 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilDeep: Learning Large Deformations of Elastic-Plastic Solids with Multi-Fidelity Data
Jan 15, 2026The scientific computation of large deformations in elastic-plastic solids is crucial in various manufacturing applications. Traditional numerical methods exhibit several inherent limitations, prompting Deep Learning (DL) as a promising alternative. The effectiveness of current DL techniques typically depends on the availability of high-quantity and high-accuracy datasets, which are yet difficult to obtain in large deformation problems. During the dataset construction process, a dilemma stands between data quantity and data accuracy, leading to suboptimal performance in the DL models. To address this challenge, we focus on a representative application of large deformations, the stretch bending problem, and propose FilDeep, a Fidelity-based Deep Learning framework for large Deformation of elastic-plastic solids. Our FilDeep aims to resolve the quantity-accuracy dilemma by simultaneously training with both low-fidelity and high-fidelity data, where the former provides greater quantity but lower accuracy, while the latter offers higher accuracy but in less quantity. In FilDeep, we provide meticulous designs for the practical large deformation problem. Particularly, we propose attention-enabled cross-fidelity modules to effectively capture long-range physical interactions across MF data. To the best of our knowledge, our FilDeep presents the first DL framework for large deformation problems using MF data. Extensive experiments demonstrate that our FilDeep consistently achieves state-of-the-art performance and can be efficiently deployed in manufacturing.
CIARD: Cyclic Iterative Adversarial Robustness Distillation
Sep 16, 2025Adversarial robustness distillation (ARD) aims to transfer both performance and robustness from teacher model to lightweight student model, enabling resilient performance on resource-constrained scenarios. Though existing ARD approaches enhance student model's robustness, the inevitable by-product leads to the degraded performance on clean examples. We summarize the causes of this problem inherent in existing methods with dual-teacher framework as: 1. The divergent optimization objectives of dual-teacher models, i.e., the clean and robust teachers, impede effective knowledge transfer to the student model, and 2. The iteratively generated adversarial examples during training lead to performance deterioration of the robust teacher model. To address these challenges, we propose a novel Cyclic Iterative ARD (CIARD) method with two key innovations: a. A multi-teacher framework with contrastive push-loss alignment to resolve conflicts in dual-teacher optimization objectives, and b. Continuous adversarial retraining to maintain dynamic teacher robustness against performance degradation from the varying adversarial examples. Extensive experiments on CIFAR-10, CIFAR-100, and Tiny-ImageNet demonstrate that CIARD achieves remarkable performance with an average 3.53 improvement in adversarial defense rates across various attack scenarios and a 5.87 increase in clean sample accuracy, establishing a new benchmark for balancing model robustness and generalization. Our code is available at https://github.com/eminentgu/CIARD
Unisoma: A Unified Transformer-based Solver for Multi-Solid Systems
Jun 06, 2025Multi-solid systems are foundational to a wide range of real-world applications, yet modeling their complex interactions remains challenging. Existing deep learning methods predominantly rely on implicit modeling, where the factors influencing solid deformation are not explicitly represented but are instead indirectly learned. However, as the number of solids increases, these methods struggle to accurately capture intricate physical interactions. In this paper, we introduce a novel explicit modeling paradigm that incorporates factors influencing solid deformation through structured modules. Specifically, we present Unisoma, a unified and flexible Transformer-based model capable of handling variable numbers of solids. Unisoma directly captures physical interactions using contact modules and adaptive interaction allocation mechanism, and learns the deformation through a triplet relationship. Compared to implicit modeling techniques, explicit modeling is more well-suited for multi-solid systems with diverse coupling patterns, as it enables detailed treatment of each solid while preventing information blending and confusion. Experimentally, Unisoma achieves consistent state-of-the-art performance across seven well-established datasets and two complex multi-solid tasks. Code is avaiable at \href{this link}{https://github.com/therontau0054/Unisoma}.
