 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmental Attention Decoding With Long Form Acoustic Encodings
Dec 16, 2025

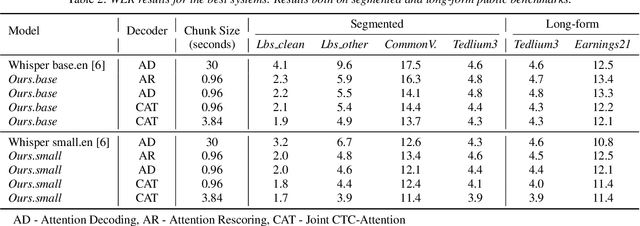
We address the fundamental incompatibility of attention-based encoder-decoder (AED) models with long-form acoustic encodings. AED models trained on segmented utterances learn to encode absolute frame positions by exploiting limited acoustic context beyond segment boundaries, but fail to generalize when decoding long-form segments where these cues vanish. The model loses ability to order acoustic encodings due to permutation invariance of keys and values in cross-attention. We propose four modifications: (1) injecting explicit absolute positional encodings into cross-attention for each decoded segment, (2) long-form training with extended acoustic context to eliminate implicit absolute position encoding, (3) segment concatenation to cover diverse segmentations needed during training, and (4) semantic segmentation to align AED-decoded segments with training segments. We show these modifications close the accuracy gap between continuous and segmented acoustic encodings, enabling auto-regressive use of the attention decoder.
EEG-DBNet: A Dual-Branch Network for Temporal-Spectral Decoding in Motor-Imagery Brain-Computer Interfaces
May 30, 2024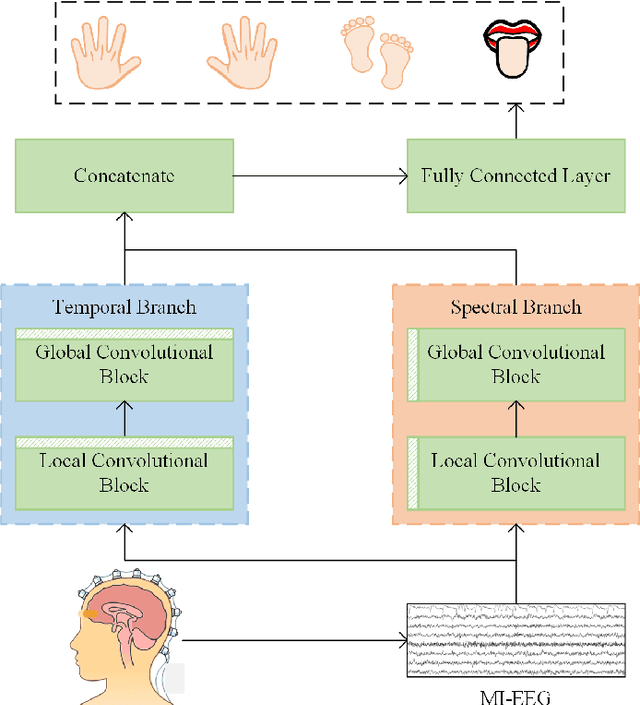
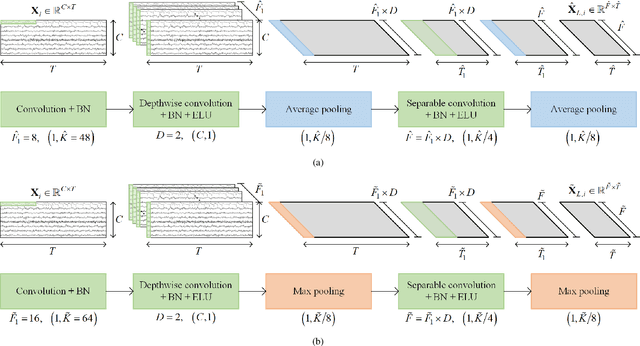
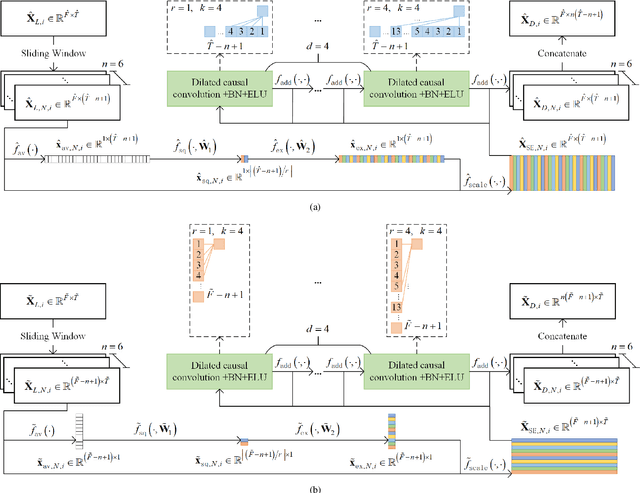

Motor imagery electroencephalogram (EEG)-based brain-computer interfaces (BCIs) offer significant advantages for individuals with restricted limb mobility. However, challenges such as low signal-to-noise ratio and limited spatial resolution impede accurate feature extraction from EEG signals, thereby affecting the classification accuracy of different actions. To address these challenges, this study proposes an end-to-end dual-branch network (EEG-DBNet) that decodes the temporal and spectral sequences of EEG signals in parallel through two distinct network branches. Each branch comprises a local convolutional block and a global convolutional block. The local convolutional block transforms the source signal from the temporal-spatial domain to the temporal-spectral domain. By varying the number of filters and convolution kernel sizes, the local convolutional blocks in different branches adjust the length of their respective dimension sequences. Different types of pooling layers are then employed to emphasize the features of various dimension sequences, setting the stage for subsequent global feature extraction. The global convolution block splits and reconstructs the feature of the signal sequence processed by the local convolution block in the same branch and further extracts features through the dilated causal convolutional neural networks. Finally, the outputs from the two branches are concatenated, and signal classification is completed via a fully connected layer. Our proposed method achieves classification accuracies of 85.84% and 91.60% on the BCI Competition 4-2a and BCI Competition 4-2b datasets, respectively, surpassing existing state-of-the-art models. The source code is available at https://github.com/xicheng105/EEG-DBNet.
