 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning Techniques for Video Instance Segmentation: A Survey
Oct 19, 2023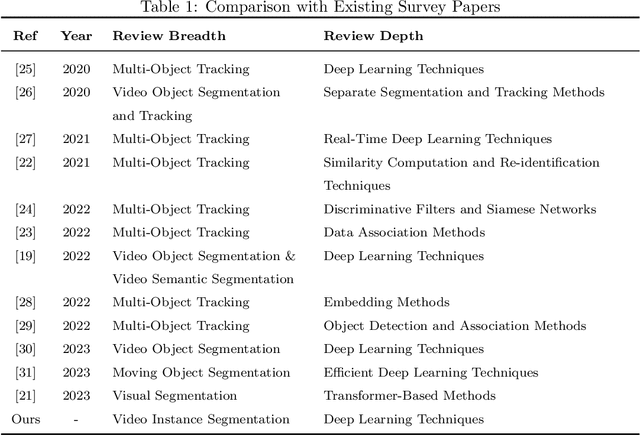


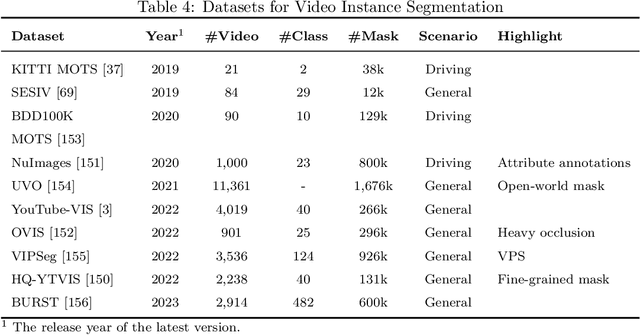
Video instance segmentation, also known as multi-object tracking and segmentation, is an emerging computer vision research area introduced in 2019, aiming at detecting, segmenting, and tracking instances in videos simultaneously. By tackling the video instance segmentation tasks through effective analysis and utilization of visual information in videos, a range of computer vision-enabled applications (e.g., human action recognition, medical image processing, autonomous vehicle navigation, surveillance, etc) can be implemented. As deep-learning techniques take a dominant role in various computer vision areas, a plethora of deep-learning-based video instance segmentation schemes have been proposed. This survey offers a multifaceted view of deep-learning schemes for video instance segmentation, covering various architectural paradigms, along with comparisons of functional performance, model complexity, and computational overheads. In addition to the common architectural designs, auxiliary techniques for improving the performance of deep-learning models for video instance segmentation are compiled and discussed. Finally, we discuss a range of major challenges and directions for further investigations to help advance this promising research field.
S-Adapter: Generalizing Vision Transformer for Face Anti-Spoofing with Statistical Tokens
Sep 07, 2023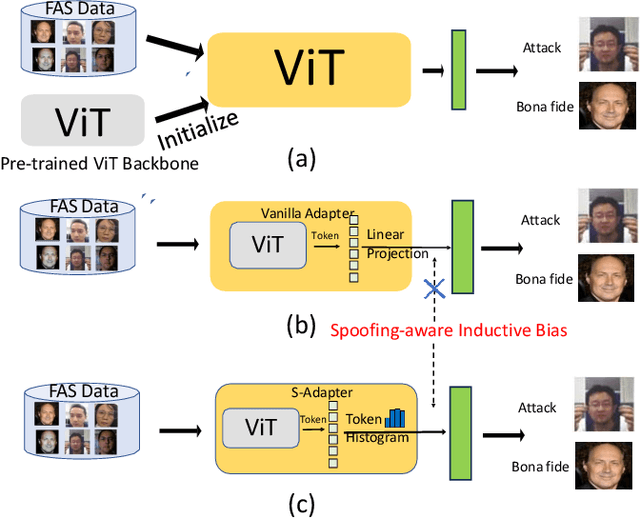
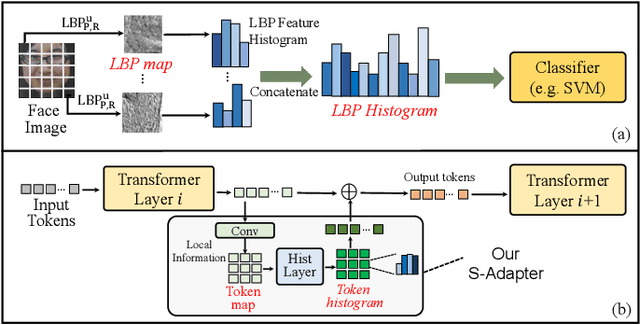
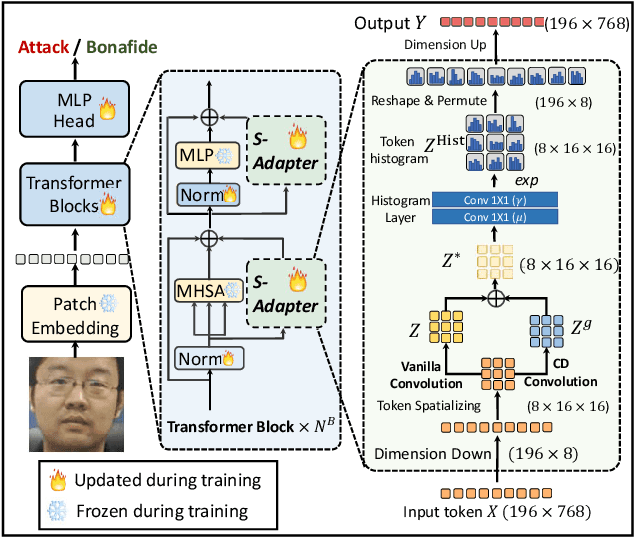
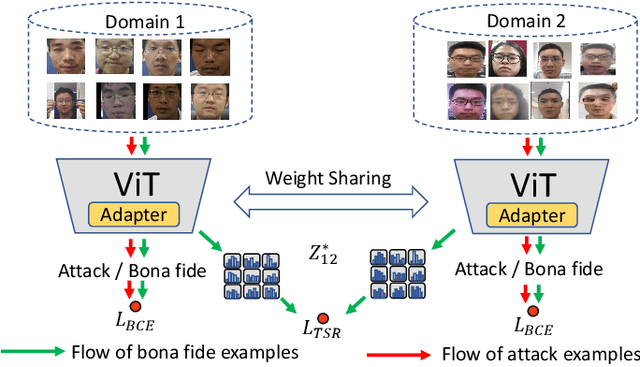
Face Anti-Spoofing (FAS) aims to detect malicious attempts to invade a face recognition system by presenting spoofed faces. State-of-the-art FAS techniques predominantly rely on deep learning models but their cross-domain generalization capabilities are often hindered by the domain shift problem, which arises due to different distributions between training and testing data. In this study, we develop a generalized FAS method under the Efficient Parameter Transfer Learning (EPTL) paradigm, where we adapt the pre-trained Vision Transformer models for the FAS task. During training, the adapter modules are inserted into the pre-trained ViT model, and the adapters are updated while other pre-trained parameters remain fixed. We find the limitations of previous vanilla adapters in that they are based on linear layers, which lack a spoofing-aware inductive bias and thus restrict the