 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWenetSpeech-Wu: Datasets, Benchmarks, and Models for a Unified Chinese Wu Dialect Speech Processing Ecosystem
Jan 16, 2026Speech processing for low-resource dialects remains a fundamental challenge in developing inclusive and robust speech technologies. Despite its linguistic significance and large speaker population, the Wu dialect of Chinese has long been hindered by the lack of large-scale speech data, standardized evaluation benchmarks, and publicly available models. In this work, we present WenetSpeech-Wu, the first large-scale, multi-dimensionally annotated open-source speech corpus for the Wu dialect, comprising approximately 8,000 hours of diverse speech data. Building upon this dataset, we introduce WenetSpeech-Wu-Bench, the first standardized and publicly accessible benchmark for systematic evaluation of Wu dialect speech processing, covering automatic speech recognition (ASR), Wu-to-Mandarin translation, speaker attribute prediction, speech emotion recognition, text-to-speech (TTS) synthesis, and instruction-following TTS (instruct TTS). Furthermore, we release a suite of strong open-source models trained on WenetSpeech-Wu, establishing competitive performance across multiple tasks and empirically validating the effectiveness of the proposed dataset. Together, these contributions lay the foundation for a comprehensive Wu dialect speech processing ecosystem, and we open-source proposed datasets, benchmarks, and models to support future research on dialectal speech intelligence.
Gradable ChatGPT Translation Evaluation
Jan 18, 2024ChatGPT, as a language model based on large-scale pre-training, has exerted a profound influence on the domain of machine translation. In ChatGPT, a "Prompt" refers to a segment of text or instruction employed to steer the model towards generating a specific category of response. The design of the translation prompt emerges as a key aspect that can wield influence over factors such as the style, precision and accuracy of the translation to a certain extent. However, there is a lack of a common standard and methodology on how to design and select a translation prompt. Accordingly, this paper proposes a generic taxonomy, which defines gradable translation prompts in terms of expression type, translation style, POS information and explicit statement, thus facilitating the construction of prompts endowed with distinct attributes tailored for various translation tasks. Specific experiments and cases are selected to validate and illustrate the effectiveness of the method.
Alternative Telescopic Displacement: An Efficient Multimodal Alignment Method
Jun 29, 2023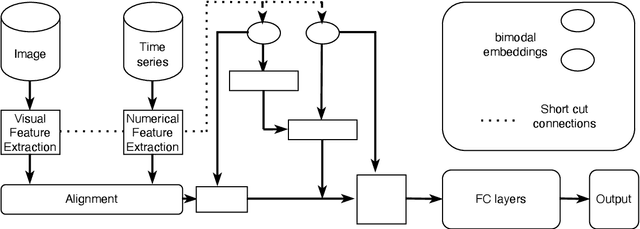
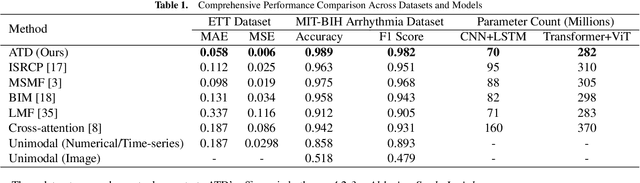
Feature alignment is the primary means of fusing multimodal data. We propose a feature alignment method that fully fuses multimodal information, which alternately shifts and expands feature information from different modalities to have a consistent representation in a feature space. The proposed method can robustly capture high-level interactions between features of different modalities, thus significantly improving the performance of multimodal learning. We also show that the proposed method outperforms other popular multimodal schemes on multiple tasks. Experimental evaluation of ETT and MIT-BIH-Arrhythmia, datasets shows that the proposed method achieves state of the art performance.
Semi-automatic Simultaneous Interpreting Quality Evaluation
Nov 12, 2016



Increasing interpreting needs a more objective and automatic measurement. We hold a basic idea that 'translating means translating meaning' in that we can assessment interpretation quality by comparing the meaning of the interpreting output with the source input. That is, a translation unit of a 'chunk' named Frame which comes from frame semantics and its components named Frame Elements (FEs) which comes from Frame Net are proposed to explore their matching rate between target and source texts. A case study in this paper verifies the usability of semi-automatic graded semantic-scoring measurement for human simultaneous interpreting and shows how to use frame and FE matches to score. Experiments results show that the semantic-scoring metrics have a significantly correlation coefficient with human judgment.
Automatic Construction of Discourse Corpora for Dialogue Translation
May 22, 2016


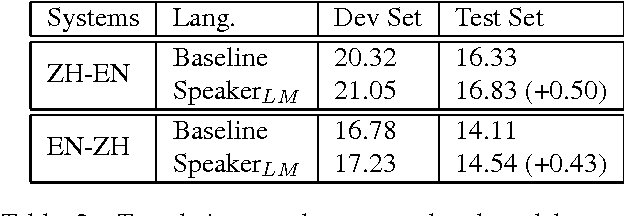
In this paper, a novel approach is proposed to automatically construct parallel discourse corpus for dialogue machine translation. Firstly, the parallel subtitle data and its corresponding monolingual movie script data are crawled and collected from Internet. Then tags such as speaker and discourse boundary from the script data are projected to its subtitle data via an information retrieval approach in order to map monolingual discourse to bilingual texts. We not only evaluate the mapping results, but also integrate speaker information into the translation. Experiments show our proposed method can achieve 81.79% and 98.64% accuracy on speaker and dialogue boundary annotation, and speaker-based language model adaptation can obtain around 0.5 BLEU points improvement in translation qualities. Finally, we publicly release around 100K parallel discourse data with manual speaker and dialogue boundary annotation.
