 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepAFL: Deep Analytic Federated Learning
Feb 28, 2026Federated Learning (FL) is a popular distributed learning paradigm to break down data silo. Traditional FL approaches largely rely on gradient-based updates, facing significant issues about heterogeneity, scalability, convergence, and overhead, etc. Recently, some analytic-learning-based work has attempted to handle these issues by eliminating gradient-based updates via analytical (i.e., closed-form) solutions. Despite achieving superior invariance to data heterogeneity, these approaches are fundamentally limited by their single-layer linear model with a frozen pre-trained backbone. As a result, they can only achieve suboptimal performance due to their lack of representation learning capabilities. In this paper, to enable representable analytic models while preserving the ideal invariance to data heterogeneity for FL, we propose our Deep Analytic Federated Learning approach, named DeepAFL. Drawing inspiration from the great success of ResNet in gradient-based learning, we design gradient-free residual blocks in our DeepAFL with analytical solutions. We introduce an efficient layer-wise protocol for training our deep analytic models layer by layer in FL through least squares. Both theoretical analyses and empirical evaluations validate our DeepAFL's superior performance with its dual advantages in heterogeneity invariance and representation learning, outperforming state-of-the-art baselines by up to 5.68%-8.42% across three benchmark datasets.
AFCL: Analytic Federated Continual Learning for Spatio-Temporal Invariance of Non-IID Data
May 18, 2025Federated Continual Learning (FCL) enables distributed clients to collaboratively train a global model from online task streams in dynamic real-world scenarios. However, existing FCL methods face challenges of both spatial data heterogeneity among distributed clients and temporal data heterogeneity across online tasks. Such data heterogeneity significantly degrades the model performance with severe spatial-temporal catastrophic forgetting of local and past knowledge. In this paper, we identify that the root cause of this issue lies in the inherent vulnerability and sensitivity of gradients to non-IID data. To fundamentally address this issue, we propose a gradient-free method, named Analytic Federated Continual Learning (AFCL), by deriving analytical (i.e., closed-form) solutions from frozen extracted features. In local training, our AFCL enables single-epoch learning with only a lightweight forward-propagation process for each client. In global aggregation, the server can recursively and efficiently update the global model with single-round aggregation. Theoretical analyses validate that our AFCL achieves spatio-temporal invariance of non-IID data. This ideal property implies that, regardless of how heterogeneous the data are distributed across local clients and online tasks, the aggregated model of our AFCL remains invariant and identical to that of centralized joint learning. Extensive experiments show the consistent superiority of our AFCL over state-of-the-art baselines across various benchmark datasets and settings.
Analytic Subspace Routing: How Recursive Least Squares Works in Continual Learning of Large Language Model
Mar 17, 2025



Large Language Models (LLMs) possess encompassing capabilities that can process diverse language-related tasks. However, finetuning on LLMs will diminish this general skills and continual finetuning will further cause severe degradation on accumulated knowledge. Recently, Continual Learning (CL) in Large Language Models (LLMs) arises which aims to continually adapt the LLMs to new tasks while maintaining previously learned knowledge and inheriting general skills. Existing techniques either leverage previous data to replay, leading to extra computational costs, or utilize a single parameter-efficient module to learn the downstream task, constraining new knowledge absorption with interference between different tasks. Toward these issues, this paper proposes Analytic Subspace Routing(ASR) to address these challenges. For each task, we isolate the learning within a subspace of deep layers' features via low-rank adaptation, eliminating knowledge interference between different tasks. Additionally, we propose an analytic routing mechanism to properly utilize knowledge learned in different subspaces. Our approach employs Recursive Least Squares to train a multi-task router model, allowing the router to dynamically adapt to incoming data without requiring access to historical data. Also, the router effectively assigns the current task to an appropriate subspace and has a non-forgetting property of previously learned tasks with a solid theoretical guarantee. Experimental results demonstrate that our method achieves near-perfect retention of prior knowledge while seamlessly integrating new information, effectively overcoming the core limitations of existing methods. Our code will be released after acceptance.
Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Mar 07, 2025


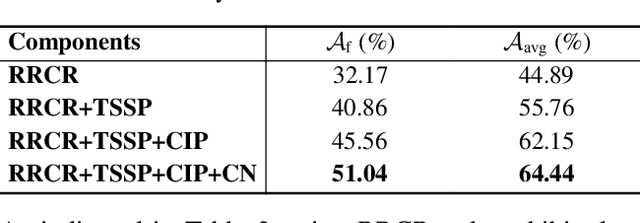
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, thereby hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate classifier training as a reconstruction process. This reconstruction exploits previous information encoded in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, across various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
Analytic Federated Learning
May 25, 2024
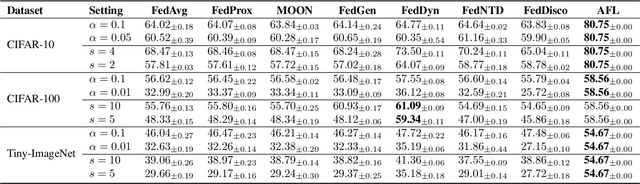


