 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAFARI: Scaling Long Horizon Agentic Fault Attribution via Active Investigation
Jun 23, 2026As autonomous agents tackle increasingly complex multi-step, multi-agent tasks, their execution trajectories have scaled beyond the constraints of even the largest context windows. Current methods for effectively diagnosing agent failures load the full trajectory into an LLM's context window, which suffers from attention dilution and fails when agentic traces inevitably exceed context limits. To address this, we introduce SAFARI (Scaling long-horizon Agentic Fault AttRibution via active Investigation), a framework that replaces linear context loading with a tool-augmented diagnostic loop. By equipping LLMs with a specialized toolbox to read and search trajectory segments alongside a persistent Short-Term Memory (STM) for cross-turn reasoning, SAFARI effectively decouples diagnostic accuracy from architectural context limits. Our experiments demonstrate that SAFARI outperforms state-of-the-art results by 20% on the Who&When dataset within a 1M token budget, and by 19% on TRAIL GAIA subset on a 25K token budget. Most significantly, SAFARI maintains a 0.58 precision even when the target fault resides 5x beyond the model's native context window, a scenario where traditional evaluators fail entirely.
Alignment-Weighted DPO: A principled reasoning approach to improve safety alignment
Feb 24, 2026Recent advances in alignment techniques such as Supervised Fine-Tuning (SFT), Reinforcement Learning from Human Feedback (RLHF), and Direct Preference Optimization (DPO) have improved the safety of large language models (LLMs). However, these LLMs remain vulnerable to jailbreak attacks that disguise harmful intent through indirect or deceptive phrasing. Using causal intervention, we empirically demonstrate that this vulnerability stems from shallow alignment mechanisms that lack deep reasoning, often rejecting harmful prompts without truly understanding why they are harmful. To mitigate this vulnerability, we propose enhancing alignment through reasoning-aware post-training. We construct and release a novel Chain-of-Thought (CoT) fine-tuning dataset that includes both utility-oriented and safety-critical prompts with step-by-step rationales. Fine-tuning on this dataset encourages models to produce principled refusals grounded in reasoning, outperforming standard SFT baselines. Furthermore, inspired by failure patterns in CoT fine-tuning, we introduce Alignment-Weighted DPO, which targets the most problematic parts of an output by assigning different preference weights to the reasoning and final-answer segments. This produces finer-grained, targeted updates than vanilla DPO and improves robustness to diverse jailbreak strategies. Extensive experiments across multiple safety and utility benchmarks show that our method consistently improves alignment robustness while maintaining overall model utility.
DF-RAG: Query-Aware Diversity for Retrieval-Augmented Generation
Jan 23, 2026Retrieval-augmented generation (RAG) is a common technique for grounding language model outputs in domain-specific information. However, RAG is often challenged by reasoning-intensive question-answering (QA), since common retrieval methods like cosine similarity maximize relevance at the cost of introducing redundant content, which can reduce information recall. To address this, we introduce Diversity-Focused Retrieval-Augmented Generation (DF-RAG), which systematically incorporates diversity into the retrieval step to improve performance on complex, reasoning-intensive QA benchmarks. DF-RAG builds upon the Maximal Marginal Relevance framework to select information chunks that are both relevant to the query and maximally dissimilar from each other. A key innovation of DF-RAG is its ability to optimize the level of diversity for each query dynamically at test time without requiring any additional fine-tuning or prior information. We show that DF-RAG improves F1 performance on reasoning-intensive QA benchmarks by 4-10 percent over vanilla RAG using cosine similarity and also outperforms other established baselines. Furthermore, we estimate an Oracle ceiling of up to 18 percent absolute F1 gains over vanilla RAG, of which DF-RAG captures up to 91.3 percent.
