 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
Growing the Efficient Frontier on Panel Trees
Jan 28, 2025



We introduce a new class of tree-based models, P-Trees, for analyzing (unbalanced) panel of individual asset returns, generalizing high-dimensional sorting with economic guidance and interpretability. Under the mean-variance efficient framework, P-Trees construct test assets that significantly advance the efficient frontier compared to commonly used test assets, with alphas unexplained by benchmark pricing models. P-Tree tangency portfolios also constitute traded factors, recovering the pricing kernel and outperforming popular observable and latent factor models for investments and cross-sectional pricing. Finally, P-Trees capture the complexity of asset returns with sparsity, achieving out-of-sample Sharpe ratios close to those attained only by over-parameterized large models.
Stochastic Tree Ensembles for Estimating Heterogeneous Effects
Sep 15, 2022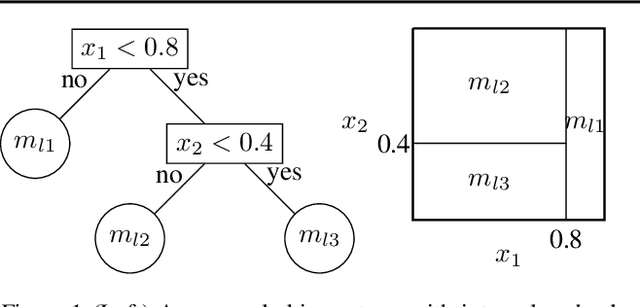

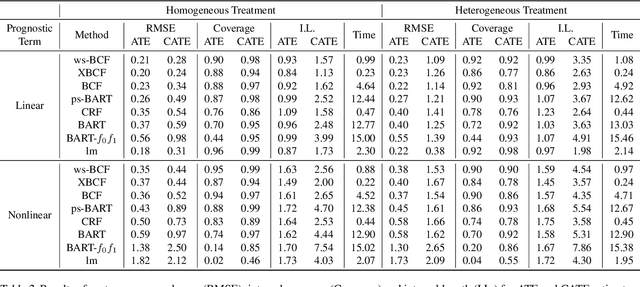

Determining subgroups that respond especially well (or poorly) to specific interventions (medical or policy) requires new supervised learning methods tailored specifically for causal inference. Bayesian Causal Forest (BCF) is a recent method that has been documented to perform well on data generating processes with strong confounding of the sort that is plausible in many applications. This paper develops a novel algorithm for fitting the BCF model, which is more efficient than the previously available Gibbs sampler. The new algorithm can be used to initialize independent chains of the existing Gibbs sampler leading to better posterior exploration and coverage of the associated interval estimates in simulation studies. The new algorithm is compared to related approaches via simulation studies as well as an empirical analysis.
Local Gaussian process extrapolation for BART models with applications to causal inference
Apr 23, 2022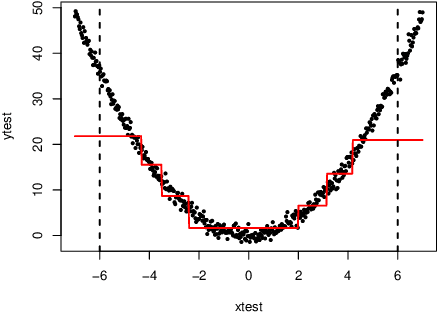
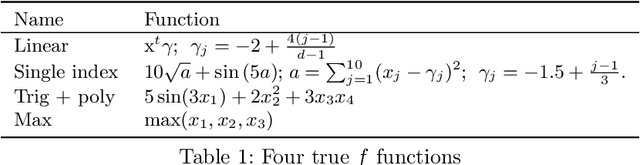
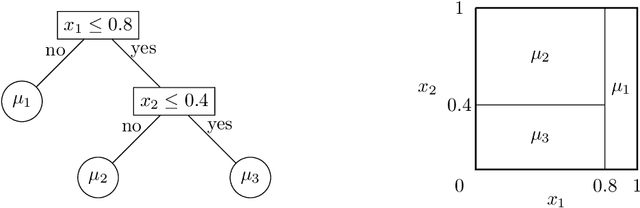
Bayesian additive regression trees (BART) is a semi-parametric regression model offering state-of-the-art performance on out-of-sample prediction. Despite this success, standard implementations of BART typically provide inaccurate prediction and overly narrow prediction intervals at points outside the range of the training data. This paper proposes a novel extrapolation strategy that grafts Gaussian processes to the leaf nodes in BART for predicting points outside the range of the observed data. The new method is compared to standard BART implementations and recent frequentist resampling-based methods for predictive inference. We apply the new approach to a challenging problem from causal inference, wherein for some regions of predictor space, only treated or untreated units are observed (but not both). In simulations studies, the new approach boasts superior performance compared to popular alternatives, such as Jackknife+.
