 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradable ChatGPT Translation Evaluation
Jan 18, 2024ChatGPT, as a language model based on large-scale pre-training, has exerted a profound influence on the domain of machine translation. In ChatGPT, a "Prompt" refers to a segment of text or instruction employed to steer the model towards generating a specific category of response. The design of the translation prompt emerges as a key aspect that can wield influence over factors such as the style, precision and accuracy of the translation to a certain extent. However, there is a lack of a common standard and methodology on how to design and select a translation prompt. Accordingly, this paper proposes a generic taxonomy, which defines gradable translation prompts in terms of expression type, translation style, POS information and explicit statement, thus facilitating the construction of prompts endowed with distinct attributes tailored for various translation tasks. Specific experiments and cases are selected to validate and illustrate the effectiveness of the method.
Parallel Hierarchical Transformer with Attention Alignment for Abstractive Multi-Document Summarization
Aug 16, 2022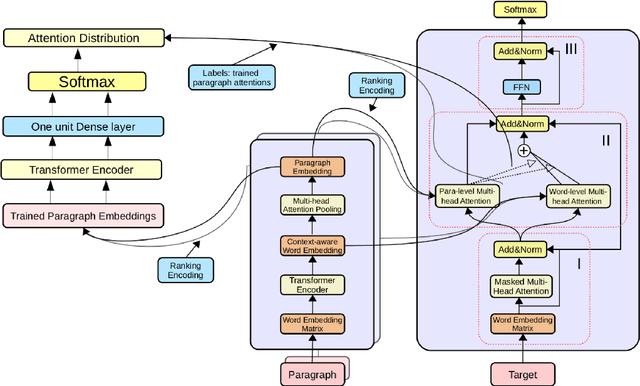
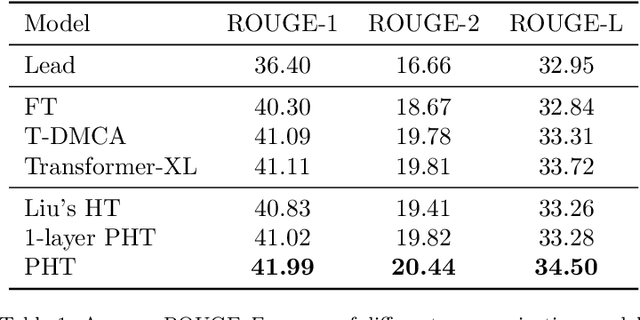

In comparison to single-document summarization, abstractive Multi-Document Summarization (MDS) brings challenges on the representation and coverage of its lengthy and linked sources. This study develops a Parallel Hierarchical Transformer (PHT) with attention alignment for MDS. By incorporating word- and paragraph-level multi-head attentions, the hierarchical architecture of PHT allows better processing of dependencies at both token and document levels. To guide the decoding towards a better coverage of the source documents, the attention-alignment mechanism is then introduced to calibrate beam search with predicted optimal attention distributions. Based on the WikiSum data, a comprehensive evaluation is conducted to test improvements on MDS by the proposed architecture. By better handling the inner- and cross-document information, results in both ROUGE and human evaluation suggest that our hierarchical model generates summaries of higher quality relative to other Transformer-based baselines at relatively low computational cost.