cross-domain generalization. To address this limitation and achieve cross-domain generalized FAS, we propose a novel Statistical Adapter (S-Adapter) that gathers local discriminative and statistical information from localized token histograms. To further improve the generalization of the statistical tokens, we propose a novel Token Style Regularization (TSR), which aims to reduce domain style variance by regularizing Gram matrices extracted from tokens across different domains. Our experimental results demonstrate that our proposed S-Adapter and TSR provide significant benefits in both zero-shot and few-shot cross-domain testing, outperforming state-of-the-art methods on several benchmark tests. We will release the source code upon acceptance.
Hyperbolic Face Anti-Spoofing
Aug 17, 2023



Learning generalized face anti-spoofing (FAS) models against presentation attacks is essential for the security of face recognition systems. Previous FAS methods usually encourage models to extract discriminative features, of which the distances within the same class (bonafide or attack) are pushed close while those between bonafide and attack are pulled away. However, these methods are designed based on Euclidean distance, which lacks generalization ability for unseen attack detection due to poor hierarchy embedding ability. According to the evidence that different spoofing attacks are intrinsically hierarchical, we propose to learn richer hierarchical and discriminative spoofing cues in hyperbolic space. Specifically, for unimodal FAS learning, the feature embeddings are projected into the Poincar\'e ball, and then the hyperbolic binary logistic regression layer is cascaded for classification. To further improve generalization, we conduct hyperbolic contrastive learning for the bonafide only while relaxing the constraints on diverse spoofing attacks. To alleviate the vanishing gradient problem in hyperbolic space, a new feature clipping method is proposed to enhance the training stability of hyperbolic models. Besides, we further design a multimodal FAS framework with Euclidean multimodal feature decomposition and hyperbolic multimodal feature fusion & classification. Extensive experiments on three benchmark datasets (i.e., WMCA, PADISI-Face, and SiW-M) with diverse attack types demonstrate that the proposed method can bring significant improvement compared to the Euclidean baselines on unseen attack detection. In addition, the proposed framework is also generalized well on four benchmark datasets (i.e., MSU-MFSD, IDIAP REPLAY-ATTACK, CASIA-FASD, and OULU-NPU) with a limited number of attack types.
