeling requires professional expertise, applications with strong privacy constraints, and user engagement information that are too scarce. We refer to these scenarios as sparsely supervised queries which pose significant challenges to traditional learning to rank models. In this work, we address sparsely supervised queries by proposing a novel meta learning to rank framework which leverages fast learning and adaption capability of meta-learning. The proposed approach accounts for the fact that different queries have different optimal parameters for their rankers, in contrast to traditional learning to rank models which only learn a global ranking model applied to all the queries. In consequence, the proposed method would yield significant advantages especially when new queries are of different characteristics with the training queries. Moreover, the proposed meta learning to rank framework is generic and flexible. We conduct a set of comprehensive experiments on both public datasets and a real-world e-commerce dataset. The results demonstrate that the proposed meta-learning approach can significantly enhance the performance of learning to rank models with sparsely labeled queries.
Large Language Models for Relevance Judgment in Product Search
Jun 01, 2024High relevance of retrieved and re-ranked items to the search query is the cornerstone of successful product search, yet measuring relevance of items to queries is one of the most challenging tasks in product information retrieval, and quality of product search is highly influenced by the precision and scale of available relevance-labelled data. In this paper, we present an array of techniques for leveraging Large Language Models (LLMs) for automating the relevance judgment of query-item pairs (QIPs) at scale. Using a unique dataset of multi-million QIPs, annotated by human evaluators, we test and optimize hyper parameters for finetuning billion-parameter LLMs with and without Low Rank Adaption (LoRA), as well as various modes of item attribute concatenation and prompting in LLM finetuning, and consider trade offs in item attribute inclusion for quality of relevance predictions. We demonstrate considerable improvement over baselines of prior generations of LLMs, as well as off-the-shelf models, towards relevance annotations on par with the human relevance evaluators. Our findings have immediate implications for the growing field of relevance judgment automation in product search.
A Multi-task Learning Framework for Product Ranking with BERT
Feb 10, 2022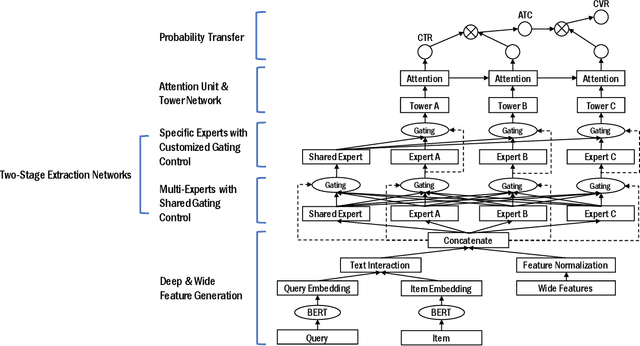



Product ranking is a crucial component for many e-commerce services. One of the major challenges in product search is the vocabulary mismatch between query and products, which may be a larger vocabulary gap problem compared to other information retrieval domains. While there is a growing collection of neural learning to match methods aimed specifically at overcoming this issue, they do not leverage the recent advances of large language models for product search. On the other hand, product ranking often deals with multiple types of engagement signals such as clicks, add-to-cart, and purchases, while most of the existing works are focused on optimizing one single metric such as click-through rate, which may suffer from data sparsity. In this work, we propose a novel end-to-end multi-task learning framework for product ranking with BERT to address the above challenges. The proposed model utilizes domain-specific BERT with fine-tuning to bridge the vocabulary gap and employs multi-task learning to optimize multiple objectives simultaneously, which yields a general end-to-end learning framework for product search. We conduct a set of comprehensive experiments on a real-world e-commerce dataset and demonstrate significant improvement of the proposed approach over the state-of-the-art baseline methods.