 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM2G-Eval: Enhancing and Evaluating Multi-granularity Multilingual Code Generation
Dec 27, 2025The rapid advancement of code large language models (LLMs) has sparked significant research interest in systematically evaluating their code generation capabilities, yet existing benchmarks predominantly assess models at a single structural granularity and focus on limited programming languages, obscuring fine-grained capability variations across different code scopes and multilingual scenarios. We introduce M2G-Eval, a multi-granularity, multilingual framework for evaluating code generation in large language models (LLMs) across four levels: Class, Function, Block, and Line. Spanning 18 programming languages, M2G-Eval includes 17K+ training tasks and 1,286 human-annotated, contamination-controlled test instances. We develop M2G-Eval-Coder models by training Qwen3-8B with supervised fine-tuning and Group Relative Policy Optimization. Evaluating 30 models (28 state-of-the-art LLMs plus our two M2G-Eval-Coder variants) reveals three main findings: (1) an apparent difficulty hierarchy, with Line-level tasks easiest and Class-level most challenging; (2) widening performance gaps between full- and partial-granularity languages as task complexity increases; and (3) strong cross-language correlations, suggesting that models learn transferable programming concepts. M2G-Eval enables fine-grained diagnosis of code generation capabilities and highlights persistent challenges in synthesizing complex, long-form code.
RoboSafe: Safeguarding Embodied Agents via Executable Safety Logic
Dec 24, 2025Embodied agents powered by vision-language models (VLMs) are increasingly capable of executing complex real-world tasks, yet they remain vulnerable to hazardous instructions that may trigger unsafe behaviors. Runtime safety guardrails, which intercept hazardous actions during task execution, offer a promising solution due to their flexibility. However, existing defenses often rely on static rule filters or prompt-level control, which struggle to address implicit risks arising in dynamic, temporally dependent, and context-rich environments. To address this, we propose RoboSafe, a hybrid reasoning runtime safeguard for embodied agents through executable predicate-based safety logic. RoboSafe integrates two complementary reasoning processes on a Hybrid Long-Short Safety Memory. We first propose a Backward Reflective Reasoning module that continuously revisits recent trajectories in short-term memory to infer temporal safety predicates and proactively triggers replanning when violations are detected. We then propose a Forward Predictive Reasoning module that anticipates upcoming risks by generating context-aware safety predicates from the long-term safety memory and the agent's multimodal observations. Together, these components form an adaptive, verifiable safety logic that is both interpretable and executable as code. Extensive experiments across multiple agents demonstrate that RoboSafe substantially reduces hazardous actions (-36.8% risk occurrence) compared with leading baselines, while maintaining near-original task performance. Real-world evaluations on physical robotic arms further confirm its practicality. Code will be released upon acceptance.
CodeSimpleQA: Scaling Factuality in Code Large Language Models
Dec 22, 2025Large language models (LLMs) have made significant strides in code generation, achieving impressive capabilities in synthesizing code snippets from natural language instructions. However, a critical challenge remains in ensuring LLMs generate factually accurate responses about programming concepts, technical implementations, etc. Most previous code-related benchmarks focus on code execution correctness, overlooking the factual accuracy of programming knowledge. To address this gap, we present CodeSimpleQA, a comprehensive bilingual benchmark designed to evaluate the factual accuracy of code LLMs in answering code-related questions, which contains carefully curated question-answer pairs in both English and Chinese, covering diverse programming languages and major computer science domains. Further, we create CodeSimpleQA-Instruct, a large-scale instruction corpus with 66M samples, and develop a post-training framework combining supervised fine-tuning and reinforcement learning. Our comprehensive evaluation of diverse LLMs reveals that even frontier LLMs struggle with code factuality. Our proposed framework demonstrates substantial improvements over the base model, underscoring the critical importance of factuality-aware alignment in developing reliable code LLMs.