Bayesian Inference for Gamma Models
Jun 21, 2021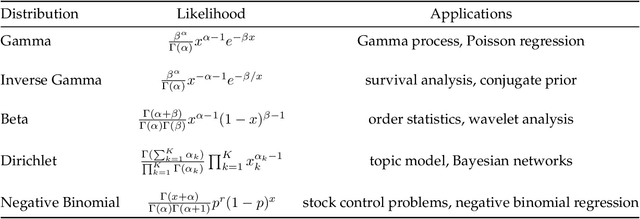

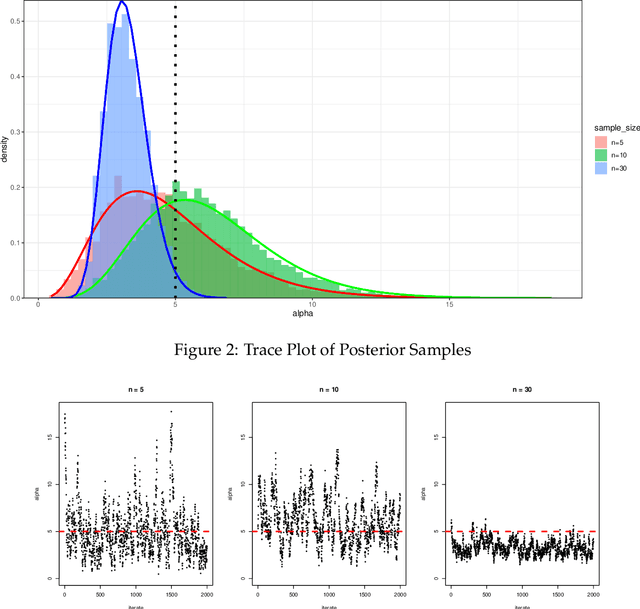
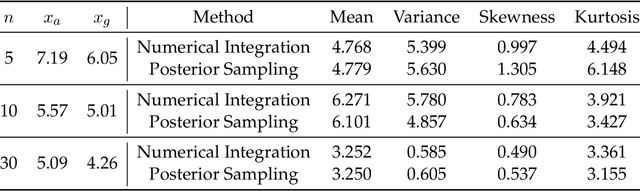
We use the theory of normal variance-mean mixtures to derive a data augmentation scheme for models that include gamma functions. Our methodology applies to many situations in statistics and machine learning, including Multinomial-Dirichlet distributions, Negative binomial regression, Poisson-Gamma hierarchical models, Extreme value models, to name but a few. All of those models include a gamma function which does not admit a natural conjugate prior distribution providing a significant challenge to inference and prediction. To provide a data augmentation strategy, we construct and develop the theory of the class of Exponential Reciprocal Gamma distributions. This allows scalable EM and MCMC algorithms to be developed. We illustrate our methodology on a number of examples, including gamma shape inference, negative binomial regression and Dirichlet allocation. Finally, we conclude with directions for future research.
