 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Collaboration of Multi-Language Models based on Minimal Complete Semantic Units
Aug 26, 2025This paper investigates the enhancement of reasoning capabilities in language models through token-level multi-model collaboration. Our approach selects the optimal tokens from the next token distributions provided by multiple models to perform autoregressive reasoning. Contrary to the assumption that more models yield better results, we introduce a distribution distance-based dynamic selection strategy (DDS) to optimize the multi-model collaboration process. To address the critical challenge of vocabulary misalignment in multi-model collaboration, we propose the concept of minimal complete semantic units (MCSU), which is simple yet enables multiple language models to achieve natural alignment within the linguistic space. Experimental results across various benchmarks demonstrate the superiority of our method. The code will be available at https://github.com/Fanye12/DDS.
Distribution-Specific Learning for Joint Salient and Camouflaged Object Detection
Aug 08, 2025Salient object detection (SOD) and camouflaged object detection (COD) are two closely related but distinct computer vision tasks. Although both are class-agnostic segmentation tasks that map from RGB space to binary space, the former aims to identify the most salient objects in the image, while the latter focuses on detecting perfectly camouflaged objects that blend into the background in the image. These two tasks exhibit strong contradictory attributes. Previous works have mostly believed that joint learning of these two tasks would confuse the network, reducing its performance on both tasks. However, here we present an opposite perspective: with the correct approach to learning, the network can simultaneously possess the capability to find both salient and camouflaged objects, allowing both tasks to benefit from joint learning. We propose SCJoint, a joint learning scheme for SOD and COD tasks, assuming that the decoding processes of SOD and COD have different distribution characteristics. The key to our method is to learn the respective means and variances of the decoding processes for both tasks by inserting a minimal amount of task-specific learnable parameters within a fully shared network structure, thereby decoupling the contradictory attributes of the two tasks at a minimal cost. Furthermore, we propose a saliency-based sampling strategy (SBSS) to sample the training set of the SOD task to balance the training set sizes of the two tasks. In addition, SBSS improves the training set quality and shortens the training time. Based on the proposed SCJoint and SBSS, we train a powerful generalist network, named JoNet, which has the ability to simultaneously capture both ``salient" and ``camouflaged". Extensive experiments demonstrate the competitive performance and effectiveness of our proposed method. The code is available at https://github.com/linuxsino/JoNet.
Uncertainty-Aware GUI Agent: Adaptive Perception through Component Recommendation and Human-in-the-Loop Refinement
Aug 06, 2025Graphical user interface (GUI) agents have shown promise in automating mobile tasks but still struggle with input redundancy and decision ambiguity. In this paper, we present \textbf{RecAgent}, an uncertainty-aware agent that addresses these issues through adaptive perception. We distinguish two types of uncertainty in GUI navigation: (1) perceptual uncertainty, caused by input redundancy and noise from comprehensive screen information, and (2) decision uncertainty, arising from ambiguous tasks and complex reasoning. To reduce perceptual uncertainty, RecAgent employs a component recommendation mechanism that identifies and focuses on the most relevant UI elements. For decision uncertainty, it uses an interactive module to request user feedback in ambiguous situations, enabling intent-aware decisions. These components are integrated into a unified framework that proactively reduces input complexity and reacts to high-uncertainty cases via human-in-the-loop refinement. Additionally, we propose a dataset called \textbf{ComplexAction} to evaluate the success rate of GUI agents in executing specified single-step actions within complex scenarios. Extensive experiments validate the effectiveness of our approach. The dataset and code will be available at https://github.com/Fanye12/RecAgent.
LangTime: A Language-Guided Unified Model for Time Series Forecasting with Proximal Policy Optimization
Mar 11, 2025



Recent research has shown an increasing interest in utilizing pre-trained large language models (LLMs) for a variety of time series applications. However, there are three main challenges when using LLMs as foundational models for time series forecasting: (1) Cross-domain generalization. (2) Cross-modality alignment. (3) Error accumulation in autoregressive frameworks. To address these challenges, we proposed LangTime, a language-guided unified model for time series forecasting that incorporates cross-domain pre-training with reinforcement learning-based fine-tuning. Specifically, LangTime constructs Temporal Comprehension Prompts (TCPs), which include dataset-wise and channel-wise instructions, to facilitate domain adaptation and condense time series into a single token, enabling LLMs to understand better and align temporal data. To improve autoregressive forecasting, we introduce TimePPO, a reinforcement learning-based fine-tuning algorithm. TimePPO mitigates error accumulation by leveraging a multidimensional rewards function tailored for time series and a repeat-based value estimation strategy. Extensive experiments demonstrate that LangTime achieves state-of-the-art cross-domain forecasting performance, while TimePPO fine-tuning effectively enhances the stability and accuracy of autoregressive forecasting.