Scaling Laws for Code: Every Programming Language Matters
Dec 15, 2025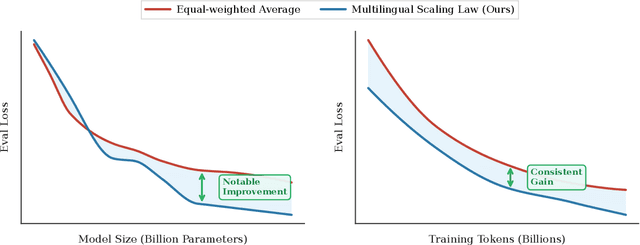

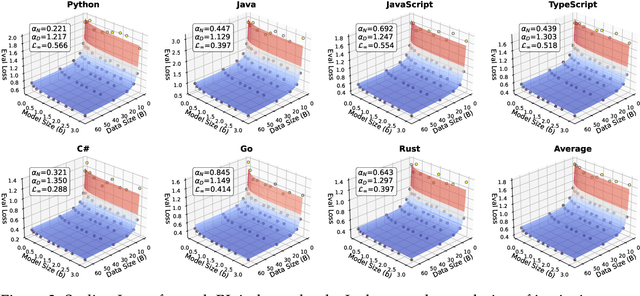

Code large language models (Code LLMs) are powerful but costly to train, with scaling laws predicting performance from model size, data, and compute. However, different programming languages (PLs) have varying impacts during pre-training that significantly affect base model performance, leading to inaccurate performance prediction. Besides, existing works focus on language-agnostic settings, neglecting the inherently multilingual nature of modern software development. Therefore, it is first necessary to investigate the scaling laws of different PLs, and then consider their mutual influences to arrive at the final multilingual scaling law. In this paper, we present the first systematic exploration of scaling laws for multilingual code pre-training, conducting over 1000+ experiments (Equivalent to 336,000+ H800 hours) across multiple PLs, model sizes (0.2B to 14B parameters), and dataset sizes (1T tokens). We establish comprehensive scaling laws for code LLMs across multiple PLs, revealing that interpreted languages (e.g., Python) benefit more from increased model size and data than compiled languages (e.g., Rust). The study demonstrates that multilingual pre-training provides synergistic benefits, particularly between syntactically similar PLs. Further, the pre-training strategy of the parallel pairing (concatenating code snippets with their translations) significantly enhances cross-lingual abilities with favorable scaling properties. Finally, a proportion-dependent multilingual scaling law is proposed to optimally allocate training tokens by prioritizing high-utility PLs (e.g., Python), balancing high-synergy pairs (e.g., JavaScript-TypeScript), and reducing allocation to fast-saturating languages (Rust), achieving superior average performance across all PLs compared to uniform distribution under the same compute budget.
SLMQuant:Benchmarking Small Language Model Quantization for Practical Deployment
Nov 17, 2025Despite the growing interest in Small Language Models (SLMs) as resource-efficient alternatives to Large Language Models (LLMs), their deployment on edge devices remains challenging due to unresolved efficiency gaps in model compression. While quantization has proven effective for LLMs, its applicability to SLMs is significantly underexplored, with critical questions about differing quantization bottlenecks and efficiency profiles. This paper introduces SLMQuant, the first systematic benchmark for evaluating LLM compression techniques when applied to SLMs. Through comprehensive multi-track evaluations across diverse architectures and tasks, we analyze how state-of-the-art quantization methods perform on SLMs. Our findings reveal fundamental disparities between SLMs and LLMs in quantization sensitivity, demonstrating that direct transfer of LLM-optimized techniques leads to suboptimal results due to SLMs' unique architectural characteristics and training dynamics. We identify key factors governing effective SLM quantization and propose actionable design principles for SLM-tailored compression. SLMQuant establishes a foundational framework for advancing efficient SLM deployment on low-end devices in edge applications, and provides critical insights for deploying lightweight language models in resource-constrained scenarios.
