 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteraction-aware Representation Modeling with Co-occurrence Consistency for Egocentric Hand-Object Parsing
Feb 24, 2026A fine-grained understanding of egocentric human-environment interactions is crucial for developing next-generation embodied agents. One fundamental challenge in this area involves accurately parsing hands and active objects. While transformer-based architectures have demonstrated considerable potential for such tasks, several key limitations remain unaddressed: 1) existing query initialization mechanisms rely primarily on semantic cues or learnable parameters, demonstrating limited adaptability to changing active objects across varying input scenes; 2) previous transformer-based methods utilize pixel-level semantic features to iteratively refine queries during mask generation, which may introduce interaction-irrelevant content into the final embeddings; and 3) prevailing models are susceptible to "interaction illusion", producing physically inconsistent predictions. To address these issues, we propose an end-to-end Interaction-aware Transformer (InterFormer), which integrates three key components, i.e., a Dynamic Query Generator (DQG), a Dual-context Feature Selector (DFS), and the Conditional Co-occurrence (CoCo) loss. The DQG explicitly grounds query initialization in the spatial dynamics of hand-object contact, enabling targeted generation of interaction-aware queries for hands and various active objects. The DFS fuses coarse interactive cues with semantic features, thereby suppressing interaction-irrelevant noise and emphasizing the learning of interactive relationships. The CoCo loss incorporates hand-object relationship constraints to enhance physical consistency in prediction. Our model achieves state-of-the-art performance on both the EgoHOS and the challenging out-of-distribution mini-HOI4D datasets, demonstrating its effectiveness and strong generalization ability. Code and models are publicly available at https://github.com/yuggiehk/InterFormer.
LaSSM: Efficient Semantic-Spatial Query Decoding via Local Aggregation and State Space Models for 3D Instance Segmentation
Feb 11, 2026Query-based 3D scene instance segmentation from point clouds has attained notable performance. However, existing methods suffer from the query initialization dilemma due to the sparse nature of point clouds and rely on computationally intensive attention mechanisms in query decoders. We accordingly introduce LaSSM, prioritizing simplicity and efficiency while maintaining competitive performance. Specifically, we propose a hierarchical semantic-spatial query initializer to derive the query set from superpoints by considering both semantic cues and spatial distribution, achieving comprehensive scene coverage and accelerated convergence. We further present a coordinate-guided state space model (SSM) decoder that progressively refines queries. The novel decoder features a local aggregation scheme that restricts the model to focus on geometrically coherent regions and a spatial dual-path SSM block to capture underlying dependencies within the query set by integrating associated coordinates information. Our design enables efficient instance prediction, avoiding the incorporation of noisy information and reducing redundant computation. LaSSM ranks first place on the latest ScanNet++ V2 leaderboard, outperforming the previous best method by 2.5% mAP with only 1/3 FLOPs, demonstrating its superiority in challenging large-scale scene instance segmentation. LaSSM also achieves competitive performance on ScanNet, ScanNet200, S3DIS and ScanNet++ V1 benchmarks with less computational cost. Extensive ablation studies and qualitative results validate the effectiveness of our design. The code and weights are available at https://github.com/RayYoh/LaSSM.
3DGeoDet: General-purpose Geometry-aware Image-based 3D Object Detection
Jun 11, 2025This paper proposes 3DGeoDet, a novel geometry-aware 3D object detection approach that effectively handles single- and multi-view RGB images in indoor and outdoor environments, showcasing its general-purpose applicability. The key challenge for image-based 3D object detection tasks is the lack of 3D geometric cues, which leads to ambiguity in establishing correspondences between images and 3D representations. To tackle this problem, 3DGeoDet generates efficient 3D geometric representations in both explicit and implicit manners based on predicted depth information. Specifically, we utilize the predicted depth to learn voxel occupancy and optimize the voxelized 3D feature volume explicitly through the proposed voxel occupancy attention. To further enhance 3D awareness, the feature volume is integrated with an implicit 3D representation, the truncated signed distance function (TSDF). Without requiring supervision from 3D signals, we significantly improve the model's comprehension of 3D geometry by leveraging intermediate 3D representations and achieve end-to-end training. Our approach surpasses the performance of state-of-the-art image-based methods on both single- and multi-view benchmark datasets across diverse environments, achieving a 9.3 mAP@0.5 improvement on the SUN RGB-D dataset, a 3.3 mAP@0.5 improvement on the ScanNetV2 dataset, and a 0.19 AP3D@0.7 improvement on the KITTI dataset. The project page is available at: https://cindy0725.github.io/3DGeoDet/.
