 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBQSched: A Non-intrusive Scheduler for Batch Concurrent Queries via Reinforcement Learning
Apr 27, 2025



Most large enterprises build predefined data pipelines and execute them periodically to process operational data using SQL queries for various tasks. A key issue in minimizing the overall makespan of these pipelines is the efficient scheduling of concurrent queries within the pipelines. Existing tools mainly rely on simple heuristic rules due to the difficulty of expressing the complex features and mutual influences of queries. The latest reinforcement learning (RL) based methods have the potential to capture these patterns from feedback, but it is non-trivial to apply them directly due to the large scheduling space, high sampling cost, and poor sample utilization. Motivated by these challenges, we propose BQSched, a non-intrusive Scheduler for Batch concurrent Queries via reinforcement learning. Specifically, BQSched designs an attention-based state representation to capture the complex query patterns, and proposes IQ-PPO, an auxiliary task-enhanced proximal policy optimization (PPO) algorithm, to fully exploit the rich signals of Individual Query completion in logs. Based on the RL framework above, BQSched further introduces three optimization strategies, including adaptive masking to prune the action space, scheduling gain-based query clustering to deal with large query sets, and an incremental simulator to reduce sampling cost. To our knowledge, BQSched is the first non-intrusive batch query scheduler via RL. Extensive experiments show that BQSched can significantly improve the efficiency and stability of batch query scheduling, while also achieving remarkable scalability and adaptability in both data and queries. For example, across all DBMSs and scales tested, BQSched reduces the overall makespan of batch queries on TPC-DS benchmark by an average of 34% and 13%, compared with the commonly used heuristic strategy and the adapted RL-based scheduler, respectively.
ODC-SA Net: Orthogonal Direction Enhancement and Scale Aware Network for Polyp Segmentation
May 10, 2024Accurate polyp segmentation is crucial for the early detection and prevention of colorectal cancer. However, the existing polyp detection methods sometimes ignore multi-directional features and drastic changes in scale. To address these challenges, we design an Orthogonal Direction Enhancement and Scale Aware Network (ODC-SA Net) for polyp segmentation. The Orthogonal Direction Convolutional (ODC) block can extract multi-directional features using transposed rectangular convolution kernels through forming an orthogonal feature vector basis, which solves the issue of random feature direction changes and reduces computational load. Additionally, the Multi-scale Fusion Attention (MSFA) mechanism is proposed to emphasize scale changes in both spatial and channel dimensions, enhancing the segmentation accuracy for polyps of varying sizes. Extraction with Re-attention Module (ERA) is used to re-combinane effective features, and Structures of Shallow Reverse Attention Mechanism (SRA) is used to enhance polyp edge with low level information. A large number of experiments conducted on public datasets have demonstrated that the performance of this model is superior to state-of-the-art methods.
