 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Construction of Discourse Corpora for Dialogue Translation
Paper and Code
May 22, 2016


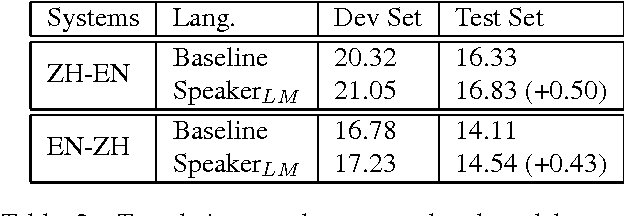
In this paper, a novel approach is proposed to automatically construct parallel discourse corpus for dialogue machine translation. Firstly, the parallel subtitle data and its corresponding monolingual movie script data are crawled and collected from Internet. Then tags such as speaker and discourse boundary from the script data are projected to its subtitle data via an information retrieval approach in order to map monolingual discourse to bilingual texts. We not only evaluate the mapping results, but also integrate speaker information into the translation. Experiments show our proposed method can achieve 81.79% and 98.64% accuracy on speaker and dialogue boundary annotation, and speaker-based language model adaptation can obtain around 0.5 BLEU points improvement in translation qualities. Finally, we publicly release around 100K parallel discourse data with manual speaker and dialogue boundary annotation.