Beyond the Prior Forgery Knowledge: Mining Critical Clues for General Face Forgery Detection
Apr 24, 2023Face forgery detection is essential in combating malicious digital face attacks. Previous methods mainly rely on prior expert knowledge to capture specific forgery clues, such as noise patterns, blending boundaries, and frequency artifacts. However, these methods tend to get trapped in local optima, resulting in limited robustness and generalization capability. To address these issues, we propose a novel Critical Forgery Mining (CFM) framework, which can be flexibly assembled with various backbones to boost their generalization and robustness performance. Specifically, we first build a fine-grained triplet and suppress specific forgery traces through prior knowledge-agnostic data augmentation. Subsequently, we propose a fine-grained relation learning prototype to mine critical information in forgeries through instance and local similarity-aware losses. Moreover, we design a novel progressive learning controller to guide the model to focus on principal feature components, enabling it to learn critical forgery features in a coarse-to-fine manner. The proposed method achieves state-of-the-art forgery detection performance under various challenging evaluation settings.
Self-Supervised 3D Action Representation Learning with Skeleton Cloud Colorization
Apr 19, 2023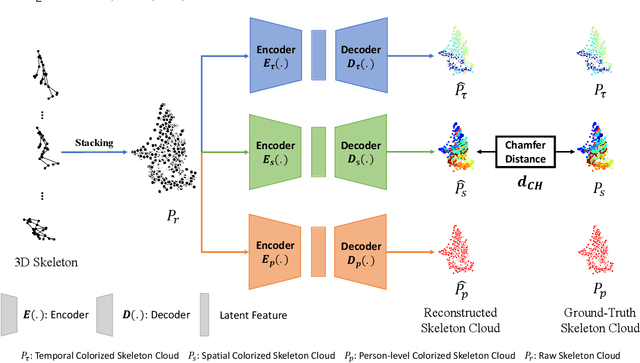
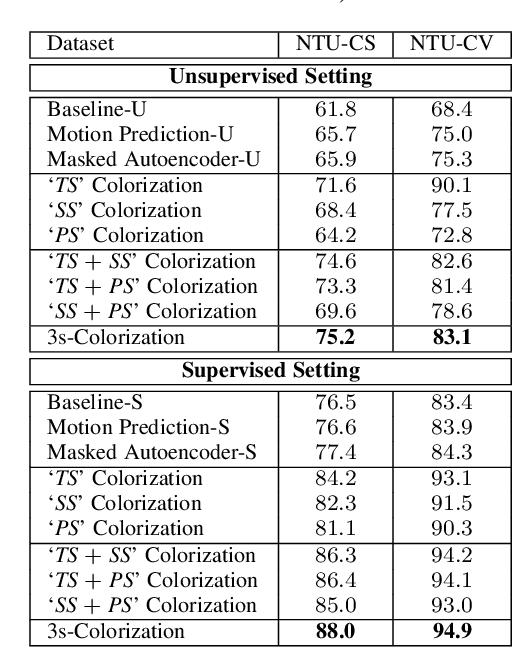

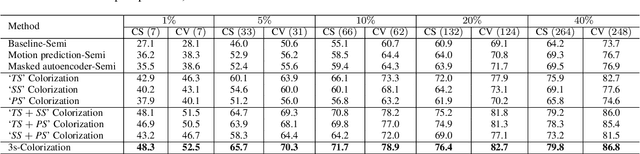
3D Skeleton-based human action recognition has attracted increasing attention in recent years. Most of the existing work focuses on supervised learning which requires a large number of labeled action sequences that are often expensive and time-consuming to annotate. In this paper, we address self-supervised 3D action representation learning for skeleton-based action recognition. We investigate self-supervised representation learning and design a novel skeleton cloud colorization technique that is capable of learning spatial and temporal skeleton representations from unlabeled skeleton sequence data. We represent a skeleton action sequence as a 3D skeleton cloud and colorize each point in the cloud according to its temporal and spatial orders in the original (unannotated) skeleton sequence. Leveraging the colorized skeleton point cloud, we design an auto-encoder framework that can learn spatial-temporal features from the artificial color labels of skeleton joints effectively. Specifically, we design a two-steam pretraining network that leverages fine-grained and coarse-grained colorization to learn multi-scale spatial-temporal features. In addition, we design a Masked Skeleton Cloud Repainting task that can pretrain the designed auto-encoder framework to learn informative representations. We evaluate our skeleton cloud colorization approach with linear classifiers trained under different configurations, including unsupervised, semi-supervised, fully-supervised, and transfer learning settings. Extensive experiments on NTU RGB+D, NTU RGB+D 120, PKU-MMD, NW-UCLA, and UWA3D datasets show that the proposed method outperforms existing unsupervised and semi-supervised 3D action recognition methods by large margins and achieves competitive performance in supervised 3D action recognition as well.