Mask-TS Net: Mask Temperature Scaling Uncertainty Calibration for Polyp Segmentation
May 09, 2024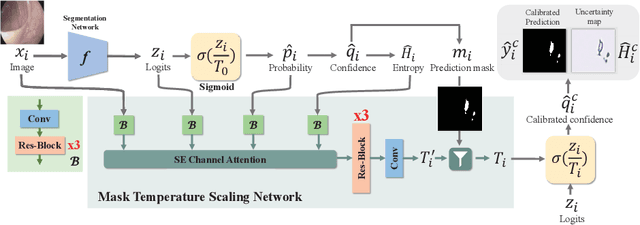
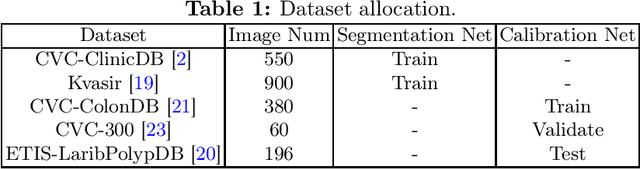
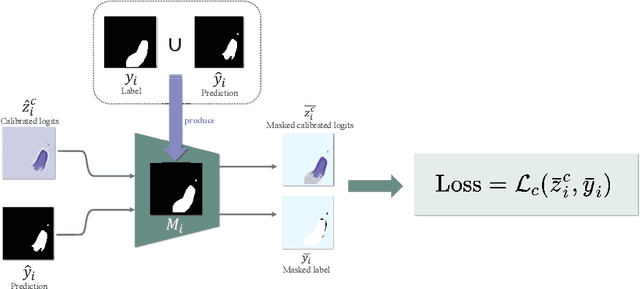
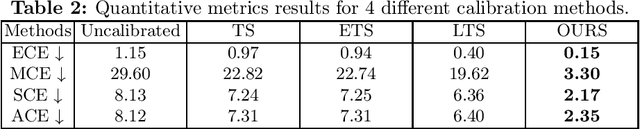
Lots of popular calibration methods in medical images focus on classification, but there are few comparable studies on semantic segmentation. In polyp segmentation of medical images, we find most diseased area occupies only a small portion of the entire image, resulting in previous models being not well-calibrated for lesion regions but well-calibrated for background, despite their seemingly better Expected Calibration Error (ECE) scores overall. Therefore, we proposed four-branches calibration network with Mask-Loss and Mask-TS strategies to more focus on the scaling of logits within potential lesion regions, which serves to mitigate the influence of background interference. In the experiments, we compare the existing calibration methods with the proposed Mask Temperature Scaling (Mask-TS). The results indicate that the proposed calibration network outperforms other methods both qualitatively and quantitatively.
HSViT: Horizontally Scalable Vision Transformer
Apr 08, 2024



While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
Deep Learning Techniques for Video Instance Segmentation: A Survey
Oct 19, 2023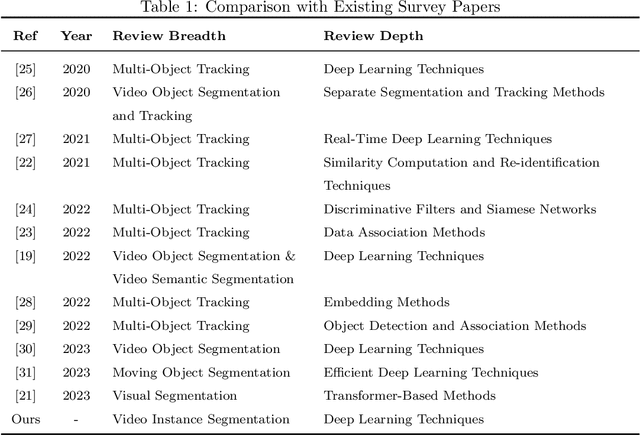


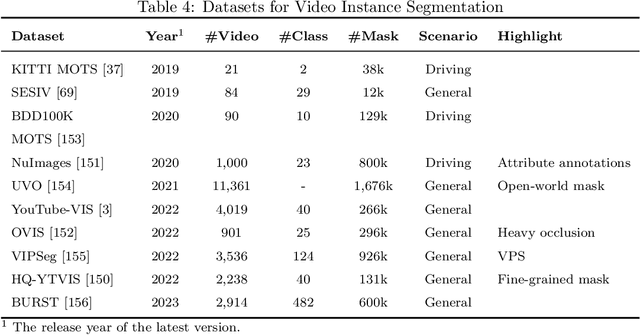
Video instance segmentation, also known as multi-object tracking and segmentation, is an emerging computer vision research area introduced in 2019, aiming at detecting, segmenting, and tracking instances in videos simultaneously. By tackling the video instance segmentation tasks through effective analysis and utilization of visual information in videos, a range of computer vision-enabled applications (e.g., human action recognition, medical image processing, autonomous vehicle navigation, surveillance, etc) can be implemented. As deep-learning techniques take a dominant role in various computer vision areas, a plethora of deep-learning-based video instance segmentation schemes have been proposed. This survey offers a multifaceted view of deep-learning schemes for video instance segmentation, covering various architectural paradigms, along with comparisons of functional performance, model complexity, and computational overheads. In addition to the common architectural designs, auxiliary techniques for improving the performance of deep-learning models for video instance segmentation are compiled and discussed. Finally, we discuss a range of major challenges and directions for further investigations to help advance this promising research field.