Gradable ChatGPT Translation Evaluation
Jan 18, 2024ChatGPT, as a language model based on large-scale pre-training, has exerted a profound influence on the domain of machine translation. In ChatGPT, a "Prompt" refers to a segment of text or instruction employed to steer the model towards generating a specific category of response. The design of the translation prompt emerges as a key aspect that can wield influence over factors such as the style, precision and accuracy of the translation to a certain extent. However, there is a lack of a common standard and methodology on how to design and select a translation prompt. Accordingly, this paper proposes a generic taxonomy, which defines gradable translation prompts in terms of expression type, translation style, POS information and explicit statement, thus facilitating the construction of prompts endowed with distinct attributes tailored for various translation tasks. Specific experiments and cases are selected to validate and illustrate the effectiveness of the method.
Unlock the Power: Competitive Distillation for Multi-Modal Large Language Models
Nov 14, 2023



Recently, multi-modal content generation has attracted lots of attention from researchers by investigating the utilization of visual instruction tuning based on large language models (LLMs). To enhance the performance and generalization ability of such LLMs, the practice of distilling knowledge from pretrained multi-modal models (a.k.a. teachers) to more compact multi-modal LLMs (students) has gained considerable interest. However, the prevailing paradigm of instructiontuning in multi-modal LLMs knowledge distillation is resource-intensive and unidirectional, neglecting the potential for mutual feedback between the student and teacher models. Thus, we propose an innovative Competitive Multi-modal Distillation framework (CoMD), which captures bidirectional feedback between teacher and student models and continually updates the multi-modal capabilities that the student model has learned. It comprises two stages: multi-modal pre-training and multi-modal competitive distillation. The first stage pre-trains the student model on a large number of filtered multi-modal datasets. The second stage facilitates a bidirectional knowledge transfer between the student and teacher models. Our experimental analysis of diverse datasets shows that our knowledge transfer method consistently improves the capabilities of the student model. Finally, the 7B-sized student model after four distillations surpassed the current state-of-the-art model LLaVA-13B on the ScienceQA and LLaVA Test dataset, also outperforms other strong baselines in the zero-shot setting.