TRRG: Towards Truthful Radiology Report Generation With Cross-modal Disease Clue Enhanced Large Language Model
Aug 22, 2024



The vision-language modeling capability of multi-modal large language models has attracted wide attention from the community. However, in medical domain, radiology report generation using vision-language models still faces significant challenges due to the imbalanced data distribution caused by numerous negated descriptions in radiology reports and issues such as rough alignment between radiology reports and radiography. In this paper, we propose a truthful radiology report generation framework, namely TRRG, based on stage-wise training for cross-modal disease clue injection into large language models. In pre-training stage, During the pre-training phase, contrastive learning is employed to enhance the ability of visual encoder to perceive fine-grained disease details. In fine-tuning stage, the clue injection module we proposed significantly enhances the disease-oriented perception capability of the large language model by effectively incorporating the robust zero-shot disease perception. Finally, through the cross-modal clue interaction module, our model effectively achieves the multi-granular interaction of visual embeddings and an arbitrary number of disease clue embeddings. This significantly enhances the report generation capability and clinical effectiveness of multi-modal large language models in the field of radiology reportgeneration. Experimental results demonstrate that our proposed pre-training and fine-tuning framework achieves state-of-the-art performance in radiology report generation on datasets such as IU-Xray and MIMIC-CXR. Further analysis indicates that our proposed method can effectively enhance the model to perceive diseases and improve its clinical effectiveness.
From Recognition to Prediction: Leveraging Sequence Reasoning for Action Anticipation
Aug 05, 2024



The action anticipation task refers to predicting what action will happen based on observed videos, which requires the model to have a strong ability to summarize the present and then reason about the future. Experience and common sense suggest that there is a significant correlation between different actions, which provides valuable prior knowledge for the action anticipation task. However, previous methods have not effectively modeled this underlying statistical relationship. To address this issue, we propose a novel end-to-end video modeling architecture that utilizes attention mechanisms, named Anticipation via Recognition and Reasoning (ARR). ARR decomposes the action anticipation task into action recognition and sequence reasoning tasks, and effectively learns the statistical relationship between actions by next action prediction (NAP). In comparison to existing temporal aggregation strategies, ARR is able to extract more effective features from observable videos to make more reasonable predictions. In addition, to address the challenge of relationship modeling that requires extensive training data, we propose an innovative approach for the unsupervised pre-training of the decoder, which leverages the inherent temporal dynamics of video to enhance the reasoning capabilities of the network. Extensive experiments on the Epic-kitchen-100, EGTEA Gaze+, and 50salads datasets demonstrate the efficacy of the proposed methods. The code is available at https://github.com/linuxsino/ARR.
A Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Feb 29, 2024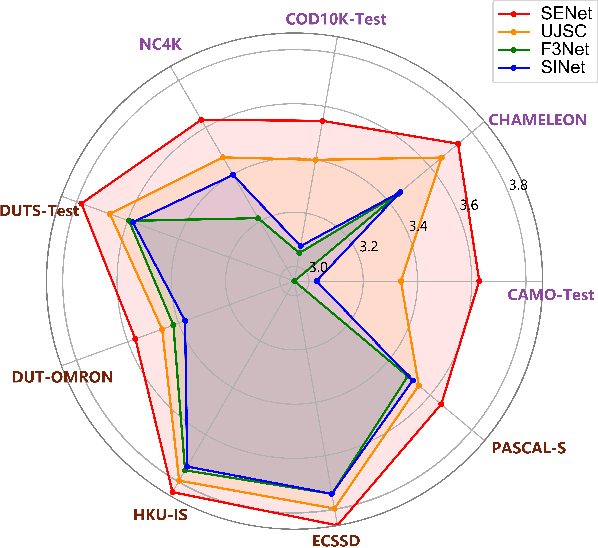
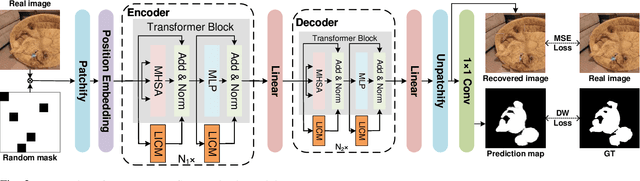
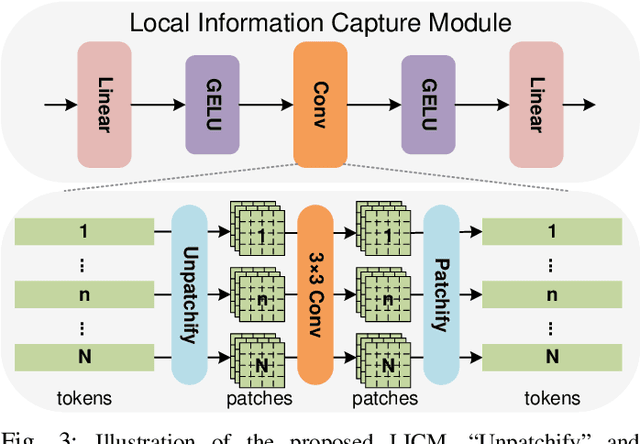
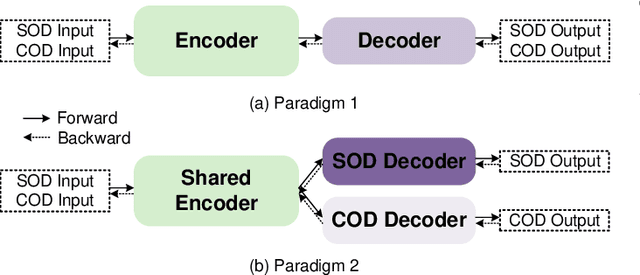
Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.
NSP-BERT: A Prompt-based Zero-Shot Learner Through an Original Pre-training Task--Next Sentence Prediction
Sep 08, 2021
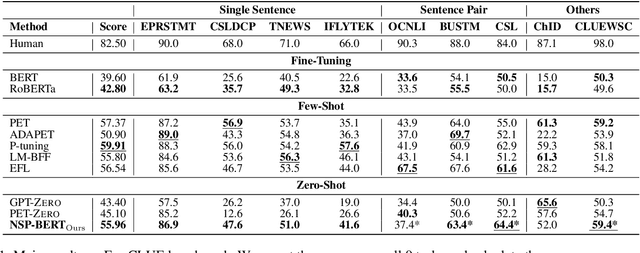

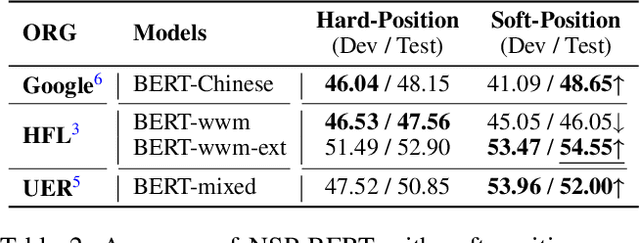
Using prompts to utilize language models to perform various downstream tasks, also known as prompt-based learning or prompt-learning, has lately gained significant success in comparison to the pre-train and fine-tune paradigm. Nonetheless, virtually all prompt-based methods are token-level, meaning they all utilize GPT's left-to-right language model or BERT's masked language model to perform cloze-style tasks. In this paper, we attempt to accomplish several NLP tasks in the zero-shot scenario using a BERT original pre-training task abandoned by RoBERTa and other models--Next Sentence Prediction (NSP). Unlike token-level techniques, our sentence-level prompt-based method NSP-BERT does not need to fix the length of the prompt or the position to be predicted, allowing it to handle tasks such as entity linking with ease. Based on the characteristics of NSP-BERT, we offer several quick building templates for various downstream tasks. We suggest a two-stage prompt method for word sense disambiguation tasks in particular. Our strategies for mapping the labels significantly enhance the model's performance on sentence pair tasks. On the FewCLUE benchmark, our NSP-BERT outperforms other zero-shot methods on most of these tasks and comes close to the few-shot methods.