Stochastic tree ensembles for regularized nonlinear regression
Feb 09, 2020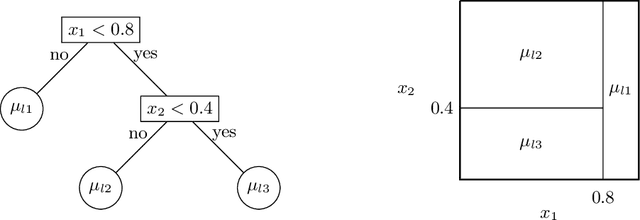

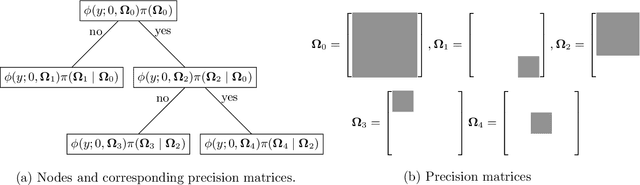
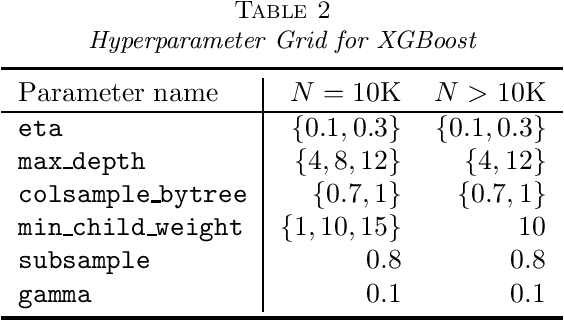
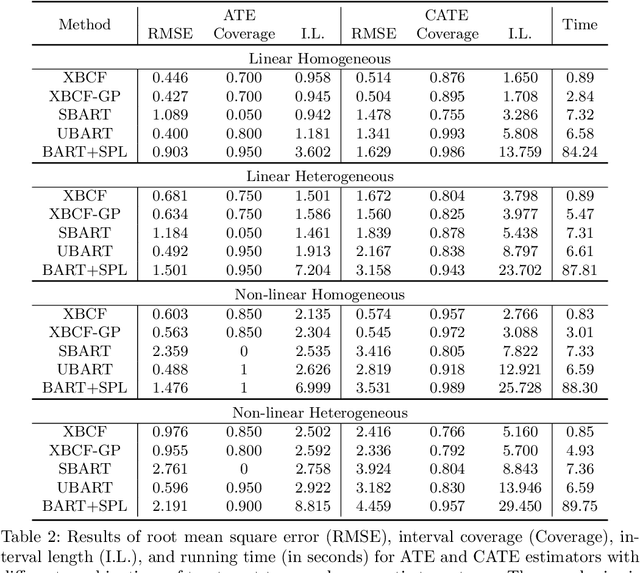
This paper develops a novel stochastic tree ensemble method for nonlinear regression, which we refer to as XBART, short for Accelerated Bayesian Additive Regression Trees. By combining regularization and stochastic search strategies from Bayesian modeling with computationally efficient techniques from recursive partitioning approaches, the new method attains state-of-the-art performance: in many settings it is both faster and more accurate than the widely-used XGBoost algorithm. Via careful simulation studies, we demonstrate that our new approach provides accurate point-wise estimates of the mean function and does so faster than popular alternatives, such as BART, XGBoost and neural networks (using Keras). We also prove a number of basic theoretical results about the new algorithm, including consistency of the single tree version of the model and stationarity of the Markov chain produced by the ensemble version. Furthermore, we demonstrate that initializing standard Bayesian additive regression trees Markov chain Monte Carlo (MCMC) at XBART-fitted trees considerably improves credible interval coverage and reduces total run-time.
Bayesian Inference for Polya Inverse Gamma Models
May 29, 2019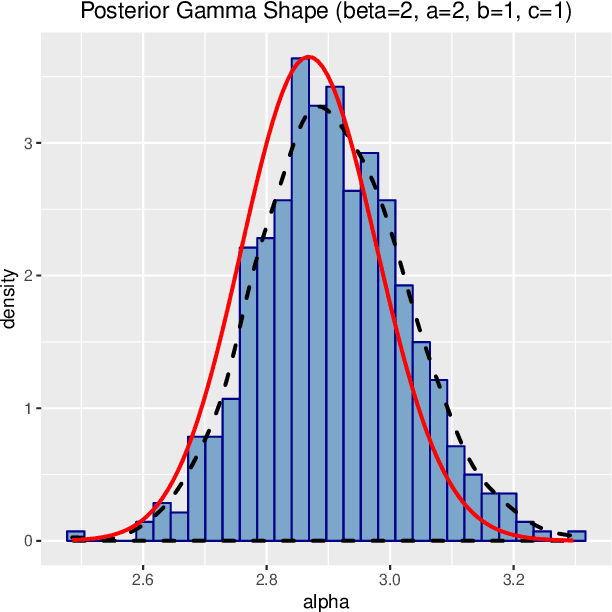
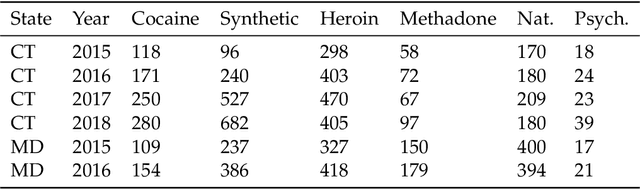
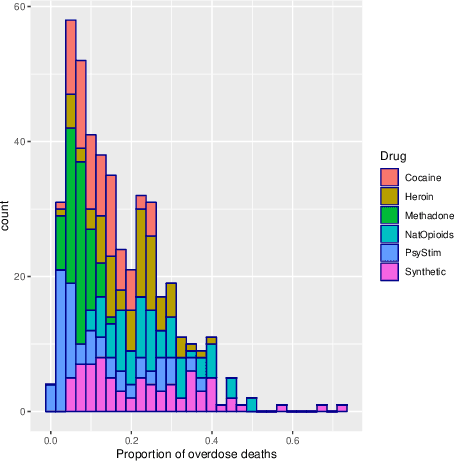
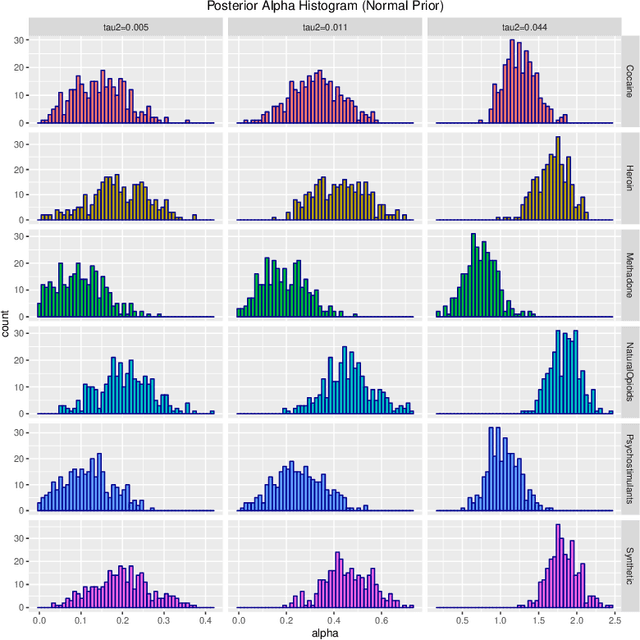