VEIL: Jailbreaking Text-to-Video Models via Visual Exploitation from Implicit Language
Nov 17, 2025Jailbreak attacks can circumvent model safety guardrails and reveal critical blind spots. Prior attacks on text-to-video (T2V) models typically add adversarial perturbations to obviously unsafe prompts, which are often easy to detect and defend. In contrast, we show that benign-looking prompts containing rich, implicit cues can induce T2V models to generate semantically unsafe videos that both violate policy and preserve the original (blocked) intent. To realize this, we propose VEIL, a jailbreak framework that leverages T2V models' cross-modal associative patterns via a modular prompt design. Specifically, our prompts combine three components: neutral scene anchors, which provide the surface-level scene description extracted from the blocked intent to maintain plausibility; latent auditory triggers, textual descriptions of innocuous-sounding audio events (e.g., creaking, muffled noises) that exploit learned audio-visual co-occurrence priors to bias the model toward particular unsafe visual concepts; and stylistic modulators, cinematic directives (e.g., camera framing, atmosphere) that amplify and stabilize the latent trigger's effect. We formalize attack generation as a constrained optimization over the above modular prompt space and solve it with a guided search procedure that balances stealth and effectiveness. Extensive experiments over 7 T2V models demonstrate the efficacy of our attack, achieving a 23 percent improvement in average attack success rate in commercial models.
Exploring Semantic-constrained Adversarial Example with Instruction Uncertainty Reduction
Oct 27, 2025
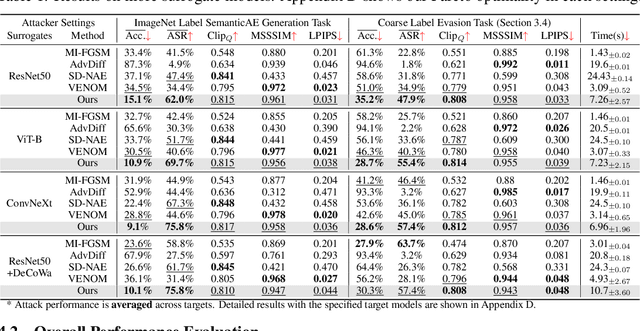
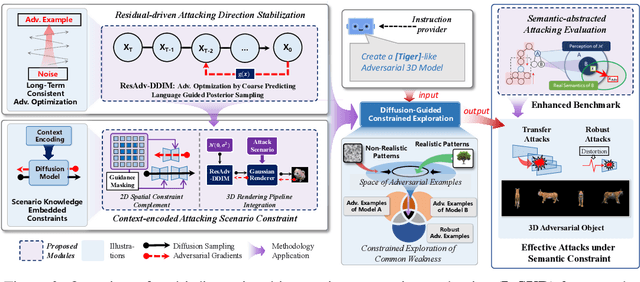

Recently, semantically constrained adversarial examples (SemanticAE), which are directly generated from natural language instructions, have become a promising avenue for future research due to their flexible attacking forms. To generate SemanticAEs, current methods fall short of satisfactory attacking ability as the key underlying factors of semantic uncertainty in human instructions, such as referring diversity, descriptive incompleteness, and boundary ambiguity, have not been fully investigated. To tackle the issues, this paper develops a multi-dimensional instruction uncertainty reduction (InSUR) framework to generate more satisfactory SemanticAE, i.e., transferable, adaptive, and effective. Specifically, in the dimension of the sampling method, we propose the residual-driven attacking direction stabilization to alleviate the unstable adversarial optimization caused by the diversity of language references. By coarsely predicting the language-guided sampling process, the optimization process will be stabilized by the designed ResAdv-DDIM sampler, therefore releasing the transferable and robust adversarial capability of multi-step diffusion models. In task modeling, we propose the context-encoded attacking scenario constraint to supplement the missing knowledge from incomplete human instructions. Guidance masking and renderer integration are proposed to regulate the constraints of 2D/3D SemanticAE, activating stronger scenario-adapted attacks. Moreover, in the dimension of generator evaluation, we propose the semantic-abstracted attacking evaluation enhancement by clarifying the evaluation boundary, facilitating the development of more effective SemanticAE generators. Extensive experiments demonstrate the superiority of the transfer attack performance of InSUR. Moreover, we realize the reference-free generation of semantically constrained 3D adversarial examples for the first time.