Rehearsal-Free Domain Continual Face Anti-Spoofing: Generalize More and Forget Less
Mar 16, 2023



Face Anti-Spoofing (FAS) is recently studied under the continual learning setting, where the FAS models are expected to evolve after encountering the data from new domains. However, existing methods need extra replay buffers to store previous data for rehearsal, which becomes infeasible when previous data is unavailable because of privacy issues. In this paper, we propose the first rehearsal-free method for Domain Continual Learning (DCL) of FAS, which deals with catastrophic forgetting and unseen domain generalization problems simultaneously. For better generalization to unseen domains, we design the Dynamic Central Difference Convolutional Adapter (DCDCA) to adapt Vision Transformer (ViT) models during the continual learning sessions. To alleviate the forgetting of previous domains without using previous data, we propose the Proxy Prototype Contrastive Regularization (PPCR) to constrain the continual learning with previous domain knowledge from the proxy prototypes. Simulate practical DCL scenarios, we devise two new protocols which evaluate both generalization and anti-forgetting performance. Extensive experimental results show that our proposed method can improve the generalization performance in unseen domains and alleviate the catastrophic forgetting of the previous knowledge. The codes and protocols will be released soon.
Rethinking Vision Transformer and Masked Autoencoder in Multimodal Face Anti-Spoofing
Feb 11, 2023Recently, vision transformer (ViT) based multimodal learning methods have been proposed to improve the robustness of face anti-spoofing (FAS) systems. However, there are still no works to explore the fundamental natures (\textit{e.g.}, modality-aware inputs, suitable multimodal pre-training, and efficient finetuning) in vanilla ViT for multimodal FAS. In this paper, we investigate three key factors (i.e., inputs, pre-training, and finetuning) in ViT for multimodal FAS with RGB, Infrared (IR), and Depth. First, in terms of the ViT inputs, we find that leveraging local feature descriptors benefits the ViT on IR modality but not RGB or Depth modalities. Second, in observation of the inefficiency on direct finetuning the whole or partial ViT, we design an adaptive multimodal adapter (AMA), which can efficiently aggregate local multimodal features while freezing majority of ViT parameters. Finally, in consideration of the task (FAS vs. generic object classification) and modality (multimodal vs. unimodal) gaps, ImageNet pre-trained models might be sub-optimal for the multimodal FAS task. To bridge these gaps, we propose the modality-asymmetric masked autoencoder (M$^{2}$A$^{2}$E) for multimodal FAS self-supervised pre-training without costly annotated labels. Compared with the previous modality-symmetric autoencoder, the proposed M$^{2}$A$^{2}$E is able to learn more intrinsic task-aware representation and compatible with modality-agnostic (e.g., unimodal, bimodal, and trimodal) downstream settings. Extensive experiments with both unimodal (RGB, Depth, IR) and multimodal (RGB+Depth, RGB+IR, Depth+IR, RGB+Depth+IR) settings conducted on multimodal FAS benchmarks demonstrate the superior performance of the proposed methods. We hope these findings and solutions can facilitate the future research for ViT-based multimodal FAS.
