 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Deconfounded Image-Text Matching with Causal Inference
Aug 22, 2024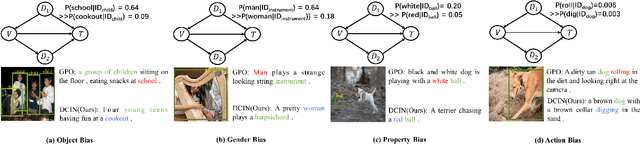
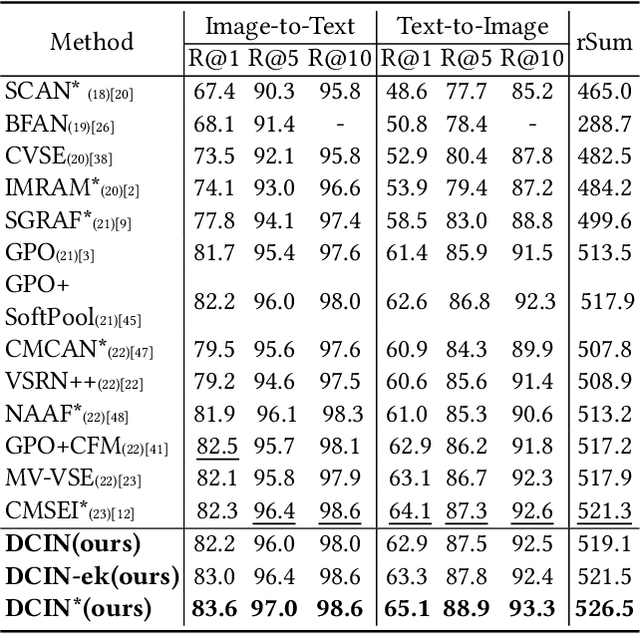
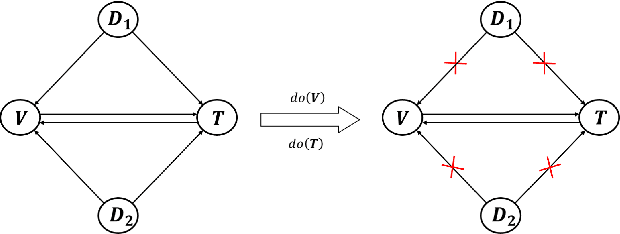
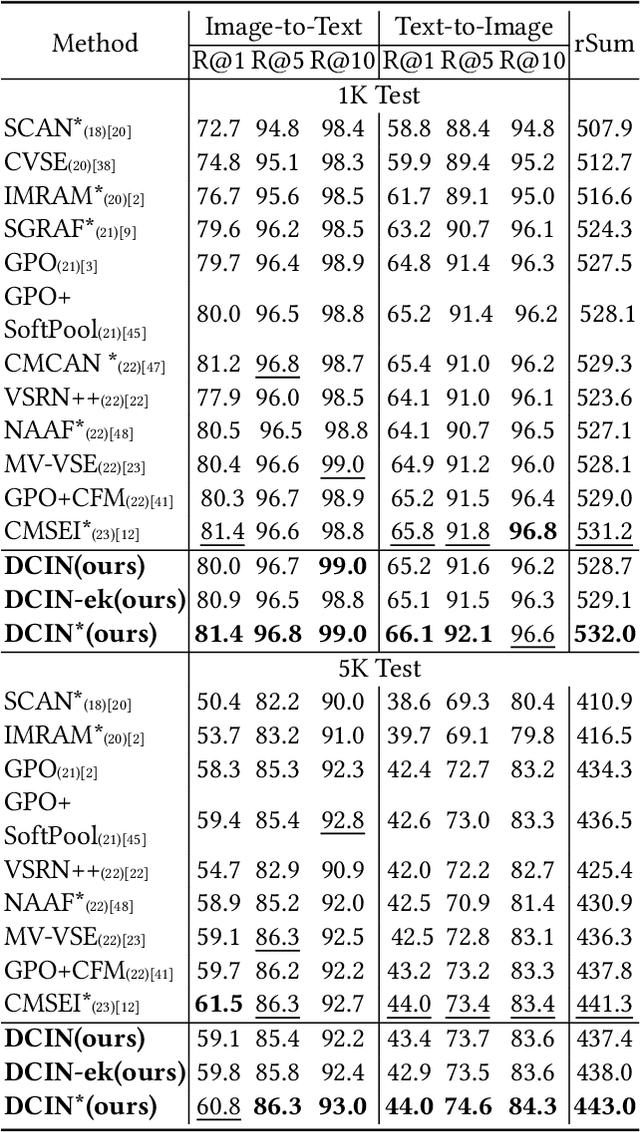
Prior image-text matching methods have shown remarkable performance on many benchmark datasets, but most of them overlook the bias in the dataset, which exists in intra-modal and inter-modal, and tend to learn the spurious correlations that extremely degrade the generalization ability of the model. Furthermore, these methods often incorporate biased external knowledge from large-scale datasets as prior knowledge into image-text matching model, which is inevitable to force model further learn biased associations. To address above limitations, this paper firstly utilizes Structural Causal Models (SCMs) to illustrate how intra- and inter-modal confounders damage the image-text matching. Then, we employ backdoor adjustment to propose an innovative Deconfounded Causal Inference Network (DCIN) for image-text matching task. DCIN (1) decomposes the intra- and inter-modal confounders and incorporates them into the encoding stage of visual and textual features, effectively eliminating the spurious correlations during image-text matching, and (2) uses causal inference to mitigate biases of external knowledge. Consequently, the model can learn causality instead of spurious correlations caused by dataset bias. Extensive experiments on two well-known benchmark datasets, i.e., Flickr30K and MSCOCO, demonstrate the superiority of our proposed method.
* ACM MM
TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model
Aug 22, 2024



The vision-language modeling capability of multi-modal large language models has attracted wide attention from the community. However, in medical domain, radiology report generation using vision-language models still faces significant challenges due to the imbalanced data distribution caused by numerous negated descriptions in radiology reports and issues such as rough alignment between radiology reports and radiography. In this paper, we propose a truthful radiology report generation framework, namely TRRG, based on stage-wise training for cross-modal disease clue injection into large language models. In pre-training stage, During the pre-training phase, contrastive learning is employed to enhance