Analytic Subspace Routing: How Recursive Least Squares Works in Continual Learning of Large Language Model
Mar 17, 2025



Large Language Models (LLMs) possess encompassing capabilities that can process diverse language-related tasks. However, finetuning on LLMs will diminish this general skills and continual finetuning will further cause severe degradation on accumulated knowledge. Recently, Continual Learning (CL) in Large Language Models (LLMs) arises which aims to continually adapt the LLMs to new tasks while maintaining previously learned knowledge and inheriting general skills. Existing techniques either leverage previous data to replay, leading to extra computational costs, or utilize a single parameter-efficient module to learn the downstream task, constraining new knowledge absorption with interference between different tasks. Toward these issues, this paper proposes Analytic Subspace Routing(ASR) to address these challenges. For each task, we isolate the learning within a subspace of deep layers' features via low-rank adaptation, eliminating knowledge interference between different tasks. Additionally, we propose an analytic routing mechanism to properly utilize knowledge learned in different subspaces. Our approach employs Recursive Least Squares to train a multi-task router model, allowing the router to dynamically adapt to incoming data without requiring access to historical data. Also, the router effectively assigns the current task to an appropriate subspace and has a non-forgetting property of previously learned tasks with a solid theoretical guarantee. Experimental results demonstrate that our method achieves near-perfect retention of prior knowledge while seamlessly integrating new information, effectively overcoming the core limitations of existing methods. Our code will be released after acceptance.
Semantic Shift Estimation via Dual-Projection and Classifier Reconstruction for Exemplar-Free Class-Incremental Learning
Mar 07, 2025


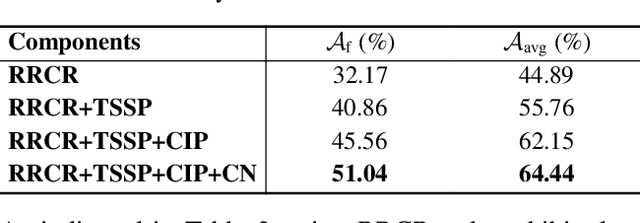
Exemplar-Free Class-Incremental Learning (EFCIL) aims to sequentially learn from distinct categories without retaining exemplars but easily suffers from catastrophic forgetting of learned knowledge. While existing EFCIL methods leverage knowledge distillation to alleviate forgetting, they still face two critical challenges: semantic shift and decision bias. Specifically, the embeddings of old tasks shift in the embedding space after learning new tasks, and the classifier becomes biased towards new tasks due to training solely with new data, thereby hindering the balance between old and new knowledge. To address these issues, we propose the Dual-Projection Shift Estimation and Classifier Reconstruction (DPCR) approach for EFCIL. DPCR effectively estimates semantic shift through a dual-projection, which combines a learnable transformation with a row-space projection to capture both task-wise and category-wise shifts. Furthermore, to mitigate decision bias, DPCR employs ridge regression to reformulate classifier training as a reconstruction process. This reconstruction exploits previous information encoded in covariance and prototype of each class after calibration with estimated shift, thereby reducing decision bias. Extensive experiments demonstrate that, across various datasets, DPCR effectively balances old and new tasks, outperforming state-of-the-art EFCIL methods.