One-Class Knowledge Distillation for Face Presentation Attack Detection
May 08, 2022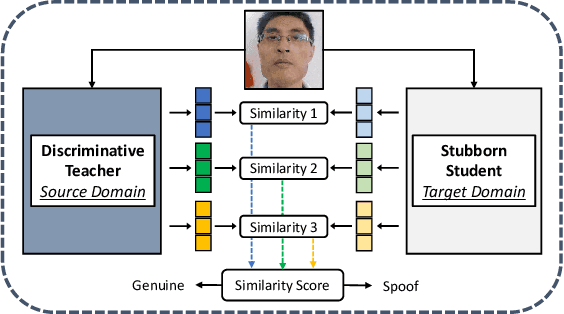
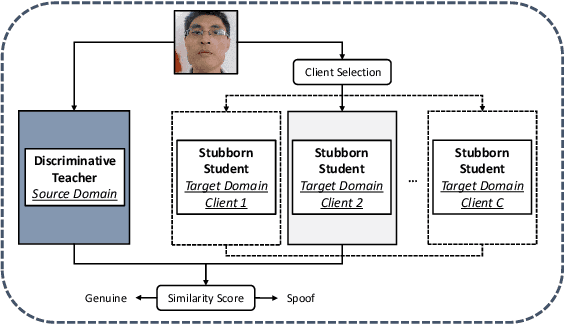
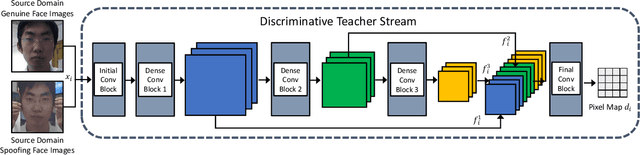
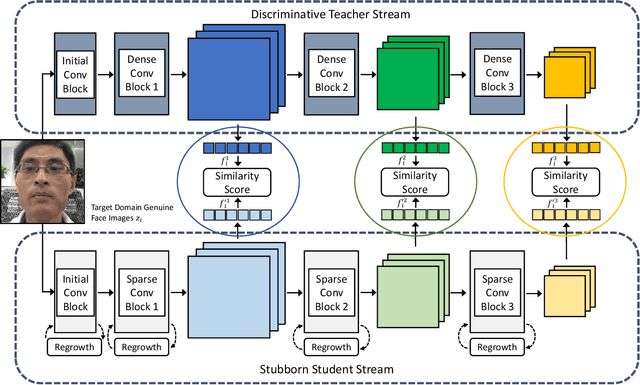
Face presentation attack detection (PAD) has been extensively studied by research communities to enhance the security of face recognition systems. Although existing methods have achieved good performance on testing data with similar distribution as the training data, their performance degrades severely in application scenarios with data of unseen distributions. In situations where the training and testing data are drawn from different domains, a typical approach is to apply domain adaptation techniques to improve face PAD performance with the help of target domain data. However, it has always been a non-trivial challenge to collect sufficient data samples in the target domain, especially for attack samples. This paper introduces a teacher-student framework to improve the cross-domain performance of face PAD with one-class domain adaptation. In addition to the source domain data, the framework utilizes only a few genuine face samples of the target domain. Under this framework, a teacher network is trained with source domain samples to provide discriminative feature representations for face PAD. Student networks are trained to mimic the teacher network and learn similar representations for genuine face samples of the target domain. In the test phase, the similarity score between the representations of the teacher and student networks is used to distinguish attacks from genuine ones. To evaluate the proposed framework under one-class domain adaptation settings, we devised two new protocols and conducted extensive experiments. The experimental results show that our method outperforms baselines under one-class domain adaptation settings and even state-of-the-art methods with unsupervised domain adaptation.
