 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Value of Chess Squares
Jul 08, 2023
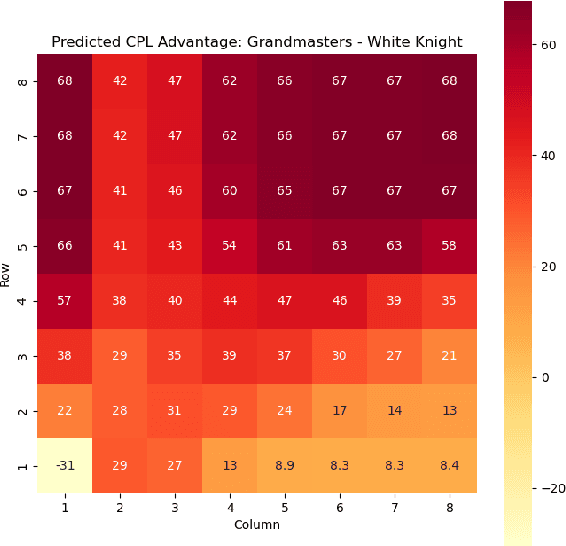
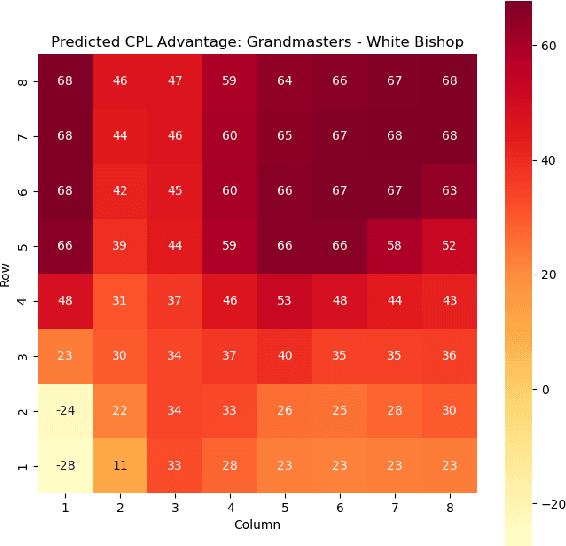
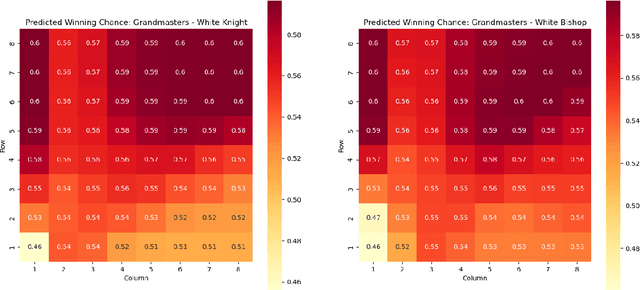
Valuing chess squares and determining the placement of pieces on the board are the main objectives of our study. With the emergence of chess AI, it has become possible to accurately assess the worth of positions in a game of chess. The conventional approach assigns fixed values to pieces $(\symking=\infty, \symqueen=9, \symrook=5, \symbishop=3, \symknight=3, \sympawn=1)$. We enhance this analysis by introducing marginal valuations for both pieces and squares. We demonstrate our method by examining the positioning of Knights and Bishops, and also provide valuable insights into the valuation of pawns. Notably, Nimzowitsch was among the pioneers in advocating for the significance of Pawn structure and valuation. Finally, we conclude by suggesting potential avenues for future research.
Bayesian Inference for Gamma Models
Jun 21, 2021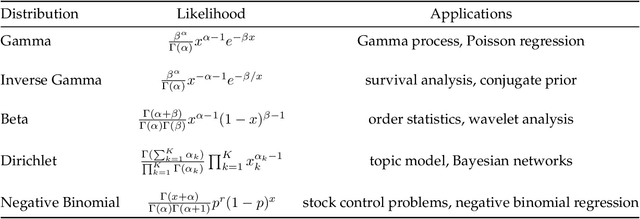

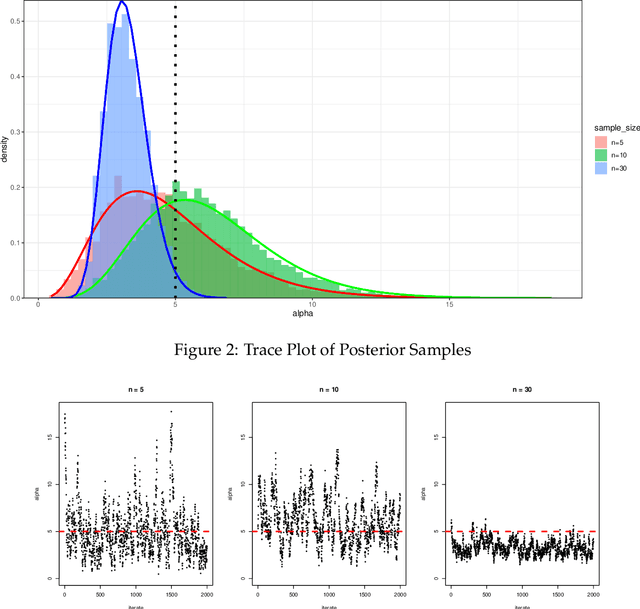
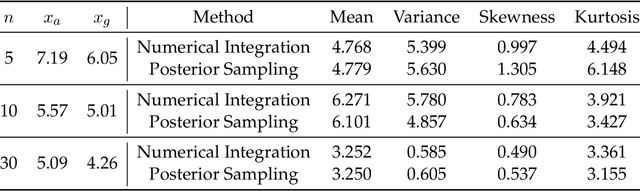
We use the theory of normal variance-mean mixtures to derive a data augmentation scheme for models that include gamma functions. Our methodology applies to many situations in statistics and machine learning, including Multinomial-Dirichlet distributions, Negative binomial regression, Poisson-Gamma hierarchical models, Extreme value models, to name but a few. All of those models include a gamma function which does not admit a natural conjugate prior distribution providing a significant challenge to inference and prediction. To provide a data augmentation strategy, we construct and develop the theory of the class of Exponential Reciprocal Gamma distributions. This allows scalable EM and MCMC algorithms to be developed. We illustrate our methodology on a number of examples, including gamma shape inference, negative binomial regression and Dirichlet allocation. Finally, we conclude with directions for future research.