In this paper, we introduce analytic federated learning (AFL), a new training paradigm that brings analytical (i.e., closed-form) solutions to the federated learning (FL) community. Our AFL draws inspiration from analytic learning -- a gradient-free technique that trains neural networks with analytical solutions in one epoch. In the local client training stage, the AFL facilitates a one-epoch training, eliminating the necessity for multi-epoch updates. In the aggregation stage, we derive an absolute aggregation (AA) law. This AA law allows a single-round aggregation, removing the need for multiple aggregation rounds. More importantly, the AFL exhibits a \textit{weight-invariant} property, meaning that regardless of how the full dataset is distributed among clients, the aggregated result remains identical. This could spawn various potentials, such as data heterogeneity invariance, client-number invariance, absolute convergence, and being hyperparameter-free (our AFL is the first hyperparameter-free method in FL history). We conduct experiments across various FL settings including extremely non-IID ones, and scenarios with a large number of clients (e.g., $\ge 1000$). In all these settings, our AFL constantly performs competitively while existing FL techniques encounter various obstacles. Code is available at \url{https://github.com/ZHUANGHP/Analytic-federated-learning}
DS-AL: A Dual-Stream Analytic Learning for Exemplar-Free Class-Incremental Learning
Mar 26, 2024



Class-incremental learning (CIL) under an exemplar-free constraint has presented a significant challenge. Existing methods adhering to this constraint are prone to catastrophic forgetting, far more so than replay-based techniques that retain access to past samples. In this paper, to solve the exemplar-free CIL problem, we propose a Dual-Stream Analytic Learning (DS-AL) approach. The DS-AL contains a main stream offering an analytical (i.e., closed-form) linear solution, and a compensation stream improving the inherent under-fitting limitation due to adopting linear mapping. The main stream redefines the CIL problem into a Concatenated Recursive Least Squares (C-RLS) task, allowing an equivalence between the CIL and its joint-learning counterpart. The compensation stream is governed by a Dual-Activation Compensation (DAC) module. This module re-activates the embedding with a different activation function from the main stream one, and seeks fitting compensation by projecting the embedding to the null space of the main stream's linear mapping. Empirical results demonstrate that the DS-AL, despite being an exemplar-free technique, delivers performance comparable with or better than that of replay-based methods across various datasets, including CIFAR-100, ImageNet-100 and ImageNet-Full. Additionally, the C-RLS' equivalent property allows the DS-AL to execute CIL in a phase-invariant manner. This is evidenced by a never-before-seen 500-phase CIL ImageNet task, which performs on a level identical to a 5-phase one. Our codes are available at https://github.com/ZHUANGHP/Analytic-continual-learning.
G-ACIL: Analytic Learning for Exemplar-Free Generalized Class Incremental Learning
Mar 23, 2024



Class incremental learning (CIL) trains a network on sequential tasks with separated categories but suffers from catastrophic forgetting, where models quickly lose previously learned knowledge when acquiring new tasks. The generalized CIL (GCIL) aims to address the CIL problem in a more real-world scenario, where incoming data have mixed data categories and unknown sample size distribution, leading to intensified forgetting. Existing attempts for the GCIL either have poor performance, or invade data privacy by saving historical exemplars. To address this, in this paper, we propose an exemplar-free generalized analytic class incremental learning (G-ACIL). The G-ACIL adopts analytic learning (a gradient-free training technique), and delivers an analytical solution (i.e., closed-form) to the GCIL scenario. This solution is derived via decomposing the incoming data into exposed and unexposed classes, allowing an equivalence between the incremental learning and its joint training, i.e., the weight-invariant property. Such an equivalence is theoretically validated through matrix analysis tools, and hence contributes interpretability in GCIL. It is also empirically evidenced by experiments on various datasets and settings of GCIL. The results show that the G-ACIL exhibits leading performance with high robustness compared with existing competitive GCIL methods. Codes will be ready at https://github.com/ZHUANGHP/Analytic-continual-learning.
AOCIL: Exemplar-free Analytic Online Class Incremental Learning with Low Time and Resource Consumption
Mar 23, 2024



Online Class Incremental Learning (OCIL) aims to train the model in a task-by-task manner, where data arrive in mini-batches at a time while previous data are not accessible. A significant challenge is known as Catastrophic Forgetting, i.e., loss of the previous knowledge on old data. To address this, replay-based methods show competitive results but invade data privacy, while exemplar-free methods protect data privacy but struggle for accuracy. In this paper, we proposed an exemplar-free approach -- Analytic Online Class Incremental Learning (AOCIL). Instead of back-propagation, we design the Analytic Classifier (AC) updated by recursive least square, cooperating with a frozen backbone. AOCIL simultaneously achieves high accuracy, low resource consumption and data privacy protection. We conduct massive experiments on four existing benchmark datasets, and the results demonstrate the strong capability of handling OCIL scenarios. Codes will be ready.
REAL: Representation Enhanced Analytic Learning for Exemplar-free Class-incremental Learning
Mar 20, 2024



Exemplar-free class-incremental learning (EFCIL) aims to mitigate catastrophic forgetting in class-incremental learning without available historical data. Compared with its counterpart (replay-based CIL) that stores historical samples, the EFCIL suffers more from forgetting issues under the exemplar-free constraint. In this paper, inspired by the recently developed analytic learning (AL) based CIL, we propose a representation enhanced analytic learning (REAL) for EFCIL. The REAL constructs a dual-stream base pretraining (DS-BPT) and a representation enhancing distillation (RED) process to enhance the representation of the extractor. The DS-BPT pretrains model in streams of both supervised learning and self-supervised contrastive learning (SSCL) for base knowledge extraction. The RED process distills the supervised knowledge to the SSCL pretrained backbone and facilitates a subsequent AL-basd CIL that converts the CIL to a recursive least-square problem. Our method addresses the issue of insufficient discriminability in representations of unseen data caused by a frozen backbone in the existing AL-based CIL. Empirical results on various datasets including CIFAR-100, ImageNet-100 and ImageNet-1k, demonstrate that our REAL outperforms the state-of-the-arts in EFCIL, and achieves comparable or even more superior performance compared with the replay-based methods.