Probability density functions that include the gamma function are widely used in statistics and machine learning. The normalizing constants of gamma, inverse gamma, beta, and Dirichlet distributions all include model parameters as arguments in the gamma function; however, the gamma function does not naturally admit a conjugate prior distribution in a Bayesian analysis, and statistical inference of these parameters is a significant challenge. In this paper, we construct the Polya-inverse Gamma (P-IG) distribution as an infinite convolution of Generalized inverse Gaussian (GIG) distributions, and we represent the reciprocal gamma function as a scale mixture of normal distributions. As a result, the P-IG distribution yields an efficient data augmentation strategy for fully Bayesian inference on model parameters in gamma, inverse gamma, beta, and Dirichlet distributions. To illustrate the applied utility of our data augmentation strategy, we infer the proportion of overdose deaths in the United States attributed to different opioid and prescription drugs with a Dirichlet allocation model.
Efficient sampling for Gaussian linear regression with arbitrary priors
Jun 14, 2018
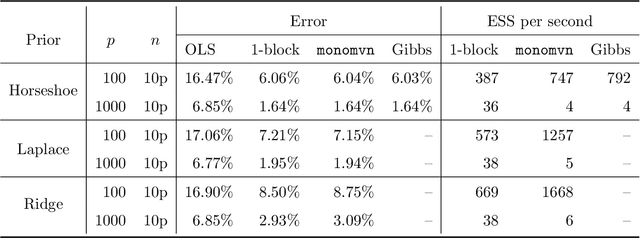
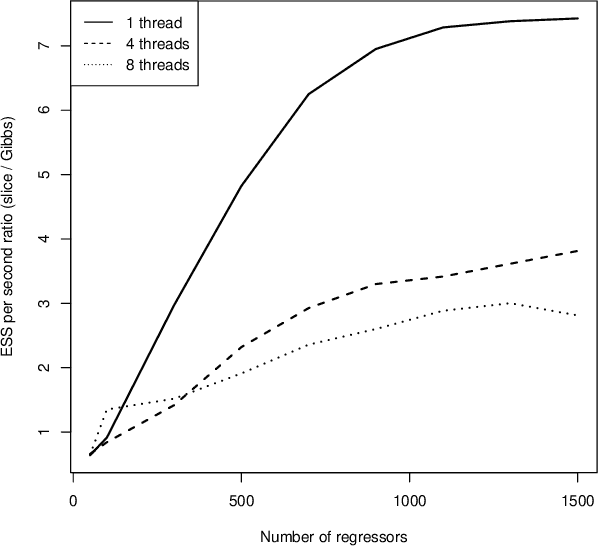

This paper develops a slice sampler for Bayesian linear regression models with arbitrary priors. The new sampler has two advantages over current approaches. One, it is faster than many custom implementations that rely on auxiliary latent variables, if the number of regressors is large. Two, it can be used with any prior with a density function that can be evaluated up to a normalizing constant, making it ideal for investigating the properties of new shrinkage priors without having to develop custom sampling algorithms. The new sampler takes advantage of the special structure of the linear regression likelihood, allowing it to produce better effective sample size per second than common alternative approaches.