An Efficient and Reliable Asynchronous Federated Learning Scheme for Smart Public Transportation
Aug 30, 2022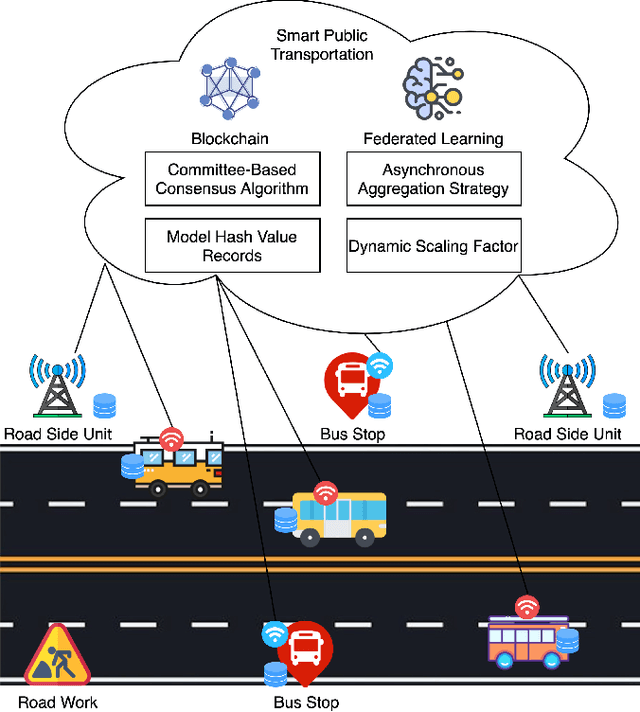
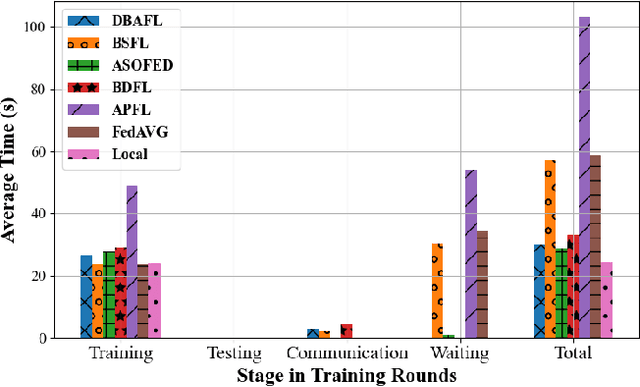
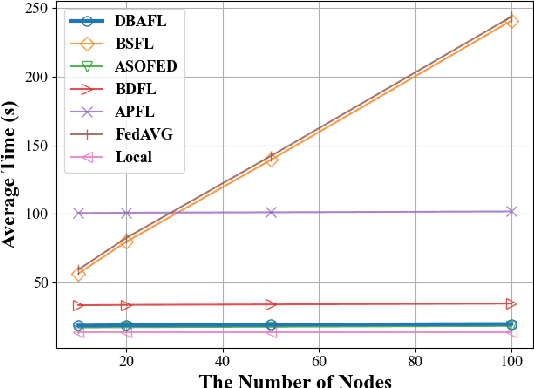
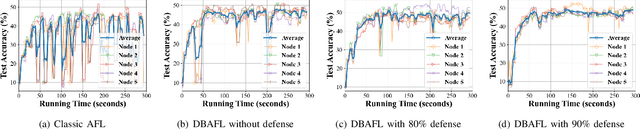
Since the traffic conditions change over time, machine learning models that predict traffic flows must be updated continuously and efficiently in smart public transportation. Federated learning (FL) is a distributed machine learning scheme that allows buses to receive model updates without waiting for model training on the cloud. However, FL is vulnerable to poisoning or DDoS attacks since buses travel in public. Some work introduces blockchain to improve reliability, but the additional latency from the consensus process reduces the efficiency of FL. Asynchronous Federated Learning (AFL) is a scheme that reduces the latency of aggregation to improve efficiency, but the learning performance is unstable due to unreasonably weighted local models. To address the above challenges, this paper offers a blockchain-based asynchronous federated learning scheme with a dynamic scaling factor (DBAFL). Specifically, the novel committee-based consensus algorithm for blockchain improves reliability at the lowest possible cost of time. Meanwhile, the devised dynamic scaling factor allows AFL to assign reasonable weights to stale local models. Extensive experiments conducted on heterogeneous devices validate outperformed learning performance, efficiency, and reliability of DBAFL.