LLM Optimization Unlocks Real-Time Pairwise Reranking
Nov 10, 2025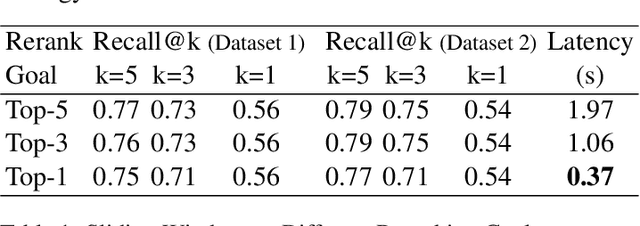



Efficiently reranking documents retrieved from information retrieval (IR) pipelines to enhance overall quality of Retrieval-Augmented Generation (RAG) system remains an important yet challenging problem. Recent studies have highlighted the importance of Large Language Models (LLMs) in reranking tasks. In particular, Pairwise Reranking Prompting (PRP) has emerged as a promising plug-and-play approach due to its usability and effectiveness. However, the inherent complexity of the algorithm, coupled with the high computational demands and latency incurred due to LLMs, raises concerns about its feasibility in real-time applications. To address these challenges, this paper presents a focused study on pairwise reranking, demonstrating that carefully applied optimization methods can significantly mitigate these issues. By implementing these methods, we achieve a remarkable latency reduction of up to 166 times, from 61.36 seconds to 0.37 seconds per query, with an insignificant drop in performance measured by Recall@k. Our study highlights the importance of design choices that were previously overlooked, such as using smaller models, limiting the reranked set, using lower precision, reducing positional bias with one-directional order inference, and restricting output tokens. These optimizations make LLM-based reranking substantially more efficient and feasible for latency-sensitive, real-world deployments.
Improving Consistency in Retrieval-Augmented Systems with Group Similarity Rewards
Oct 05, 2025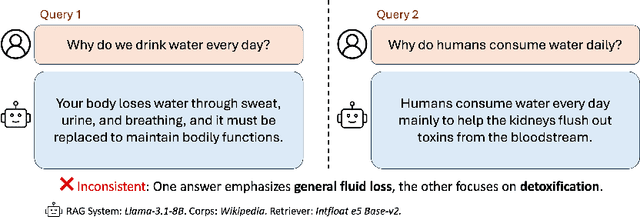
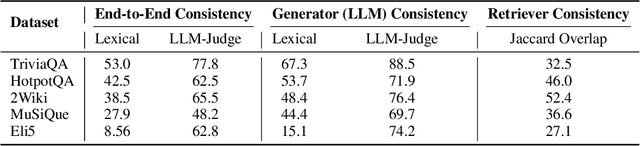
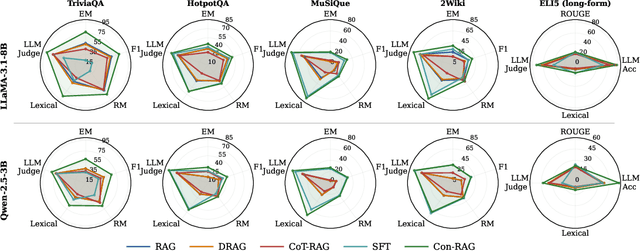
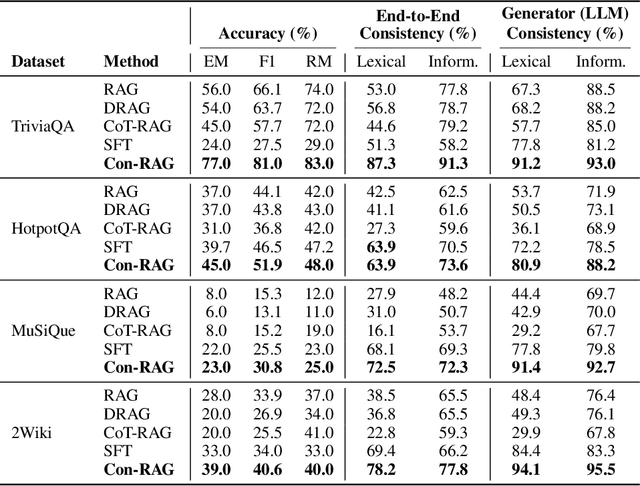
RAG systems are increasingly deployed in high-stakes domains where users expect outputs to be consistent across semantically equivalent queries. However, existing systems often exhibit significant inconsistencies due to variability in both the retriever and generator (LLM), undermining trust and reliability. In this work, we focus on information consistency, i.e., the requirement that outputs convey the same core content across semantically equivalent inputs. We introduce a principled evaluation framework that decomposes RAG consistency into retriever-level, generator-level, and end-to-end components, helping identify inconsistency sources. To improve consistency, we propose Paraphrased Set Group Relative Policy Optimization (PS-GRPO), an RL approach that leverages multiple rollouts across paraphrased set to assign group similarity rewards. We leverage PS-GRPO to achieve Information Consistent RAG (Con-RAG), training the generator to produce consistent outputs across paraphrased queries and remain robust to retrieval-induced variability. Because exact reward computation over paraphrase sets is computationally expensive, we also introduce a scalable approximation method that retains effectiveness while enabling efficient, large-scale training. Empirical evaluations across short-form, multi-hop, and long-form QA benchmarks demonstrate that Con-RAG significantly improves both consistency and accuracy over strong baselines, even in the absence of explicit ground-truth supervision. Our work provides practical solutions for evaluating and building reliable RAG systems for safety-critical deployments.