EPE-P: Evidence-based Parameter-efficient Prompting for Multimodal Learning with Missing Modalities
Dec 23, 2024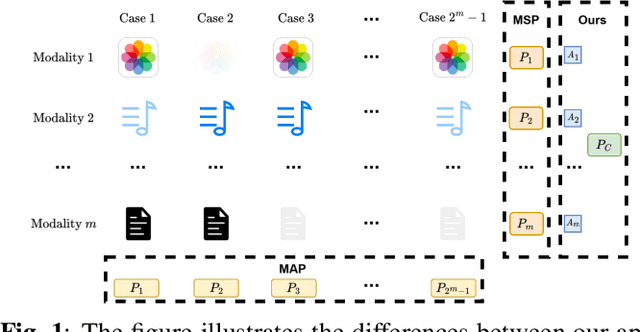
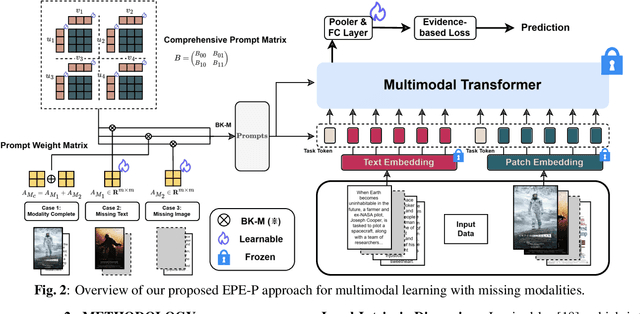
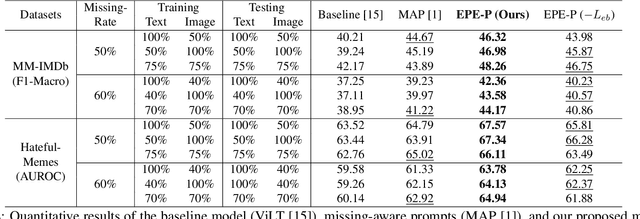
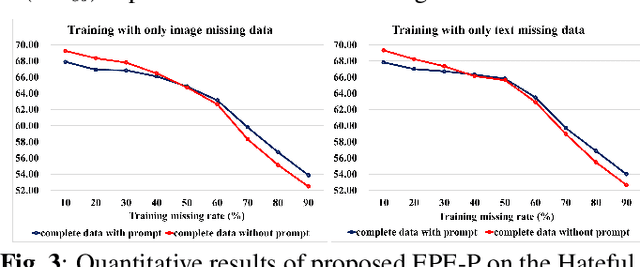
Missing modalities are a common challenge in real-world multimodal learning scenarios, occurring during both training and testing. Existing methods for managing missing modalities often require the design of separate prompts for each modality or missing case, leading to complex designs and a substantial increase in the number of parameters to be learned. As the number of modalities grows, these methods become increasingly inefficient due to parameter redundancy. To address these issues, we propose Evidence-based Parameter-Efficient Prompting (EPE-P), a novel and parameter-efficient method for pretrained multimodal networks. Our approach introduces a streamlined design that integrates prompting information across different modalities, reducing complexity and mitigating redundant parameters. Furthermore, we propose an Evidence-based Loss function to better handle the uncertainty associated with missing modalities, improving the model's decision-making. Our experiments demonstrate that EPE-P outperforms existing prompting-based methods in terms of both effectiveness and efficiency. The code is released at https://github.com/Boris-Jobs/EPE-P_MLLMs-Robustness.
Prior-free Balanced Replay: Uncertainty-guided Reservoir Sampling for Long-Tailed Continual Learning
Aug 27, 2024Even in the era of large models, one of the well-known issues in continual learning (CL) is catastrophic forgetting, which is significantly challenging when the continual data stream exhibits a long-tailed distribution, termed as Long-Tailed Continual Learning (LTCL). Existing LTCL solutions generally require the label distribution of the data stream to achieve re-balance training. However, obtaining such prior information is often infeasible in real scenarios since the model should learn without pre-identifying the majority and minority classes. To this end, we propose a novel Prior-free Balanced Replay (PBR) framework to learn from long-tailed data stream with less forgetting. Concretely, motivated by our experimental finding that the minority classes are more likely to be forgotten due to the higher uncertainty, we newly design an uncertainty-guided reservoir sampling strategy to prioritize rehearsing minority data without using any prior information, which is based on the mutual dependence between the model and samples. Additionally, we incorporate two prior-free components to further reduce the forgetting issue: (1) Boundary constraint is to preserve uncertain boundary supporting samples for continually re-estimating task boundaries. (2) Prototype constraint is to maintain the consistency of learned class prototypes along with training. Our approach is evaluated on three standard long-tailed benchmarks, demonstrating superior performance to existing CL methods and previous SOTA LTCL approach in both task- and class-incremental learning settings, as well as ordered- and shuffled-LTCL settings.
TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model
Aug 22, 2024



The vision-language modeling capability of multi-modal large language models has attracted wide attention from the community. However, in medical domain, radiology report generation using vision-language models still faces significant challenges due to the imbalanced data distribution caused by numerous negated descriptions in radiology reports and issues such as rough alignment between radiology reports and radiography. In this paper, we propose a truthful radiology report generation framework, namely TRRG, based on stage-wise training for cross-modal disease clue injection into large language models. In pre-training stage, During the pre-training phase, contrastive learning is employed to enhance the ability of visual encoder to perceive fine-grained disease details. In fine-tuning stage, the clue injection module we proposed significantly enhances the disease-oriented perception capability of the large language model by effectively incorporating the robust zero-shot disease perception. Finally, through the cross-modal clue interaction module, our model effectively achieves the multi-granular interaction of visual embeddings and an arbitrary number of disease clue embeddings. This significantly enhances the report generation capability and clinical effectiveness of multi-modal large language models in the field of radiology reportgeneration. Experimental results demonstrate that our proposed pre-training and fine-tuning framework achieves state-of-the-art performance in radiology report generation on datasets such as IU-Xray and MIMIC-CXR. Further analysis indicates that our proposed method can effectively enhance the model to perceive diseases and improve its clinical effectiveness.
DAAD: Dynamic Analysis and Adaptive Discriminator for Fake News Detection
Aug 20, 2024In current web environment, fake news spreads rapidly across online social networks, posing serious threats to society. Existing multimodal fake news detection (MFND) methods can be classified into knowledge-based and semantic-based approaches. However, these methods are overly dependent on human expertise and feedback, lacking flexibility. To address this challenge, we propose a Dynamic Analysis and Adaptive Discriminator (DAAD) approach for fake news detection. For knowledge-based methods, we introduce the Monte Carlo Tree Search (MCTS) algorithm to leverage the self-reflective capabilities of large language models (LLMs) for prompt optimization, providing richer, domain-specific details and guidance to the LLMs, while enabling more flexible integration of LLM comment on news content. For semantic-based methods, we define four typical deceit patterns: emotional exaggeration, logical inconsistency, image manipulation, and semantic inconsistency, to reveal the mechanisms behind fake news creation. To detect these patterns, we carefully design four discriminators and expand them in depth and breadth, using the soft-routing mechanism to explore optimal detection models. Experimental results on three real-world datasets demonstrate the superiority of our approach. The code will be available at: https://github.com/SuXinqi/DAAD.
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
Apr 15, 2024Multi-modal image fusion aims to combine information from different modes to create a single image with comprehensive information and detailed textures. However, fusion models based on convolutional neural networks encounter limitations in capturing global image features due to their focus on local convolution operations. Transformer-based models, while excelling in global feature modeling, confront computational challenges stemming from their quadratic complexity. Recently, the Selective Structured State Space Model has exhibited significant potential for long-range dependency modeling with linear complexity, offering a promising avenue to address the aforementioned dilemma. In this paper, we propose FusionMamba, a novel dynamic feature enhancement method for multimodal image fusion with Mamba. Specifically, we devise an improved efficient Mamba model for image fusion, integrating efficient visual state space model with dynamic convolution and channel attention. This refined model not only upholds the performance of Mamba and global modeling capability but also diminishes channel redundancy while enhancing local enhancement capability. Additionally, we devise a dynamic feature fusion module (DFFM) comprising two dynamic feature enhancement modules (DFEM) and a cross modality fusion mamba module (CMFM). The former serves for dynamic texture enhancement and dynamic difference perception, whereas the latter enhances correlation features between modes and suppresses redundant intermodal information. FusionMamba has yielded state-of-the-art (SOTA) performance across various multimodal medical image fusion tasks (CT-MRI, PET-MRI, SPECT-MRI), infrared and visible image fusion task (IR-VIS) and multimodal biomedical image fusion dataset (GFP-PC), which is proved that our model has generalization ability. The code for FusionMamba is available at https://github.com/millieXie/FusionMamba.