 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoPep: A geometry-aware masked language model for protein-peptide binding site prediction
Oct 30, 2025Multimodal approaches that integrate protein structure and sequence have achieved remarkable success in protein-protein interface prediction. However, extending these methods to protein-peptide interactions remains challenging due to the inherent conformational flexibility of peptides and the limited availability of structural data that hinder direct training of structure-aware models. To address these limitations, we introduce GeoPep, a novel framework for peptide binding site prediction that leverages transfer learning from ESM3, a multimodal protein foundation model. GeoPep fine-tunes ESM3's rich pre-learned representations from protein-protein binding to address the limited availability of protein-peptide binding data. The fine-tuned model is further integrated with a parameter-efficient neural network architecture capable of learning complex patterns from sparse data. Furthermore, the model is trained using distance-based loss functions that exploit 3D structural information to enhance binding site prediction. Comprehensive evaluations demonstrate that GeoPep significantly outperforms existing methods in protein-peptide binding site prediction by effectively capturing sparse and heterogeneous binding patterns.
Semantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
Offline Reinforcement Learning with Imbalanced Datasets
Jul 29, 2023The prevalent use of benchmarks in current offline reinforcement learning (RL) research has led to a neglect of the imbalance of real-world dataset distributions in the development of models. The real-world offline RL dataset is often imbalanced over the state space due to the challenge of exploration or safety considerations. In this paper, we specify properties of imbalanced datasets in offline RL, where the state coverage follows a power law distribution characterized by skewed policies. Theoretically and empirically, we show that typically offline RL methods based on distributional constraints, such as conservative Q-learning (CQL), are ineffective in extracting policies under the imbalanced dataset. Inspired by natural intelligence, we propose a novel offline RL method that utilizes the augmentation of CQL with a retrieval process to recall past related experiences, effectively alleviating the challenges posed by imbalanced datasets. We evaluate our method on several tasks in the context of imbalanced datasets with varying levels of imbalance, utilizing the variant of D4RL. Empirical results demonstrate the superiority of our method over other baselines.
Target specific peptide design using latent space approximate trajectory collector
Feb 02, 2023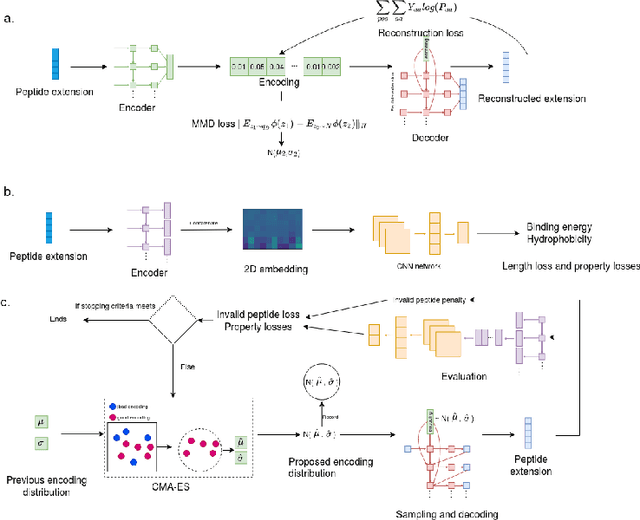

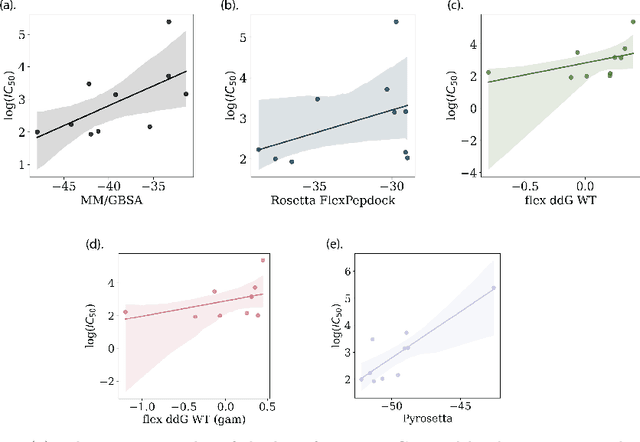
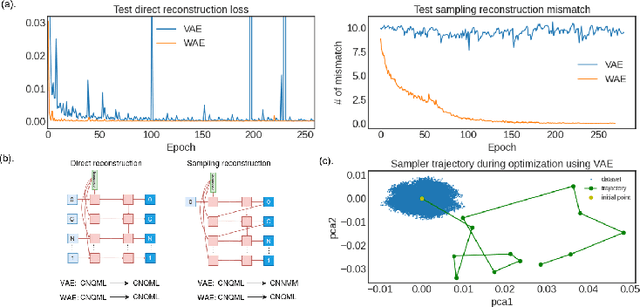
Despite the prevalence and many successes of deep learning applications in de novo molecular design, the problem of peptide generation targeting specific proteins remains unsolved. A main barrier for this is the scarcity of the high-quality training data. To tackle the issue, we propose a novel machine learning based peptide design architecture, called Latent Space Approximate Trajectory Collector (LSATC). It consists of a series of samplers on an optimization trajectory on a highly non-convex energy landscape that approximates the distributions of peptides with desired properties in a latent space. The process involves little human intervention and can be implemented in an end-to-end manner. We demonstrate the model by the design of peptide extensions targeting Beta-catenin, a key nuclear effector protein involved in canonical Wnt signalling. When compared with a random sampler, LSATC can sample peptides with $36\%$ lower binding scores in a $16$ times smaller interquartile range (IQR) and $284\%$ less hydrophobicity with a $1.4$ times smaller IQR. LSATC also largely outperforms other common generative models. Finally, we utilized a clustering algorithm to select 4 peptides from the 100 LSATC designed peptides for experimental validation. The result confirms that all the four peptides extended by LSATC show improved Beta-catenin binding by at least $20.0\%$, and two of the peptides show a $3$ fold increase in binding affinity as compared to the base peptide.