Frame-level SpecAugment for Deep Convolutional Neural Networks in Hybrid ASR Systems
Dec 07, 2020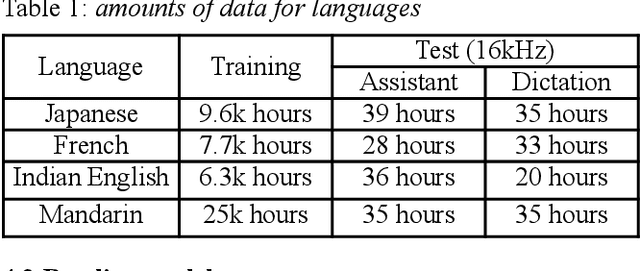
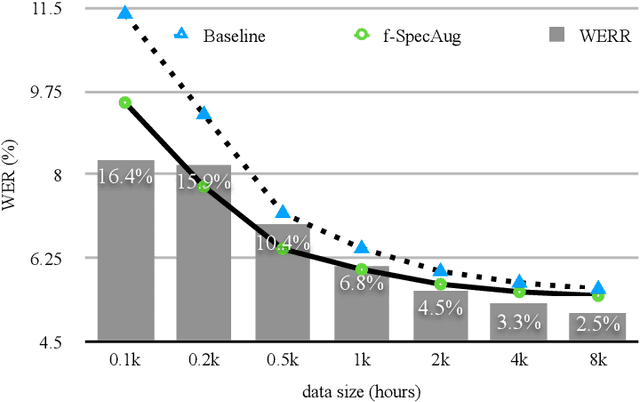
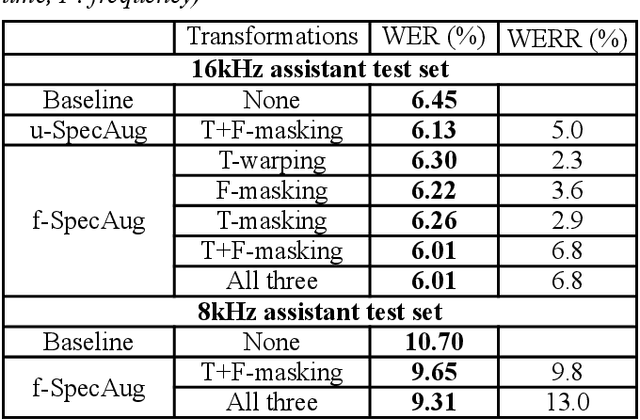
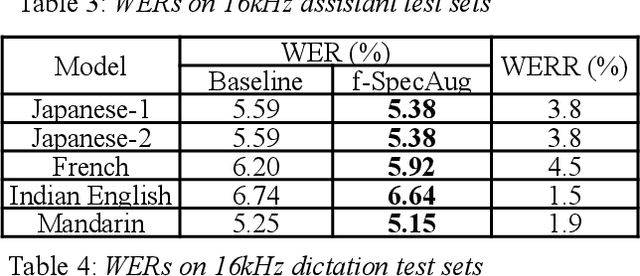
Inspired by SpecAugment -- a data augmentation method for end-to-end ASR systems, we propose a frame-level SpecAugment method (f-SpecAugment) to improve the performance of deep convolutional neural networks (CNN) for hybrid HMM based ASR systems. Similar to the utterance level SpecAugment, f-SpecAugment performs three transformations: time warping, frequency masking, and time masking. Instead of applying the transformations at the utterance level, f-SpecAugment applies them to each convolution window independently during training. We demonstrate that f-SpecAugment is more effective than the utterance level SpecAugment for deep CNN based hybrid models. We evaluate the proposed f-SpecAugment on 50-layer Self-Normalizing Deep CNN (SNDCNN) acoustic models trained with up to 25000 hours of training data. We observe f-SpecAugment reduces WER by 0.5-4.5% relatively across different ASR tasks for four languages. As the benefits of augmentation techniques tend to diminish as training data size increases, the large scale training reported is important in understanding the effectiveness of f-SpecAugment. Our experiments demonstrate that even with 25k training data, f-SpecAugment is still effective. We also demonstrate that f-SpecAugment has benefits approximately equivalent to doubling the amount of training data for deep CNNs.
