 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTS-PLL: A Robust and Anytime Framework for Collaborative Task Sequencing and Multi-Agent Path Finding
Mar 26, 2026The Collaborative Task Sequencing and Multi-Agent Path Finding (CTS-MAPF) problem requires agents to accomplish sequences of tasks while avoiding collisions, posing significant challenges due to its combinatorial complexity. This work introduces CTS-PLL, a hierarchical framework that extends the configuration-based CTS-MAPF planning paradigm with two key enhancements: a lock agents detection and release mechanism leveraging a complete planning method for local re-planning, and an anytime refinement procedure based on Large Neighborhood Search (LNS). These additions ensure robustness in dense environments and enable continuous improvement of solution quality. Extensive evaluations across sparse and dense benchmarks demonstrate that CTS-PLL achieves higher success rates and solution quality compared with existing methods, while maintaining competitive runtime efficiency. Real-world robot experiments further demonstrate the feasibility of the approach in practice.
The Illusion of Specialization: Unveiling the Domain-Invariant "Standing Committee" in Mixture-of-Experts Models
Jan 06, 2026Mixture of Experts models are widely assumed to achieve domain specialization through sparse routing. In this work, we question this assumption by introducing COMMITTEEAUDIT, a post hoc framework that analyzes routing behavior at the level of expert groups rather than individual experts. Across three representative models and the MMLU benchmark, we uncover a domain-invariant Standing Committee. This is a compact coalition of routed experts that consistently captures the majority of routing mass across domains, layers, and routing budgets, even when architectures already include shared experts. Qualitative analysis further shows that Standing Committees anchor reasoning structure and syntax, while peripheral experts handle domain-specific knowledge. These findings reveal a strong structural bias toward centralized computation, suggesting that specialization in Mixture of Experts models is far less pervasive than commonly believed. This inherent bias also indicates that current training objectives, such as load-balancing losses that enforce uniform expert utilization, may be working against the model's natural optimization path, thereby limiting training efficiency and performance.
Investigating Data Pruning for Pretraining Biological Foundation Models at Scale
Dec 15, 2025Biological foundation models (BioFMs), pretrained on large-scale biological sequences, have recently shown strong potential in providing meaningful representations for diverse downstream bioinformatics tasks. However, such models often rely on millions to billions of training sequences and billions of parameters, resulting in prohibitive computational costs and significant barriers to reproducibility and accessibility, particularly for academic labs. To address these challenges, we investigate the feasibility of data pruning for BioFM pretraining and propose a post-hoc influence-guided data pruning framework tailored to biological domains. Our approach introduces a subset-based self-influence formulation that enables efficient estimation of sample importance at low computational cost, and builds upon it two simple yet effective selection strategies, namely Top-k Influence (Top I) and Coverage-Centric Influence (CCI). We empirically validate our method on two representative BioFMs, RNA-FM and ESM-C. For RNA, our framework consistently outperforms random selection baselines under an extreme pruning rate of over 99 percent, demonstrating its effectiveness. Furthermore, we show the generalizability of our framework on protein-related tasks using ESM-C. In particular, our coreset even outperforms random subsets that are ten times larger in both RNA and protein settings, revealing substantial redundancy in biological sequence datasets. These findings underscore the potential of influence-guided data pruning to substantially reduce the computational cost of BioFM pretraining, paving the way for more efficient, accessible, and sustainable biological AI research.
Canonical Latent Representations in Conditional Diffusion Models
Jun 11, 2025
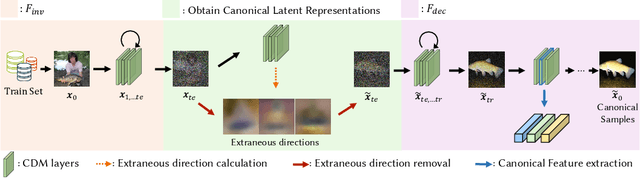

Conditional diffusion models (CDMs) have shown impressive performance across a range of generative tasks. Their ability to model the full data distribution has opened new avenues for analysis-by-synthesis in downstream discriminative learning. However, this same modeling capacity causes CDMs to entangle the class-defining features with irrelevant context, posing challenges to extracting robust and interpretable representations. To this end, we identify Canonical LAtent Representations (CLAReps), latent codes whose internal CDM features preserve essential categorical information while discarding non-discriminative signals. When decoded, CLAReps produce representative samples for each class, offering an interpretable and compact summary of the core class semantics with minimal irrelevant details. Exploiting CLAReps, we develop a novel diffusion-based feature-distillation paradigm, CaDistill. While the student has full access to the training set, the CDM as teacher transfers core class knowledge only via CLAReps, which amounts to merely 10 % of the training data in size. After training, the student achieves strong adversarial robustness and generalization ability, focusing more on the class signals instead of spurious background cues. Our findings suggest that CDMs can serve not just as image generators but also as compact, interpretable teachers that can drive robust representation learning.