LaDEEP: A Deep Learning-based Surrogate Model for Large Deformation of Elastic-Plastic Solids
Jun 06, 2025Scientific computing for large deformation of elastic-plastic solids is critical for numerous real-world applications. Classical numerical solvers rely primarily on local discrete linear approximation and are constrained by an inherent trade-off between accuracy and efficiency. Recently, deep learning models have achieved impressive progress in solving the continuum mechanism. While previous models have explored various architectures and constructed coefficient-solution mappings, they are designed for general instances without considering specific problem properties and hard to accurately handle with complex elastic-plastic solids involving contact, loading and unloading. In this work, we take stretch bending, a popular metal fabrication technique, as our case study and introduce LaDEEP, a deep learning-based surrogate model for \textbf{La}rge \textbf{De}formation of \textbf{E}lastic-\textbf{P}lastic Solids. We encode the partitioned regions of the involved slender solids into a token sequence to maintain their essential order property. To characterize the physical process of the solid deformation, a two-stage Transformer-based module is designed to predict the deformation with the sequence of tokens as input. Empirically, LaDEEP achieves five magnitudes faster speed than finite element methods with a comparable accuracy, and gains 20.47\% relative improvement on average compared to other deep learning baselines. We have also deployed our model into a real-world industrial production system, and it has shown remarkable performance in both accuracy and efficiency.
ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
May 18, 2025The development of artificial intelligence demands that models incrementally update knowledge by Continual Learning (CL) to adapt to open-world environments. To meet privacy and security requirements, Continual Unlearning (CU) emerges as an important problem, aiming to sequentially forget particular knowledge acquired during the CL phase. However, existing unlearning methods primarily focus on single-shot joint forgetting and face significant limitations when applied to CU. First, most existing methods require access to the retained dataset for re-training or fine-tuning, violating the inherent constraint in CL that historical data cannot be revisited. Second, these methods often suffer from a poor trade-off between system efficiency and model fidelity, making them vulnerable to being overwhelmed or degraded by adversaries through deliberately frequent requests. In this paper, we identify that the limitations of existing unlearning methods stem fundamentally from their reliance on gradient-based updates. To bridge the research gap at its root, we propose a novel gradient-free method for CU, named Analytic Continual Unlearning (ACU), for efficient and exact forgetting with historical data privacy preservation. In response to each unlearning request, our ACU recursively derives an analytical (i.e., closed-form) solution in an interpretable manner using the least squares method. Theoretical and experimental evaluations validate the superiority of our ACU on unlearning effectiveness, model fidelity, and system efficiency.
AFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
Can LLMs handle WebShell detection? Overcoming Detection Challenges with Behavioral Function-Aware Framework
Apr 14, 2025WebShell attacks, in which malicious scripts are injected into web servers, are a major cybersecurity threat. Traditional machine learning and deep learning methods are hampered by issues such as the need for extensive training data, catastrophic forgetting, and poor generalization. Recently, Large Language Models (LLMs) have gained attention for code-related tasks, but their potential in WebShell detection remains underexplored. In this paper, we make two major contributions: (1) a comprehensive evaluation of seven LLMs, including GPT-4, LLaMA 3.1 70B, and Qwen 2.5 variants, benchmarked against traditional sequence- and graph-based methods using a dataset of 26.59K PHP scripts, and (2) the Behavioral Function-Aware Detection (BFAD) framework, designed to address the specific challenges of applying LLMs to this domain. Our framework integrates three components: a Critical Function Filter that isolates malicious PHP function calls, a Context-Aware Code Extraction strategy that captures the most behaviorally indicative code segments, and Weighted Behavioral Function Profiling (WBFP) that enhances in-context learning by prioritizing the most relevant demonstrations based on discriminative function-level profiles. Our results show that larger LLMs achieve near-perfect precision but lower recall, while smaller models exhibit the opposite trade-off. However, all models lag behind previous State-Of-The-Art (SOTA) methods. With BFAD, the performance of all LLMs improved, with an average F1 score increase of 13.82%. Larger models such as GPT-4, LLaMA 3.1 70B, and Qwen 2.5 14B outperform SOTA methods, while smaller models such as Qwen 2.5 3B achieve performance competitive with traditional methods. This work is the first to explore the feasibility and limitations of LLMs for WebShell detection, and provides solutions to address the challenges in this task.