Deep Learning for Predicting Asset Returns
Apr 26, 2018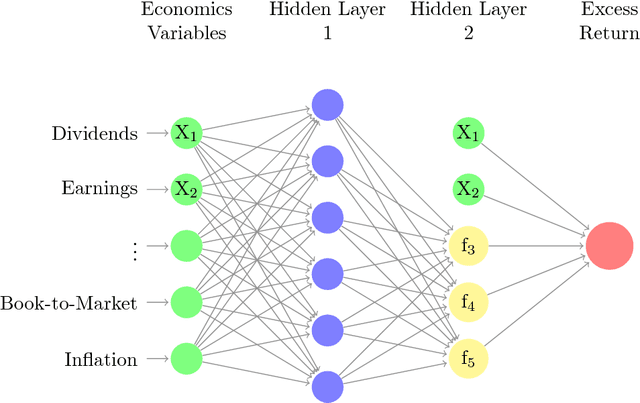
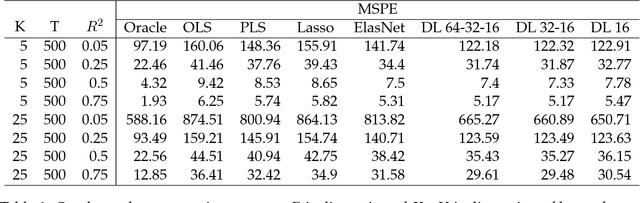
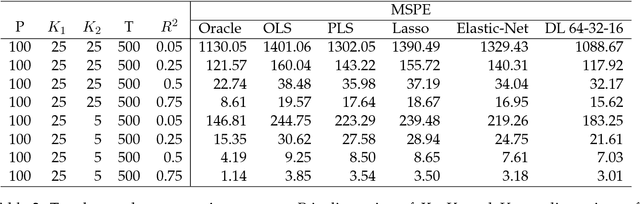
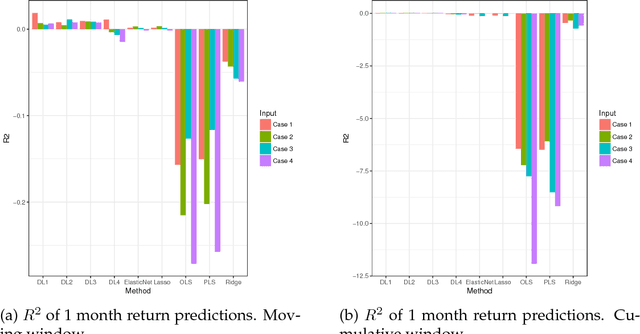
Deep learning searches for nonlinear factors for predicting asset returns. Predictability is achieved via multiple layers of composite factors as opposed to additive ones. Viewed in this way, asset pricing studies can be revisited using multi-layer deep learners, such as rectified linear units (ReLU) or long-short-term-memory (LSTM) for time-series effects. State-of-the-art algorithms including stochastic gradient descent (SGD), TensorFlow and dropout design provide imple- mentation and efficient factor exploration. To illustrate our methodology, we revisit the equity market risk premium dataset of Welch and Goyal (2008). We find the existence of nonlinear factors which explain predictability of returns, in particular at the extremes of the characteristic space. Finally, we conclude with directions for future research.