 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Retrieval at Walmart
Dec 05, 2024



In product search, the retrieval of candidate products before re-ranking is more critical and challenging than other search like web search, especially for tail queries, which have a complex and specific search intent. In this paper, we present a hybrid system for e-commerce search deployed at Walmart that combines traditional inverted index and embedding-based neural retrieval to better answer user tail queries. Our system significantly improved the relevance of the search engine, measured by both offline and online evaluations. The improvements were achieved through a combination of different approaches. We present a new technique to train the neural model at scale. and describe how the system was deployed in production with little impact on response time. We highlight multiple learnings and practical tricks that were used in the deployment of this system.
Retrieval Augmented Correction of Named Entity Speech Recognition Errors
Sep 09, 2024
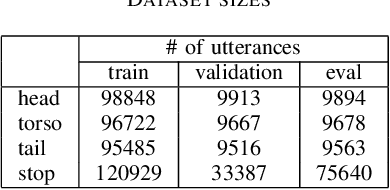
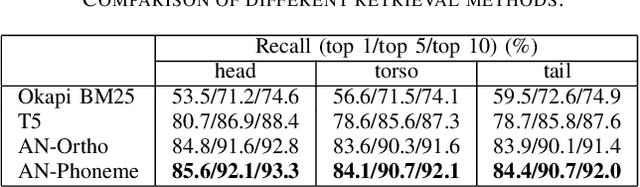
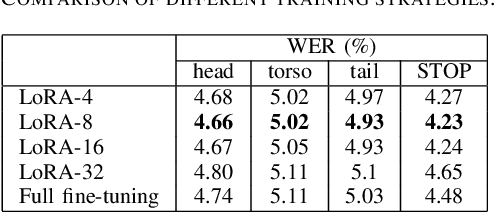
In recent years, end-to-end automatic speech recognition (ASR) systems have proven themselves remarkably accurate and performant, but these systems still have a significant error rate for entity names which appear infrequently in their training data. In parallel to the rise of end-to-end ASR systems, large language models (LLMs) have proven to be a versatile tool for various natural language processing (NLP) tasks. In NLP tasks where a database of relevant knowledge is available, retrieval augmented generation (RAG) has achieved impressive results when used with LLMs. In this work, we propose a RAG-like technique for correcting speech recognition entity name errors. Our approach uses a vector database to index a set of relevant entities. At runtime, database queries are generated from possibly errorful textual ASR hypotheses, and the entities retrieved using these queries are fed, along with the ASR hypotheses, to an LLM which has been adapted to correct ASR errors. Overall, our best system achieves 33%-39% relative word error rate reductions on synthetic test sets focused on voice assistant queries of rare music entities without regressing on the STOP test set, a publicly available voice assistant test set covering many domains.
ProTIP: Progressive Tool Retrieval Improves Planning
Dec 16, 2023Large language models (LLMs) are increasingly employed for complex multi-step planning tasks, where the tool retrieval (TR) step is crucial for achieving successful outcomes. Two prevalent approaches for TR are single-step retrieval, which utilizes the complete query, and sequential retrieval using task decomposition (TD), where a full query is segmented into discrete atomic subtasks. While single-step retrieval lacks the flexibility to handle "inter-tool dependency," the TD approach necessitates maintaining "subtask-tool atomicity alignment," as the toolbox can evolve dynamically. To address these limitations, we introduce the Progressive Tool retrieval to Improve Planning (ProTIP) framework. ProTIP is a lightweight, contrastive learning-based framework that implicitly performs TD without the explicit requirement of subtask labels, while simultaneously maintaining subtask-tool atomicity. On the ToolBench dataset, ProTIP outperforms the ChatGPT task decomposition-based approach by a remarkable margin, achieving a 24% improvement in Recall@K=10 for TR and a 41% enhancement in tool accuracy for plan generation.