RoboView-Bias: Benchmarking Visual Bias in Embodied Agents for Robotic Manipulation
Sep 26, 2025The safety and reliability of embodied agents rely on accurate and unbiased visual perception. However, existing benchmarks mainly emphasize generalization and robustness under perturbations, while systematic quantification of visual bias remains scarce. This gap limits a deeper understanding of how perception influences decision-making stability. To address this issue, we propose RoboView-Bias, the first benchmark specifically designed to systematically quantify visual bias in robotic manipulation, following a principle of factor isolation. Leveraging a structured variant-generation framework and a perceptual-fairness validation protocol, we create 2,127 task instances that enable robust measurement of biases induced by individual visual factors and their interactions. Using this benchmark, we systematically evaluate three representative embodied agents across two prevailing paradigms and report three key findings: (i) all agents exhibit significant visual biases, with camera viewpoint being the most critical factor; (ii) agents achieve their highest success rates on highly saturated colors, indicating inherited visual preferences from underlying VLMs; and (iii) visual biases show strong, asymmetric coupling, with viewpoint strongly amplifying color-related bias. Finally, we demonstrate that a mitigation strategy based on a semantic grounding layer substantially reduces visual bias by approximately 54.5\% on MOKA. Our results highlight that systematic analysis of visual bias is a prerequisite for developing safe and reliable general-purpose embodied agents.
Adversarial Generation and Collaborative Evolution of Safety-Critical Scenarios for Autonomous Vehicles
Aug 20, 2025The generation of safety-critical scenarios in simulation has become increasingly crucial for safety evaluation in autonomous vehicles prior to road deployment in society. However, current approaches largely rely on predefined threat patterns or rule-based strategies, which limit their ability to expose diverse and unforeseen failure modes. To overcome these, we propose ScenGE, a framework that can generate plentiful safety-critical scenarios by reasoning novel adversarial cases and then amplifying them with complex traffic flows. Given a simple prompt of a benign scene, it first performs Meta-Scenario Generation, where a large language model, grounded in structured driving knowledge, infers an adversarial agent whose behavior poses a threat that is both plausible and deliberately challenging. This meta-scenario is then specified in executable code for precise in-simulator control. Subsequently, Complex Scenario Evolution uses background vehicles to amplify the core threat introduced by Meta-Scenario. It builds an adversarial collaborator graph to identify key agent trajectories for optimization. These perturbations are designed to simultaneously reduce the ego vehicle's maneuvering space and create critical occlusions. Extensive experiments conducted on multiple reinforcement learning based AV models show that ScenGE uncovers more severe collision cases (+31.96%) on average than SoTA baselines. Additionally, our ScenGE can be applied to large model based AV systems and deployed on different simulators; we further observe that adversarial training on our scenarios improves the model robustness. Finally, we validate our framework through real-world vehicle tests and human evaluation, confirming that the generated scenarios are both plausible and critical. We hope our paper can build up a critical step towards building public trust and ensuring their safe deployment.
Dynamic Benchmark Construction for Evaluating Large Language Models on Real-World Codes
Aug 10, 2025As large language models LLMs) become increasingly integrated into software development workflows, rigorously evaluating their performance on complex, real-world code generation tasks has become essential. However, existing benchmarks often suffer from data contamination and limited test rigor, constraining their ability to reveal model failures effectively. To address these, we present CODE2BENCH, a end-to-end pipeline for dynamically constructing robust and contamination-resistant benchmarks from real-world GitHub repositories. Specifically, CODE2BENCH introduces three key innovations: (1) Automated Dynamism, achieved through periodic ingestion of recent code to minimize training data contamination; (2) Scope Graph-based dependency analysis, which enables structured classification of functions into benchmark instances with controlled dependency levels (distinguishing between Self-Contained (SC) tasks for cross-language evaluation and Weakly Self-Contained (WSC) tasks involving permitted library usage); and (3) Property-Based Testing (PBT) for the automated synthesis of rigorous test suites to enable thorough functional verification. Using this pipeline, we construct CODE2BENCH-2505, the first benchmark derived from 880 recent Python projects spanning diverse domains, comprising 1,163 code generation tasks with 100% average branch coverage on ground-truth implementations. Extensive evaluation of 16 LLMs using CODE2BENCH-2505 reveals that models consistently struggle with SC tasks requiring complex, non-standard logic and cross-language transfer, while showing relatively stronger performance on WSC tasks in Python. Our work introduces a contamination-resistant, language-agnostic methodology for dynamic benchmark construction, offering a principled foundation for the comprehensive and realistic evaluation of LLMs on real-world software development tasks.