SCEI: A Smart-Contract Driven Edge Intelligence Framework for IoT Systems
Mar 12, 2021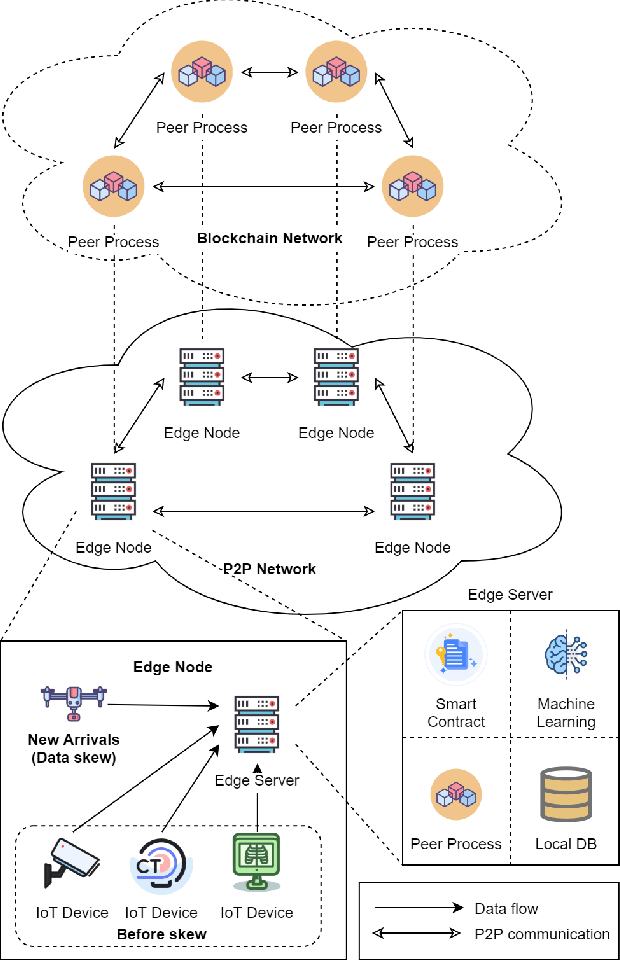
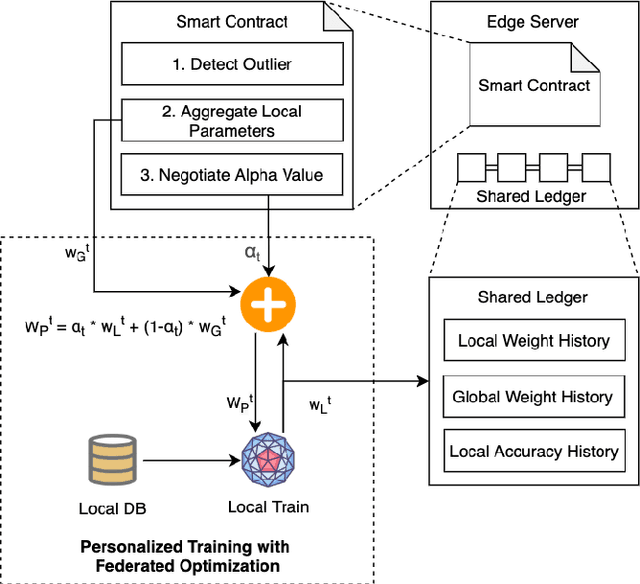
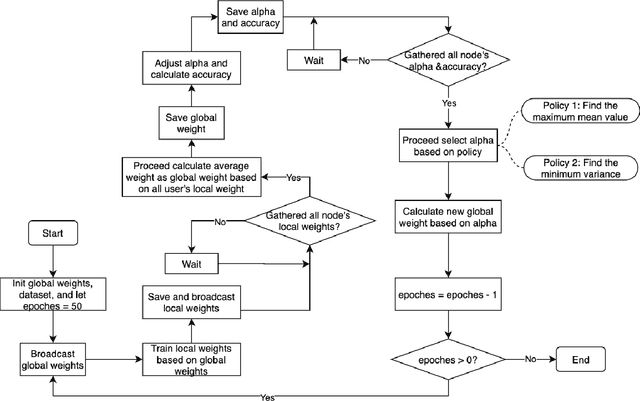
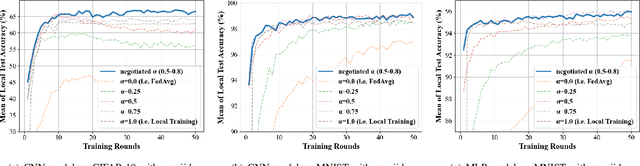
Federated learning (FL) utilizes edge computing devices to collaboratively train a shared model while each device can fully control its local data access. Generally, FL techniques focus on learning model on independent and identically distributed (iid) dataset and cannot achieve satisfiable performance on non-iid datasets (e.g. learning a multi-class classifier but each client only has a single class dataset). Some personalized approaches have been proposed to mitigate non-iid issues. However, such approaches cannot handle underlying data distribution shift, namely data distribution skew, which is quite common in real scenarios (e.g. recommendation systems learn user behaviors which change over time). In this work, we provide a solution to the challenge by leveraging smart-contract with federated learning to build optimized, personalized deep learning models. Specifically, our approach utilizes smart contract to reach consensus among distributed trainers on the optimal weights of personalized models. We conduct experiments across multiple models (CNN and MLP) and multiple datasets (MNIST and CIFAR-10). The experimental results demonstrate that our personalized learning models can achieve better accuracy and