Class LM and word mapping for contextual biasing in End-to-End ASR
Jul 10, 2020
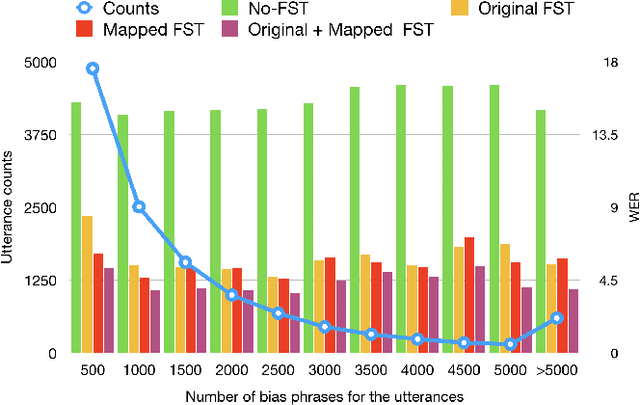
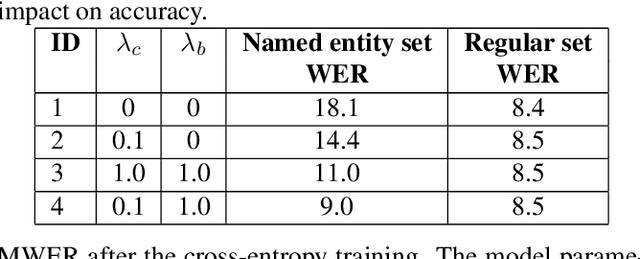
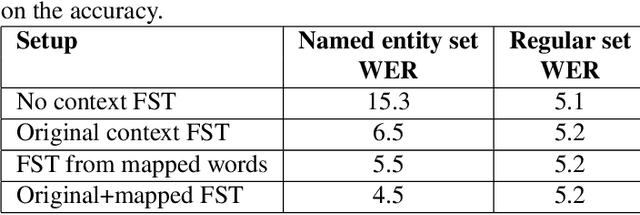
In recent years, all-neural, end-to-end (E2E) ASR systems gained rapid interest in the speech recognition community. They convert speech input to text units in a single trainable Neural Network model. In ASR, many utterances contain rich named entities. Such named entities may be user or location specific and they are not seen during training. A single model makes it inflexible to utilize dynamic contextual information during inference. In this paper, we propose to train a context aware E2E model and allow the beam search to traverse into the context FST during inference. We also propose a simple method to adjust the cost discrepancy between the context FST and the base model. This algorithm is able to reduce the named entity utterance WER by 57% with little accuracy degradation on regular utterances. Although an E2E model does not need pronunciation dictionary, it's interesting to make use of existing pronunciation knowledge to improve accuracy. In this paper, we propose an algorithm to map the rare entity words to common words via pronunciation and treat the mapped words as an alternative form to the original word during recognition. This algorithm further reduces the WER on the named entity utterances by another 31%.
Automatic marker-free registration of tree point-cloud data based on rotating projection
Jan 30, 2020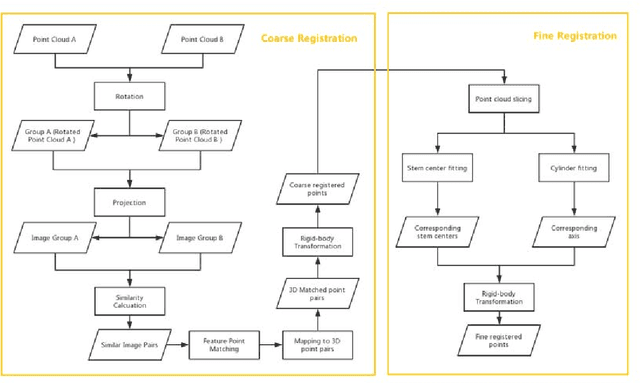

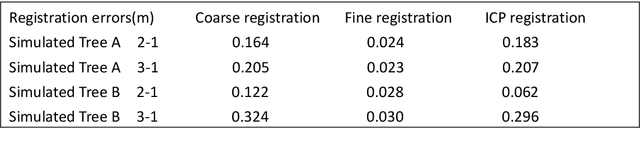
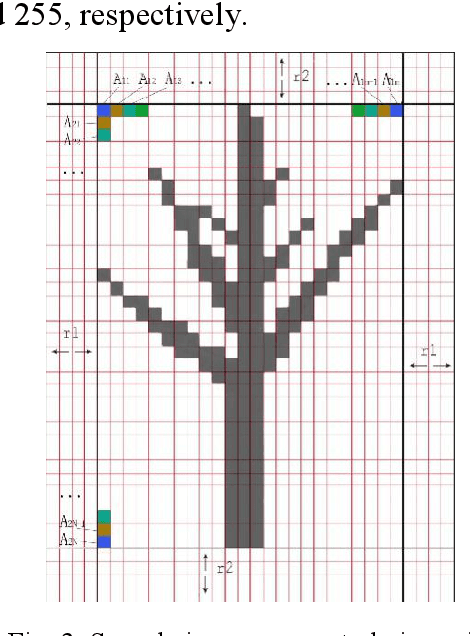
Point-cloud data acquired using a terrestrial laser scanner (TLS) play an important role in digital forestry research. Multiple scans are generally used to overcome occlusion effects and obtain complete tree structural information. However, it is time-consuming and difficult to place artificial reflectors in a forest with complex terrain for marker-based registration, a process that reduces registration automation and efficiency. In this study, we propose an automatic coarse-to-fine method for the registration of point-cloud data from multiple scans of a single tree. In coarse registration, point clouds produced by each scan are projected onto a spherical surface to generate a series of two-dimensional (2D) images, which are used to estimate the initial positions of multiple scans. Corresponding feature-point pairs are then extracted from these series of 2D images. In fine registration, point-cloud data slicing and fitting methods are used to extract corresponding central stem and branch centers for use as tie points to calculate fine transformation parameters. To evaluate the accuracy of registration results, we propose a model of error evaluation via calculating the distances between center points from corresponding branches in adjacent scans. For accurate evaluation, we conducted experiments on two simulated trees and a real-world tree. Average registration errors of the proposed method were 0.26m around on simulated tree point clouds, and 0.05m around on real-world tree point cloud.
