 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple yet Effective Network based on Vision Transformer for Camouflaged Object and Salient Object Detection
Paper and Code
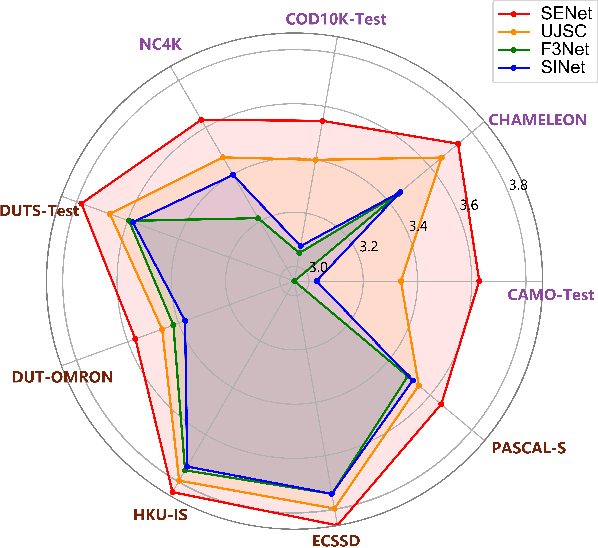
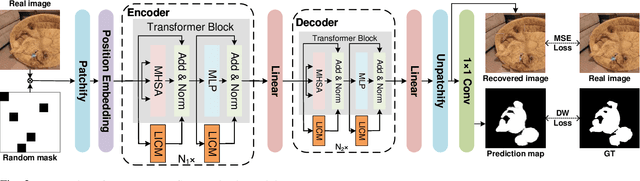
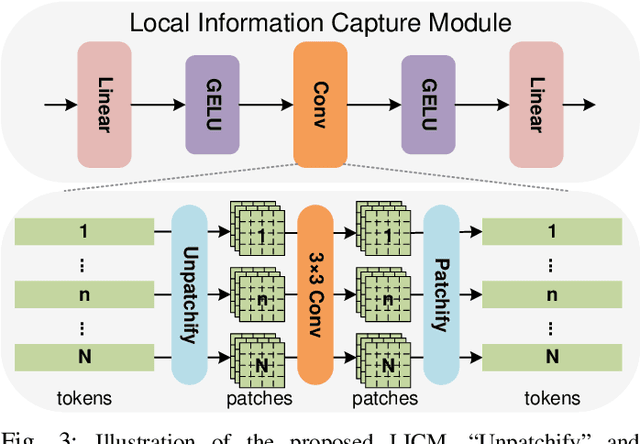
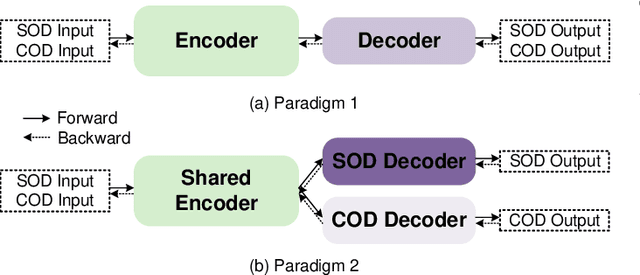
Camouflaged object detection (COD) and salient object detection (SOD) are two distinct yet closely-related computer vision tasks widely studied during the past decades. Though sharing the same purpose of segmenting an image into binary foreground and background regions, their distinction lies in the fact that COD focuses on concealed objects hidden in the image, while SOD concentrates on the most prominent objects in the image. Previous works achieved good performance by stacking various hand-designed modules and multi-scale features. However, these carefully-designed complex networks often performed well on one task but not on another. In this work, we propose a simple yet effective network (SENet) based on vision Transformer (ViT), by employing a simple design of an asymmetric ViT-based encoder-decoder structure, we yield competitive results on both tasks, exhibiting greater versatility than meticulously crafted ones. Furthermore, to enhance the Transformer's ability to model local information, which is important for pixel-level binary segmentation tasks, we propose a local information capture module (LICM). We also propose a dynamic weighted loss (DW loss) based on Binary Cross-Entropy (BCE) and Intersection over Union (IoU) loss, which guides the network to pay more attention to those smaller and more difficult-to-find target objects according to their size. Moreover, we explore the issue of joint training of SOD and COD, and propose a preliminary solution to the conflict in joint training, further improving the performance of SOD. Extensive experiments on multiple benchmark datasets demonstrate the effectiveness of our method. The code is available at https://github.com/linuxsino/SENet.