GenCos' Behaviors Modeling Based on Q Learning Improved by Dichotomy
Aug 04, 2020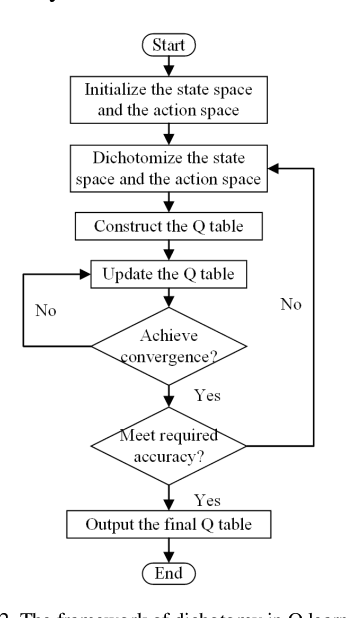
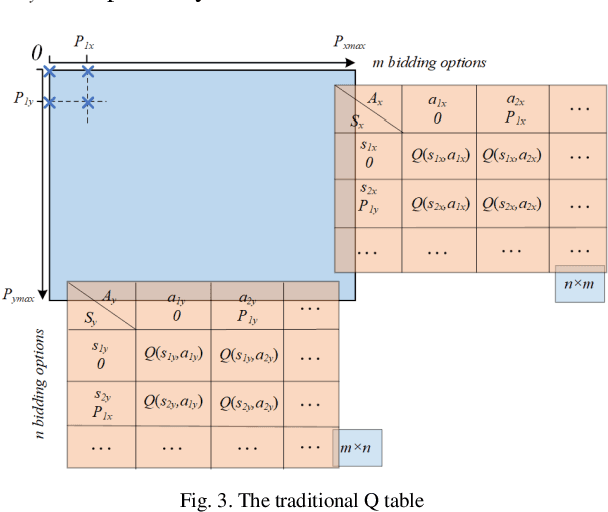

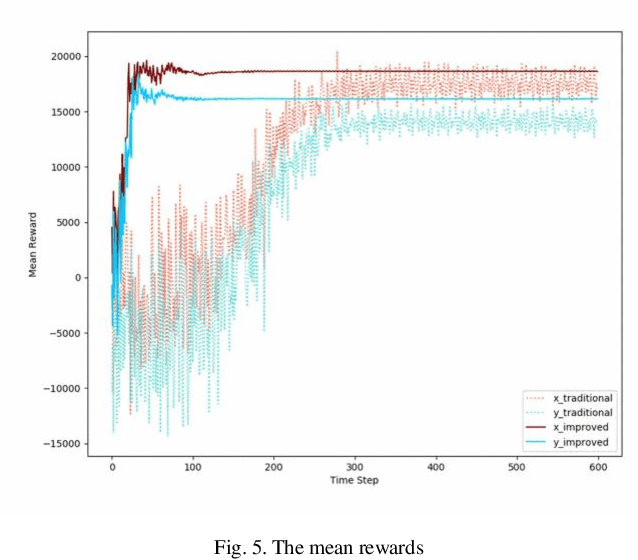
Q learning is widely used to simulate the behaviors of generation companies (GenCos) in an electricity market. However, existing Q learning method usually requires numerous iterations to converge, which is time-consuming and inefficient in practice. To enhance the calculation efficiency, a novel Q learning algorithm improved by dichotomy is proposed in this paper. This method modifies the update process of the Q table by dichotomizing the state space and the action space step by step. Simulation results in a repeated Cournot game show the effectiveness of the proposed algorithm.