Listen, Attend, Spell and Adapt: Speaker Adapted Sequence-to-Sequence ASR
Jul 08, 2019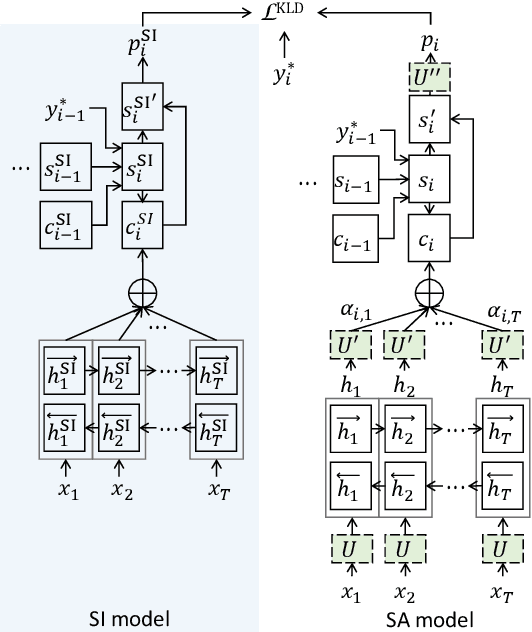
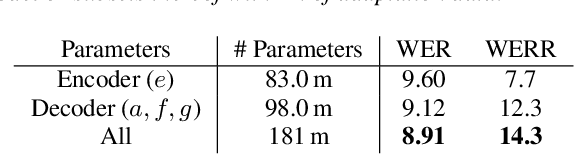

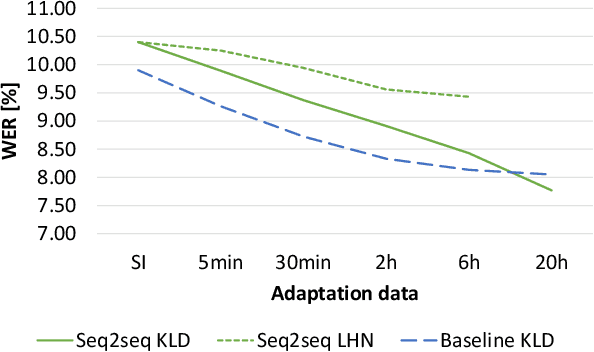
Sequence-to-sequence (seq2seq) based ASR systems have shown state-of-the-art performances while having clear advantages in terms of simplicity. However, comparisons are mostly done on speaker independent (SI) ASR systems, though speaker adapted conventional systems are commonly used in practice for improving robustness to speaker and environment variations. In this paper, we apply speaker adaptation to seq2seq models with the goal of matching the performance of conventional ASR adaptation. Specifically, we investigate Kullback-Leibler divergence (KLD) as well as Linear Hidden Network (LHN) based adaptation for seq2seq ASR, using different amounts (up to 20 hours) of adaptation data per speaker. Our SI models are trained on large amounts of dictation data and achieve state-of-the-art results. We obtained 25% relative word error rate (WER) improvement with KLD adaptation of the seq2seq model vs. 18.7% gain from acoustic model adaptation in the conventional system. We also show that the WER of the seq2seq model decreases log-linearly with the amount of adaptation data. Finally, we analyze adaptation based on the minimum WER criterion and adapting the language model (LM) for score fusion with the speaker adapted seq2seq model, which result in further improvements of the seq2seq system performance.