AdaNCA: Neural Cellular Automata As Adaptors For More Robust Vision Transformer
Jun 12, 2024Vision Transformers (ViTs) have demonstrated remarkable performance in image classification tasks, particularly when equipped with local information via region attention or convolutions. While such architectures improve the feature aggregation from different granularities, they often fail to contribute to the robustness of the networks. Neural Cellular Automata (NCA) enables the modeling of global cell representations through local interactions, with its training strategies and architecture design conferring strong generalization ability and robustness against noisy inputs. In this paper, we propose Adaptor Neural Cellular Automata (AdaNCA) for Vision Transformer that uses NCA as plug-in-play adaptors between ViT layers, enhancing ViT's performance and robustness against adversarial samples as well as out-of-distribution inputs. To overcome the large computational overhead of standard NCAs, we propose Dynamic Interaction for more efficient interaction learning. Furthermore, we develop an algorithm for identifying the most effective insertion points for AdaNCA based on our analysis of AdaNCA placement and robustness improvement. With less than a 3% increase in parameters, AdaNCA contributes to more than 10% absolute improvement in accuracy under adversarial attacks on the ImageNet1K benchmark. Moreover, we demonstrate with extensive evaluations across 8 robustness benchmarks and 4 ViT architectures that AdaNCA, as a plug-in-play module, consistently improves the robustness of ViTs.
NoiseNCA: Noisy Seed Improves Spatio-Temporal Continuity of Neural Cellular Automata
Apr 09, 2024Neural Cellular Automata (NCA) is a class of Cellular Automata where the update rule is parameterized by a neural network that can be trained using gradient descent. In this paper, we focus on NCA models used for texture synthesis, where the update rule is inspired by partial differential equations (PDEs) describing reaction-diffusion systems. To train the NCA model, the spatio-termporal domain is discretized, and Euler integration is used to numerically simulate the PDE. However, whether a trained NCA truly learns the continuous dynamic described by the corresponding PDE or merely overfits the discretization used in training remains an open question. We study NCA models at the limit where space-time discretization approaches continuity. We find that existing NCA models tend to overfit the training discretization, especially in the proximity of the initial condition, also called "seed". To address this, we propose a solution that utilizes uniform noise as the initial condition. We demonstrate the effectiveness of our approach in preserving the consistency of NCA dynamics across a wide range of spatio-temporal granularities. Our improved NCA model enables two new test-time interactions by allowing continuous control over the speed of pattern formation and the scale of the synthesized patterns. We demonstrate this new NCA feature in our interactive online demo. Our work reveals that NCA models can learn continuous dynamics and opens new venues for NCA research from a dynamical systems' perspective.
Emergent Dynamics in Neural Cellular Automata
Apr 09, 2024
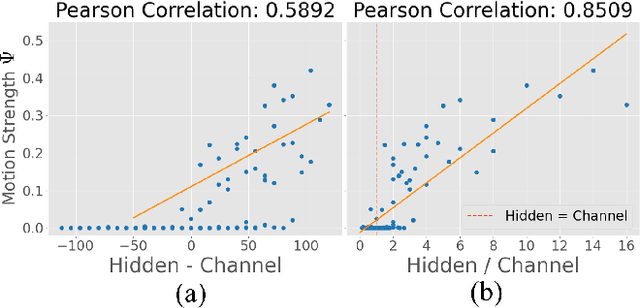

Neural Cellular Automata (NCA) models are trainable variations of traditional Cellular Automata (CA). Emergent motion in the patterns created by NCA has been successfully applied to synthesize dynamic textures. However, the conditions required for an NCA to display dynamic patterns remain unexplored. Here, we investigate the relationship between the NCA architecture and the emergent dynamics of the trained models. Specifically, we vary the number of channels in the cell state and the number of hidden neurons in the MultiLayer Perceptron (MLP), and draw a relationship between the combination of these two variables and the motion strength between successive frames. Our analysis reveals that the disparity and proportionality between these two variables have a strong correlation with the emergent dynamics in the NCA output. We thus propose a design principle for creating dynamic NCA.