the ability of visual encoder to perceive fine-grained disease details. In fine-tuning stage, the clue injection module we proposed significantly enhances the disease-oriented perception capability of the large language model by effectively incorporating the robust zero-shot disease perception. Finally, through the cross-modal clue interaction module, our model effectively achieves the multi-granular interaction of visual embeddings and an arbitrary number of disease clue embeddings. This significantly enhances the report generation capability and clinical effectiveness of multi-modal large language models in the field of radiology reportgeneration. Experimental results demonstrate that our proposed pre-training and fine-tuning framework achieves state-of-the-art performance in radiology report generation on datasets such as IU-Xray and MIMIC-CXR. Further analysis indicates that our proposed method can effectively enhance the model to perceive diseases and improve its clinical effectiveness.
DAAD: Dynamic Analysis and Adaptive Discriminator for Fake News Detection
Aug 20, 2024In current web environment, fake news spreads rapidly across online social networks, posing serious threats to society. Existing multimodal fake news detection (MFND) methods can be classified into knowledge-based and semantic-based approaches. However, these methods are overly dependent on human expertise and feedback, lacking flexibility. To address this challenge, we propose a Dynamic Analysis and Adaptive Discriminator (DAAD) approach for fake news detection. For knowledge-based methods, we introduce the Monte Carlo Tree Search (MCTS) algorithm to leverage the self-reflective capabilities of large language models (LLMs) for prompt optimization, providing richer, domain-specific details and guidance to the LLMs, while enabling more flexible integration of LLM comment on news content. For semantic-based methods, we define four typical deceit patterns: emotional exaggeration, logical inconsistency, image manipulation, and semantic inconsistency, to reveal the mechanisms behind fake news creation. To detect these patterns, we carefully design four discriminators and expand them in depth and breadth, using the soft-routing mechanism to explore optimal detection models. Experimental results on three real-world datasets demonstrate the superiority of our approach. The code will be available at: https://github.com/SuXinqi/DAAD.