Deep Learning: Computational Aspects
Aug 26, 2018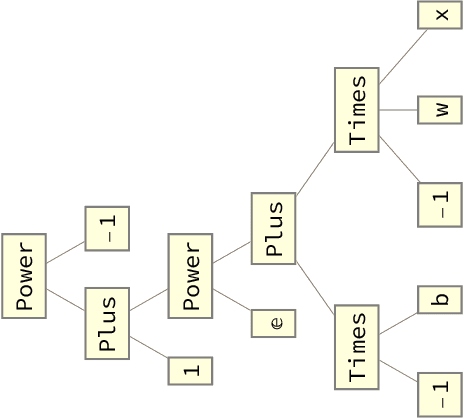

In this article we review computational aspects of Deep Learning (DL). Deep learning uses network architectures consisting of hierarchical layers of latent variables to construct predictors for high-dimensional input-output models. Training a deep learning architecture is computationally intensive, and efficient linear algebra libraries is the key for training and inference. Stochastic gradient descent (SGD) optimization and batch sampling are used to learn from massive data sets.
Posterior Concentration for Sparse Deep Learning
Mar 24, 2018Spike-and-Slab Deep Learning (SS-DL) is a fully Bayesian alternative to Dropout for improving generalizability of deep ReLU networks. This new type of regularization enables provable recovery of smooth input-output maps with unknown levels of smoothness. Indeed, we show that the posterior distribution concentrates at the near minimax rate for $\alpha$-H\"older smooth maps, performing as well as if we knew the smoothness level $\alpha$ ahead of time. Our result sheds light on architecture design for deep neural networks, namely the choice of depth, width and sparsity level. These network attributes typically depend on unknown smoothness in order to be optimal. We obviate this constraint with the fully Bayes construction. As an aside, we show that SS-DL does not overfit in the sense that the posterior concentrates on smaller networks with fewer (up to the optimal number of) nodes and links. Our results provide new theoretical justifications for deep ReLU networks from a Bayesian point of view.
Deep Learning: A Bayesian Perspective
Nov 14, 2017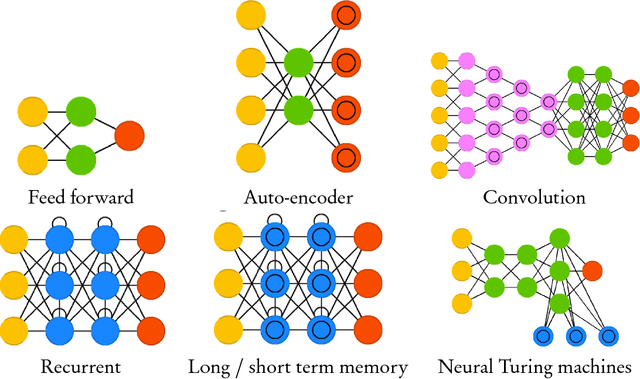
Deep learning is a form of machine learning for nonlinear high dimensional pattern matching and prediction. By taking a Bayesian probabilistic perspective, we provide a number of insights into more efficient algorithms for optimisation and hyper-parameter tuning. Traditional high-dimensional data reduction techniques, such as principal component analysis (PCA), partial least squares (PLS), reduced rank regression (RRR), projection pursuit regression (PPR) are all shown to be shallow learners. Their deep learning counterparts exploit multiple deep layers of data reduction which provide predictive performance gains. Stochastic gradient descent (SGD) training optimisation and Dropout (DO) regularization provide estimation and variable selection. Bayesian regularization is central to finding weights and connections in networks to optimize the predictive bias-variance trade-off. To illustrate our methodology, we provide an analysis of international bookings on Airbnb. Finally, we conclude with directions for future research.