A Comparison of Independent and Joint Fine-tuning Strategies for Retrieval-Augmented Generation
Oct 02, 2025
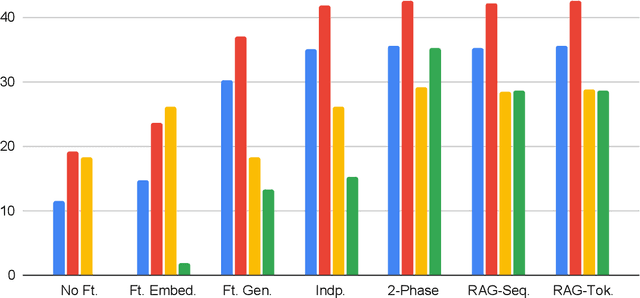


A Comparison of Independent and Joint Fine-tuning Strategies for Retrieval-Augmented Generation Download PDF Neal Gregory Lawton, Alfy Samuel, Anoop Kumar, Daben Liu Published: 20 Aug 2025, Last Modified: 17 Sept 2025EMNLP 2025 FindingsConference, Publication Chairs, AuthorsRevisionsBibTeXCC BY 4.0 Keywords: Retrieval-Augmented Generation (RAG), Large Language Models (LLMs), Fine-tuning, Question Answering, Joint fine-tuning TL;DR: We evaluate and compare strategies for fine-tuning Retrieval Augmented Generation (RAG) pipelines, including independent fine-tuning, joint fine-tuning, and two-phase fine-tuning. Abstract: Retrieval augmented generation (RAG) is a popular framework for question answering that is powered by two large language models (LLMs): an embedding model that retrieves context documents from a database that are relevant to a given question, and a generator model that uses the retrieved context to generate an answer to the question. Both the embedding and generator models can be fine-tuned to increase performance of a RAG pipeline on a new task, but multiple fine-tuning strategies exist with different costs and benefits. In this paper, we evaluate and compare several RAG fine-tuning strategies, including independent, joint, and two-phase fine-tuning. In our experiments, we observe that all of these strategies achieve about equal improvement in EM and F1 generation quality metrics, although they have significantly different computational costs. We conclude the optimal fine-tuning strategy to use depends on whether the training dataset includes context labels and whether a grid search over the learning rates for the embedding and generator models is required.
FB-RAG: Improving RAG with Forward and Backward Lookup
May 22, 2025The performance of Retrieval Augmented Generation (RAG) systems relies heavily on the retriever quality and the size of the retrieved context. A large enough context ensures that the relevant information is present in the input context for the LLM, but also incorporates irrelevant content that has been shown to confuse the models. On the other hand, a smaller context reduces the irrelevant information, but it often comes at the risk of losing important information necessary to answer the input question. This duality is especially challenging to manage for complex queries that contain little information to retrieve the relevant chunks from the full context. To address this, we present a novel framework, called FB-RAG, which enhances the RAG pipeline by relying on a combination of backward lookup (overlap with the query) and forward lookup (overlap with candidate reasons and answers) to retrieve specific context chunks that are the most relevant for answering the input query. Our evaluations on 9 datasets from two leading benchmarks show that FB-RAG consistently outperforms RAG and Long Context baselines developed recently for these benchmarks. We further show that FB-RAG can improve performance while reducing latency. We perform qualitative analysis of the strengths and shortcomings of our approach, providing specific insights to guide future work.
Refusal Tokens: A Simple Way to Calibrate Refusals in Large Language Models
Dec 09, 2024



A key component of building safe and reliable language models is enabling the models to appropriately refuse to follow certain instructions or answer certain questions. We may want models to output refusal messages for various categories of user queries, for example, ill-posed questions, instructions for committing illegal acts, or queries which require information past the model's knowledge horizon. Engineering models that refuse to answer such questions is complicated by the fact that an individual may want their model to exhibit varying levels of sensitivity for refusing queries of various categories, and different users may want different refusal rates. The current default approach involves training multiple models with varying proportions of refusal messages from each category to achieve the desired refusal rates, which is computationally expensive and may require training a new model to accommodate each user's desired preference over refusal rates. To address these challenges, we propose refusal tokens, one such token for each refusal category or a single refusal token, which are prepended to the model's responses during training. We then show how to increase or decrease the probability of generating the refusal token for each category during inference to steer the model's refusal behavior. Refusal tokens enable controlling a single model's refusal rates without the need of any further fine-tuning, but only by selectively intervening during generation.