Mesh Neural Cellular Automata
Nov 06, 2023Modeling and synthesizing textures are essential for enhancing the realism of virtual environments. Methods that directly synthesize textures in 3D offer distinct advantages to the UV-mapping-based methods as they can create seamless textures and align more closely with the ways textures form in nature. We propose Mesh Neural Cellular Automata (MeshNCA), a method for directly synthesizing dynamic textures on 3D meshes without requiring any UV maps. MeshNCA is a generalized type of cellular automata that can operate on a set of cells arranged on a non-grid structure such as vertices of a 3D mesh. While only being trained on an Icosphere mesh, MeshNCA shows remarkable generalization and can synthesize textures on any mesh in real time after the training. Additionally, it accommodates multi-modal supervision and can be trained using different targets such as images, text prompts, and motion vector fields. Moreover, we conceptualize a way of grafting trained MeshNCA instances, enabling texture interpolation. Our MeshNCA model enables real-time 3D texture synthesis on meshes and allows several user interactions including texture density/orientation control, a grafting brush, and motion speed/direction control. Finally, we implement the forward pass of our MeshNCA model using the WebGL shading language and showcase our trained models in an online interactive demo which is accessible on personal computers and smartphones. Our demo and the high resolution version of this PDF are available at https://meshnca.github.io/.
Alternative Telescopic Displacement: An Efficient Multimodal Alignment Method
Jun 29, 2023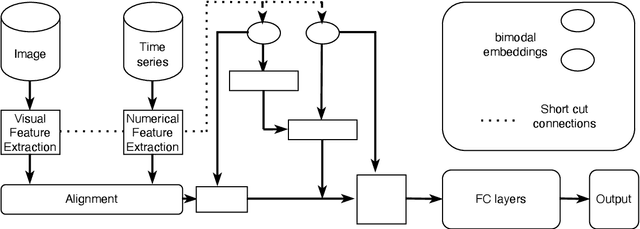
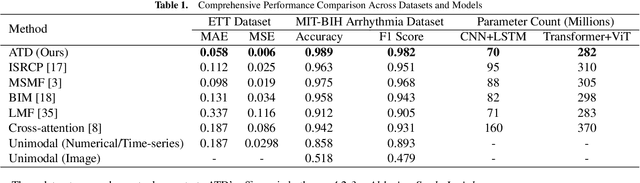
Feature alignment is the primary means of fusing multimodal data. We propose a feature alignment method that fully fuses multimodal information, which alternately shifts and expands feature information from different modalities to have a consistent representation in a feature space. The proposed method can robustly capture high-level interactions between features of different modalities, thus significantly improving the performance of multimodal learning. We also show that the proposed method outperforms other popular multimodal schemes on multiple tasks. Experimental evaluation of ETT and MIT-BIH-Arrhythmia, datasets shows that the proposed method achieves state of the art performance.
DyNCA: Real-time Dynamic Texture Synthesis Using Neural Cellular Automata
Nov 21, 2022Current Dynamic Texture Synthesis (DyTS) models in the literature can synthesize realistic videos. However, these methods require a slow iterative optimization process to synthesize a single fixed-size short video, and they do not offer any post-training control over the synthesis process. We propose Dynamic Neural Cellular Automata (DyNCA), a framework for real-time and controllable dynamic texture synthesis. Our method is built upon the recently introduced NCA models, and can synthesize infinitely-long and arbitrary-size realistic texture videos in real-time. We quantitatively and qualitatively evaluate our model and show that our synthesized videos appear more realistic than the existing results. We improve the SOTA DyTS performance by $2\sim 4$ orders of magnitude. Moreover, our model offers several real-time and interactive video controls including motion speed, motion direction, and an editing brush tool.