faster convergence compared to classic federated and personalized learning. Compared with the model given by baseline FedAvg algorithm, the average accuracy of our personalized learning models is improved by 2% to 20%, and the convergence rate is about 2$\times$ faster. Moreover, we also illustrate that our approach is secure against recent attack on distributed learning.
Learning convolutional neural network to maximize Pos@Top performance measure
Mar 01, 2017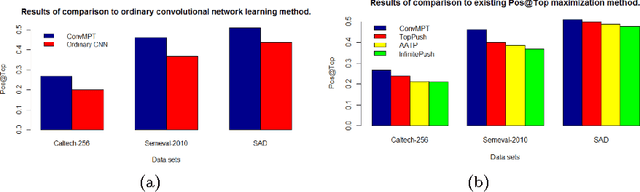
In the machine learning problems, the performance measure is used to evaluate the machine learning models. Recently, the number positive data points ranked at the top positions (Pos@Top) has been a popular performance measure in the machine learning community. In this paper, we propose to learn a convolutional neural network (CNN) model to maximize the Pos@Top performance measure. The CNN model is used to represent the multi-instance data point, and a classifier function is used to predict the label from the its CNN representation. We propose to minimize the loss function of Pos@Top over a training set to learn the filters of CNN and the classifier parameter. The classifier parameter vector is solved by the Lagrange multiplier method, and the filters are updated by the gradient descent method alternately in an iterative algorithm. Experiments over benchmark data sets show that the proposed method outperforms the state-of-the-art Pos@Top maximization methods.