Retrieval Augmented Correction of Named Entity Speech Recognition Errors
Sep 09, 2024
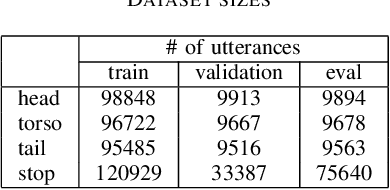
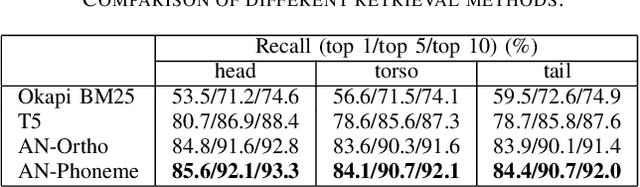
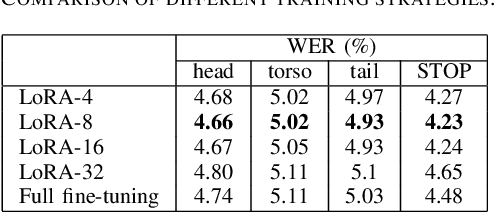
In recent years, end-to-end automatic speech recognition (ASR) systems have proven themselves remarkably accurate and performant, but these systems still have a significant error rate for entity names which appear infrequently in their training data. In parallel to the rise of end-to-end ASR systems, large language models (LLMs) have proven to be a versatile tool for various natural language processing (NLP) tasks. In NLP tasks where a database of relevant knowledge is available, retrieval augmented generation (RAG) has achieved impressive results when used with LLMs. In this work, we propose a RAG-like technique for correcting speech recognition entity name errors. Our approach uses a vector database to index a set of relevant entities. At runtime, database queries are generated from possibly errorful textual ASR hypotheses, and the entities retrieved using these queries are fed, along with the ASR hypotheses, to an LLM which has been adapted to correct ASR errors. Overall, our best system achieves 33%-39% relative word error rate reductions on synthetic test sets focused on voice assistant queries of rare music entities without regressing on the STOP test set, a publicly available voice assistant test set covering many domains.
Exploring Retraining-Free Speech Recognition for Intra-sentential Code-Switching
Aug 27, 2021
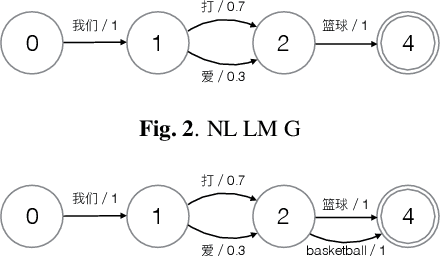
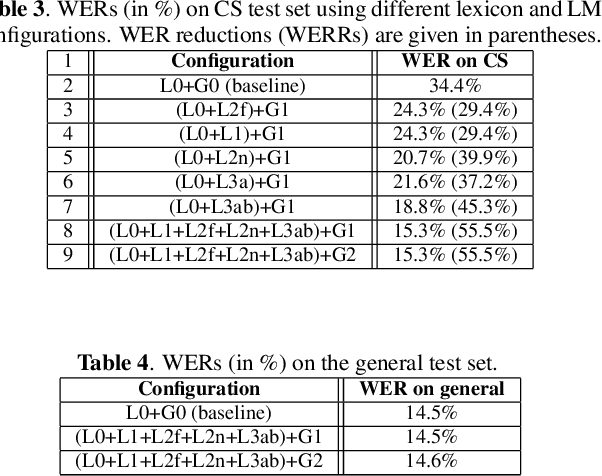
In this paper, we present our initial efforts for building a code-switching (CS) speech recognition system leveraging existing acoustic models (AMs) and language models (LMs), i.e., no training required, and specifically targeting intra-sentential switching. To achieve such an ambitious goal, new mechanisms for foreign pronunciation generation and language model (LM) enrichment have been devised. Specifically, we have designed an automatic approach to obtain high quality pronunciation of foreign language (FL) words in the native language (NL) phoneme set using existing acoustic phone decoders and an LSTM-based grapheme-to-phoneme (G2P) model. Improved accented pronunciations have thus been obtained by learning foreign pronunciations directly from data. Furthermore, a code-switching LM was deployed by converting the original NL LM into a CS LM using translated word pairs and borrowing statistics for the NL LM. Experimental evidence clearly demonstrates that our approach better deals with accented foreign pronunciations than techniques based on human labeling. Moreover, our best system achieves a 55.5% relative word error rate reduction from 34.4%, obtained with a conventional monolingual ASR system, to 15.3% on an intra-sentential CS task without harming the monolingual recognition accuracy.