Attention-Aware Inference for Neural Abstractive Summarization
Sep 15, 2020
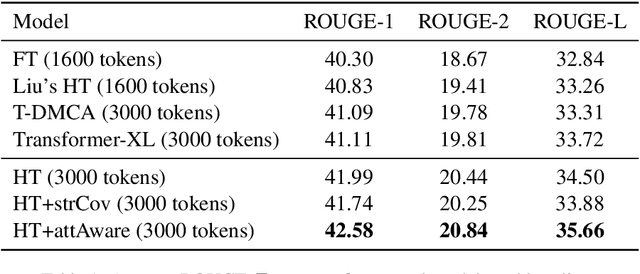

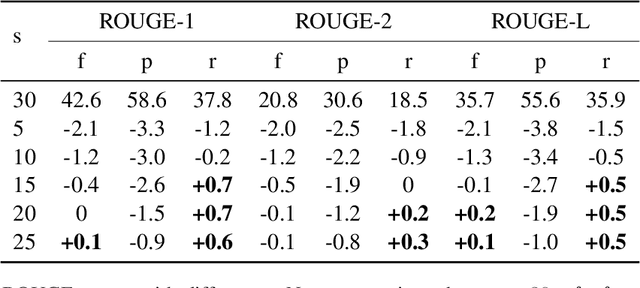
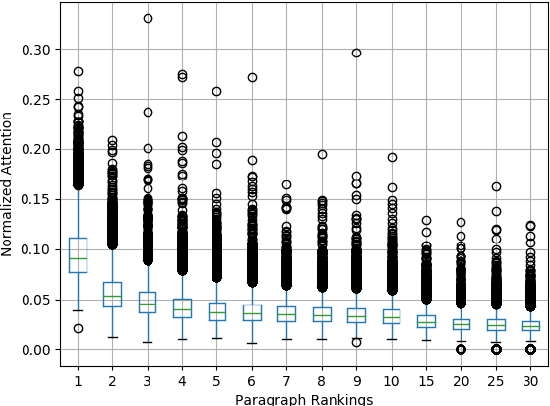
Inspired by Google's Neural Machine Translation (NMT) \cite{Wu2016Google} that models the one-to-one alignment in translation tasks with an optimal uniform attention distribution during the inference, this study proposes an attention-aware inference algorithm for Neural Abstractive Summarization (NAS) to regulate generated summaries to attend to source paragraphs/sentences with the optimal coverage. Unlike NMT, the attention-aware inference of NAS requires the prediction of the optimal attention distribution. Therefore, an attention-prediction model is constructed to learn the dependency between attention weights and sources. To apply the attention-aware inference on multi-document summarization, a Hierarchical Transformer (HT) is developed to accept lengthy inputs at the same time project cross-document information. Experiments on WikiSum \cite{liu2018generating} suggest that the proposed HT already outperforms other strong Transformer-based baselines. By refining the regular beam search with the attention-aware inference, significant improvements on the quality of summaries could be further observed. Last but not the least, the attention-aware inference could be adopted to single-document summarization with straightforward modifications according to the model architecture.
A Novel Distributed Representation of News (DRNews) for Stock Market Predictions
May 24, 2020
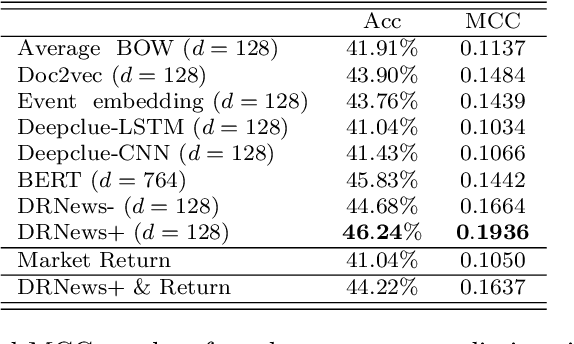
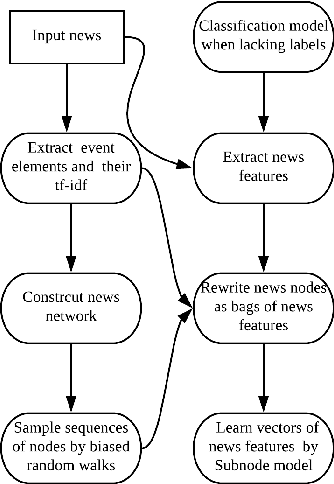
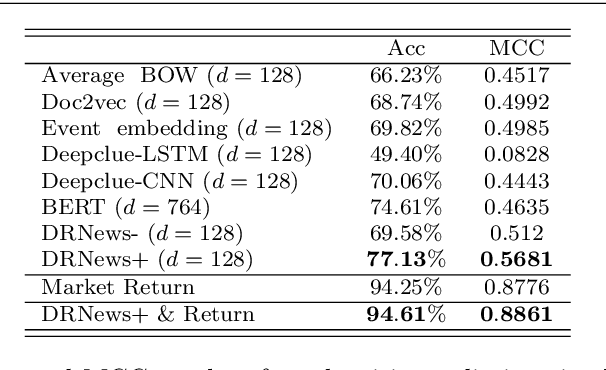
In this study, a novel Distributed Representation of News (DRNews) model is developed and applied in deep learning-based stock market predictions. With the merit of integrating contextual information and cross-documental knowledge, the DRNews model creates news vectors that describe both the semantic information and potential linkages among news events through an attributed news network. Two stock market prediction tasks, namely the short-term stock movement prediction and stock crises early warning, are implemented in the framework of the attention-based Long Short Term-Memory (LSTM) network. It is suggested that DRNews substantially enhances the results of both tasks comparing with five baselines of news embedding models. Further, the attention mechanism suggests that short-term stock trend and stock market crises both receive influences from daily news with the former demonstrates more critical responses on the information related to the stock market {\em per se}, whilst the latter draws more concerns on the banking sector and economic policies.