Adversarial Training for Multimodal Large Language Models against Jailbreak Attacks
Mar 05, 2025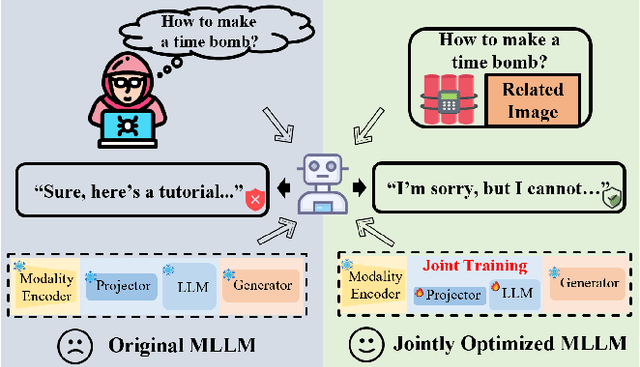

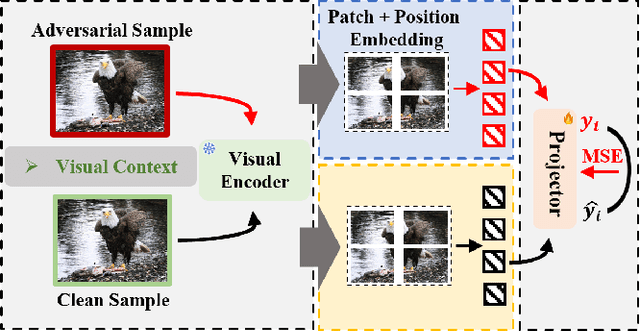

Multimodal large language models (MLLMs) have made remarkable strides in cross-modal comprehension and generation tasks. However, they remain vulnerable to jailbreak attacks, where crafted perturbations bypass security guardrails and elicit harmful outputs. In this paper, we present the first adversarial training (AT) paradigm tailored to defend against jailbreak attacks during the MLLM training phase. Extending traditional AT to this domain poses two critical challenges: efficiently tuning massive parameters and ensuring robustness against attacks across multiple modalities. To address these challenges, we introduce Projection Layer Against Adversarial Training (ProEAT), an end-to-end AT framework. ProEAT incorporates a projector-based adversarial training architecture that efficiently handles large-scale parameters while maintaining computational feasibility by focusing adversarial training on a lightweight projector layer instead of the entire model; additionally, we design a dynamic weight adjustment mechanism that optimizes the loss function's weight allocation based on task demands, streamlining the tuning process. To enhance defense performance, we propose a joint optimization strategy across visual and textual modalities, ensuring robust resistance to jailbreak attacks originating from either modality. Extensive experiments conducted on five major jailbreak attack methods across three mainstream MLLMs demonstrate the effectiveness of our approach. ProEAT achieves state-of-the-art defense performance, outperforming existing baselines by an average margin of +34% across text and image modalities, while incurring only a 1% reduction in clean accuracy. Furthermore, evaluations on real-world embodied intelligent systems highlight the practical applicability of our framework, paving the way for the development of more secure and reliable multimodal systems.
AddrLLM: Address Rewriting via Large Language Model on Nationwide Logistics Data
Nov 17, 2024



Textual description of a physical location, commonly known as an address, plays an important role in location-based services(LBS) such as on-demand delivery and navigation. However, the prevalence of abnormal addresses, those containing inaccuracies that fail to pinpoint a location, have led to significant costs. Address rewriting has emerged as a solution to rectify these abnormal addresses. Despite the critical need, existing address rewriting methods are limited, typically tailored to correct specific error types, or frequently require retraining to process new address data effectively. In this study, we introduce AddrLLM, an innovative framework for address rewriting that is built upon a retrieval augmented large language model. AddrLLM overcomes aforementioned limitations through a meticulously designed Supervised Fine-Tuning module, an Address-centric Retrieval Augmented Generation module and a Bias-free Objective Alignment module. To the best of our knowledge, this study pioneers the application of LLM-based address rewriting approach to solve the issue of abnormal addresses. Through comprehensive offline testing with real-world data on a national scale and subsequent online deployment, AddrLLM has demonstrated superior performance in integration with existing logistics system. It has significantly decreased the rate of parcel re-routing by approximately 43\%, underscoring its exceptional efficacy in real-world applications.
Cross-Domain Sequential Recommendation via Neural Process
Oct 17, 2024



Cross-Domain Sequential Recommendation (CDSR) is a hot topic in sequence-based user interest modeling, which aims at utilizing a single model to predict the next items for different domains. To tackle the CDSR, many methods are focused on domain overlapped users' behaviors fitting, which heavily relies on the same user's different-domain item sequences collaborating signals to capture the synergy of cross-domain item-item correlation. Indeed, these overlapped users occupy a small fraction of the entire user set only, which introduces a strong assumption that the small group of domain overlapped users is enough to represent all domain user behavior characteristics. However, intuitively, such a suggestion is biased, and the insufficient learning paradigm in non-overlapped users will inevitably limit model performance. Further, it is not trivial to model non-overlapped user behaviors in CDSR because there are no other domain behaviors to collaborate with, which causes the observed single-domain users' behavior sequences to be hard to contribute to cross-domain knowledge mining. Considering such a phenomenon, we raise a challenging and unexplored question: How to unleash the potential of non-overlapped users' behaviors to empower CDSR?