A Novel Approach to Dropped Pronoun Translation
Apr 21, 2016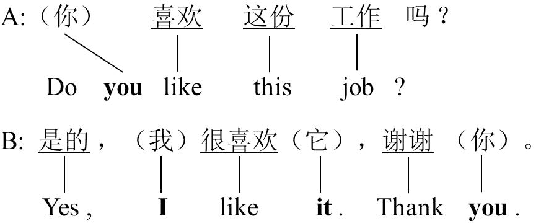
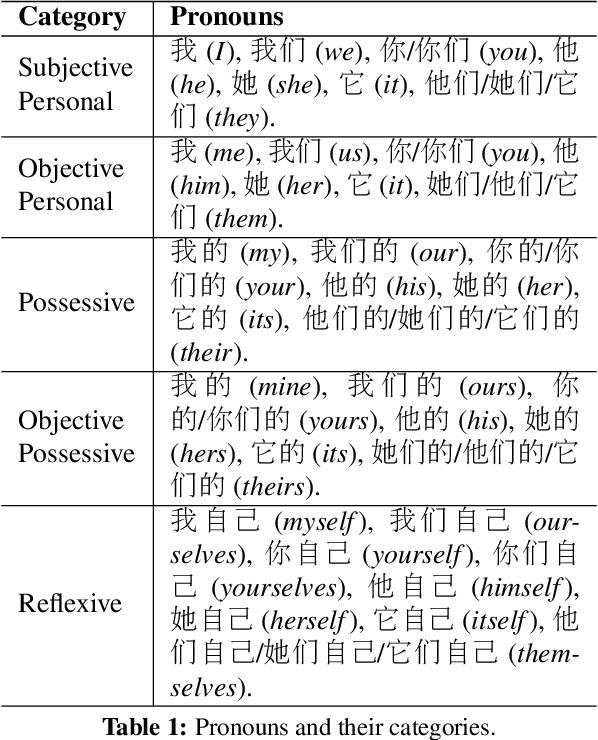
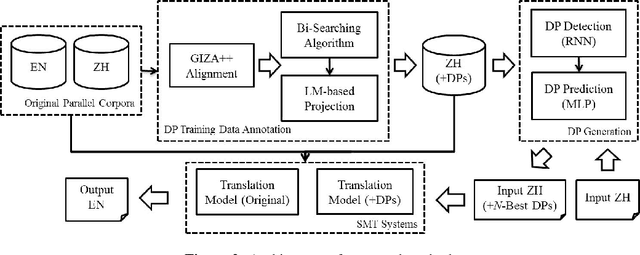
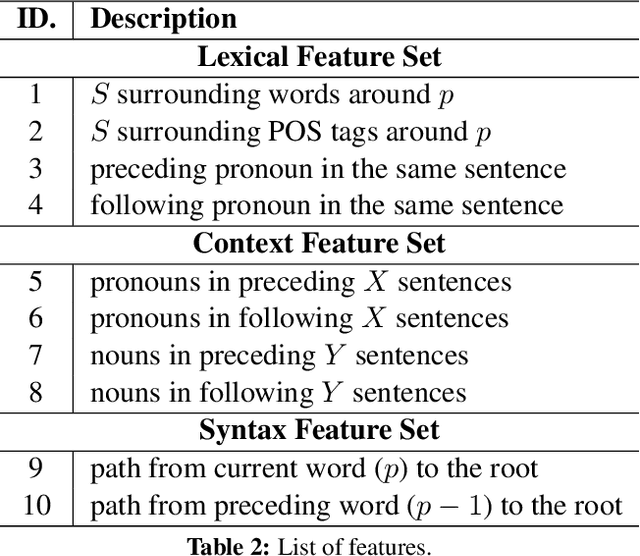
Dropped Pronouns (DP) in which pronouns are frequently dropped in the source language but should be retained in the target language are challenge in machine translation. In response to this problem, we propose a semi-supervised approach to recall possibly missing pronouns in the translation. Firstly, we build training data for DP generation in which the DPs are automatically labelled according to the alignment information from a parallel corpus. Secondly, we build a deep learning-based DP generator for input sentences in decoding when no corresponding references exist. More specifically, the generation is two-phase: (1) DP position detection, which is modeled as a sequential labelling task with recurrent neural networks; and (2) DP prediction, which employs a multilayer perceptron with rich features. Finally, we integrate the above outputs into our translation system to recall missing pronouns by both extracting rules from the DP-labelled training data and translating the DP-generated input sentences. Experimental results show that our approach achieves a significant improvement of 1.58 BLEU points in translation performance with 66% F-score for DP generation accuracy.