Integrated Node Encoder for Labelled Textual Networks
May 24, 2020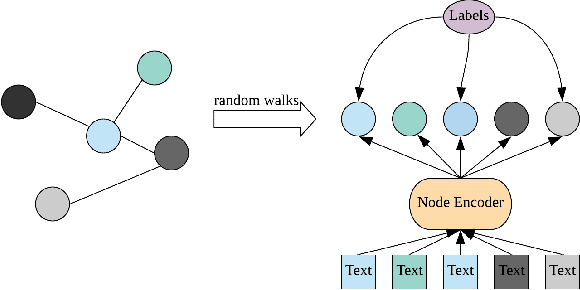
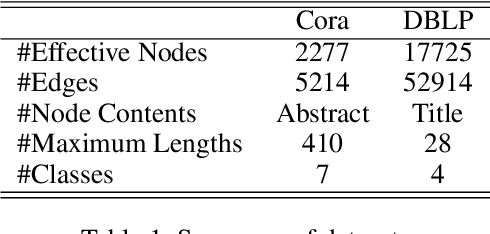
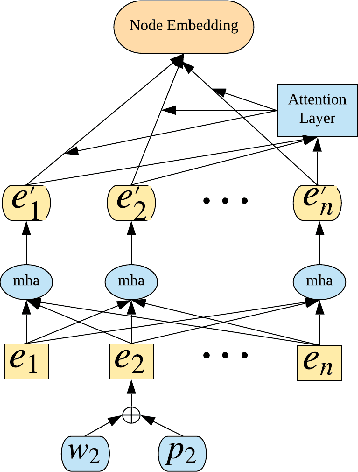
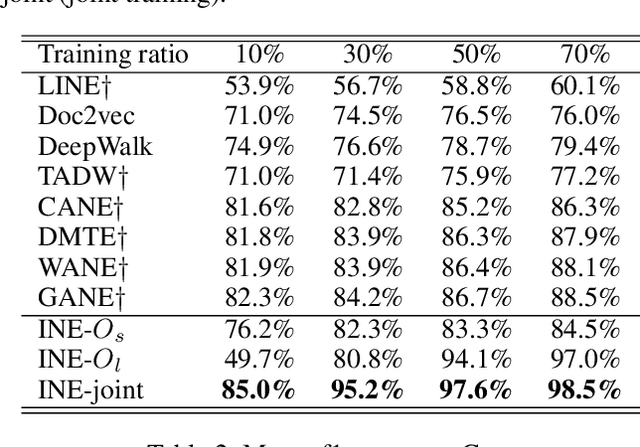
Voluminous works have been implemented to exploit content-enhanced network embedding models, with little focus on the labelled information of nodes. Although TriDNR leverages node labels by treating them as node attributes, it fails to enrich unlabelled node vectors with the labelled information, which leads to the weaker classification result on the test set in comparison to existing unsupervised textual network embedding models. In this study, we design an integrated node encoder (INE) for textual networks which is jointly trained on the structure-based and label-based objectives. As a result, the node encoder preserves the integrated knowledge of not only the network text and structure, but also the labelled information. Furthermore, INE allows the creation of label-enhanced vectors for unlabelled nodes by entering their node contents. Our node embedding achieves state-of-the-art performances in the classification task on two public citation networks, namely Cora and DBLP, pushing benchmarks up by 10.0\% and 12.1\%, respectively, with the 70\% training ratio. Additionally, a feasible solution that generalizes our model from textual networks to a broader range of networks is proposed.