Self-Supervised Leaf Segmentation under Complex Lighting Conditions
Mar 29, 2022
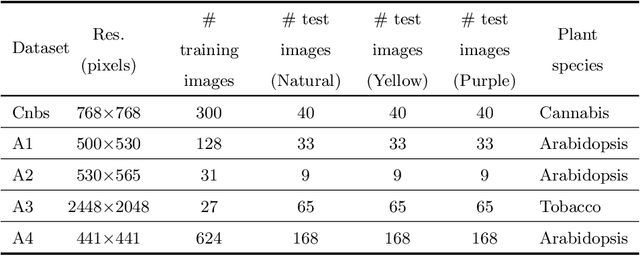
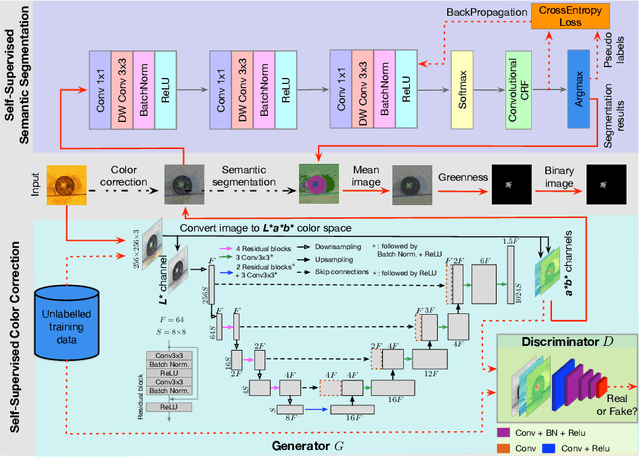

As an essential prerequisite task in image-based plant phenotyping, leaf segmentation has garnered increasing attention in recent years. While self-supervised learning is emerging as an effective alternative to various computer vision tasks, its adaptation for image-based plant phenotyping remains rather unexplored. In this work, we present a self-supervised leaf segmentation framework consisting of a self-supervised semantic segmentation model, a color-based leaf segmentation algorithm, and a self-supervised color correction model. The self-supervised semantic segmentation model groups the semantically similar pixels by iteratively referring to the self-contained information, allowing the pixels of the same semantic object to be jointly considered by the color-based leaf segmentation algorithm for identifying the leaf regions. Additionally, we propose to use a self-supervised color correction model for images taken under complex illumination conditions. Experimental results on datasets of different plant species demonstrate the potential of the proposed self-supervised framework in achieving effective and generalizable leaf segmentation.
Asymmetric Modality Translation For Face Presentation Attack Detection
Oct 20, 2021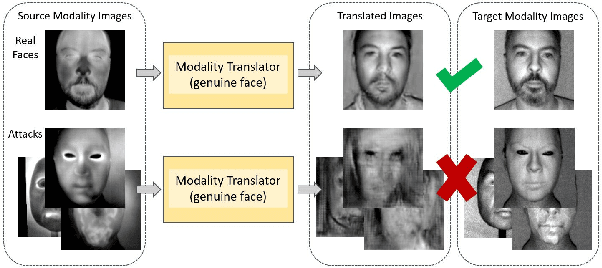
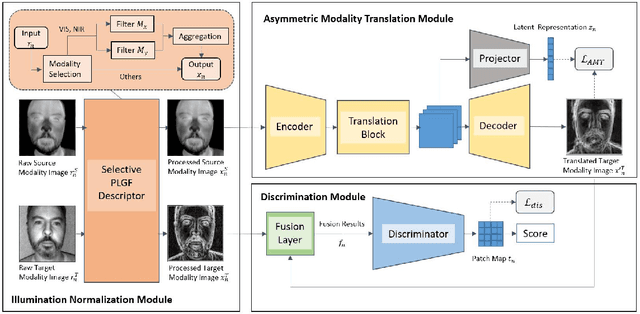


Face presentation attack detection (PAD) is an essential measure to protect face recognition systems from being spoofed by malicious users and has attracted great attention from both academia and industry. Although most of the existing methods can achieve desired performance to some extent, the generalization issue of face presentation attack detection under cross-domain settings (e.g., the setting of unseen attacks and varying illumination) remains to be solved. In this paper, we propose a novel framework based on asymmetric modality translation for face presentation attack detection in bi-modality scenarios. Under the framework, we establish connections between two modality images of genuine faces. Specifically, a novel modality fusion scheme is presented that the image of one modality is translated to the other one through an asymmetric modality translator, then fused with its corresponding paired image. The fusion result is fed as the input to a discriminator for inference. The training of the translator is supervised by an asymmetric modality translation loss. Besides, an illumination normalization module based on Pattern of Local Gravitational Force (PLGF) representation is used to reduce the impact of illumination variation. We conduct extensive experiments on three public datasets, which validate that our method is effective in detecting various types of attacks and achieves state-of-the-art performance under different evaluation protocols.