 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Geometric Unlearning for LLMs with Minimal Data Disclosure
May 03, 2026As large language models (LLMs) are increasingly deployed in real-world systems, they must support post-hoc removal of specific content to meet privacy and governance requirements. This motivates selective unlearning, which suppresses information about a particular entity or topic while preserving the LLM's general utility. However, most existing LLM unlearning methods require access to the original training corpus and rely on output-level refusal tuning or broad gradient updates, creating a tension among unlearning strength, non-target preservation, and data availability. We propose Geometric Unlearning (GU), an approach that operates directly on the model's prompt-time planning states without access to the original training corpus. GU distills a compact, low-rank geometry of desired safe behavior from a small set of safe reference prompts, and uses lightweight anchor-in-context synthetic prompts to trigger localized, projection-based alignment of hidden planning representations to this safe geometry. A teacher-distillation regularizer on synthetic non-target anchors further reduces collateral drift. Across privacy-oriented unlearning benchmarks (ToFU and UnlearnPII), GU achieves strong target suppression with minimal impact on non-target performance, demonstrating that effective unlearning can be achieved with minimal synthetic data.
Memory Retrieval in Transformers: Insights from The Encoding Specificity Principle
Jan 28, 2026While explainable artificial intelligence (XAI) for large language models (LLMs) remains an evolving field with many unresolved questions, increasing regulatory pressures have spurred interest in its role in ensuring transparency, accountability, and privacy-preserving machine unlearning. Despite recent advances in XAI have provided some insights, the specific role of attention layers in transformer based LLMs remains underexplored. This study investigates the memory mechanisms instantiated by attention layers, drawing on prior research in psychology and computational psycholinguistics that links Transformer attention to cue based retrieval in human memory. In this view, queries encode the retrieval context, keys index candidate memory traces, attention weights quantify cue trace similarity, and values carry the encoded content, jointly enabling the construction of a context representation that precedes and facilitates memory retrieval. Guided by the Encoding Specificity Principle, we hypothesize that the cues used in the initial stage of retrieval are instantiated as keywords. We provide converging evidence for this keywords-as-cues hypothesis. In addition, we isolate neurons within attention layers whose activations selectively encode and facilitate the retrieval of context-defining keywords. Consequently, these keywords can be extracted from identified neurons and further contribute to downstream applications such as unlearning.
Federated Balanced Learning
Jan 20, 2026Federated learning is a paradigm of joint learning in which clients collaborate by sharing model parameters instead of data. However, in the non-iid setting, the global model experiences client drift, which can seriously affect the final performance of the model. Previous methods tend to correct the global model that has already deviated based on the loss function or gradient, overlooking the impact of the client samples. In this paper, we rethink the role of the client side and propose Federated Balanced Learning, i.e., FBL, to prevent this issue from the beginning through sample balance on the client side. Technically, FBL allows unbalanced data on the client side to achieve sample balance through knowledge filling and knowledge sampling using edge-side generation models, under the limitation of a fixed number of data samples on clients. Furthermore, we design a Knowledge Alignment Strategy to bridge the gap between synthetic and real data, and a Knowledge Drop Strategy to regularize our method. Meanwhile, we scale our method to real and complex scenarios, allowing different clients to adopt various methods, and extend our framework to further improve performance. Numerous experiments show that our method outperforms state-of-the-art baselines. The code is released upon acceptance.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
FedMLAC: Mutual Learning Driven Heterogeneous Federated Audio Classification
Jun 11, 2025
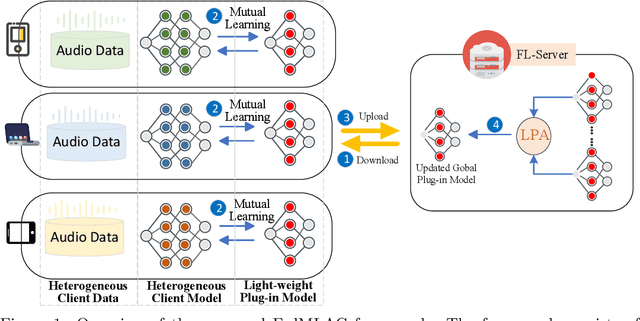

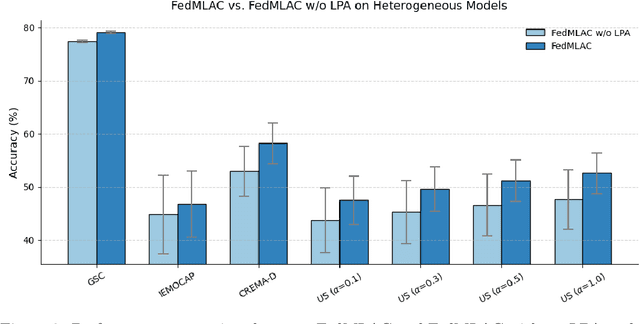
Federated Learning (FL) provides a privacy-preserving paradigm for training audio classification (AC) models across distributed clients without sharing raw data. However, Federated Audio Classification (FedAC) faces three critical challenges that substantially hinder performance: data heterogeneity, model heterogeneity, and data poisoning. While prior works have attempted to address these issues, they are typically treated independently, lacking a unified and robust solution suited to real-world federated audio scenarios. To bridge this gap, we propose FedMLAC, a unified mutual learning framework designed to simultaneously tackle these challenges in FedAC. Specifically, FedMLAC introduces a dual-model architecture on each client, comprising a personalized local AC model and a lightweight, globally shared Plug-in model. Through bidirectional knowledge distillation, the Plug-in model enables global knowledge transfer while adapting to client-specific data distributions, thus supporting both generalization and personalization. To further enhance robustness against corrupted audio data, we develop a Layer-wise Pruning Aggregation (LPA) strategy that filters unreliable Plug-in model updates based on parameter deviations during server-side aggregation. Extensive experiments on four diverse audio classification benchmarks, spanning both speech and non-speech tasks, demonstrate that FedMLAC consistently outperforms existing state-of-the-art methods in terms of classification accuracy and robustness to noisy data.
Federated Learning driven Large Language Models for Swarm Intelligence: A Survey
Jun 14, 2024
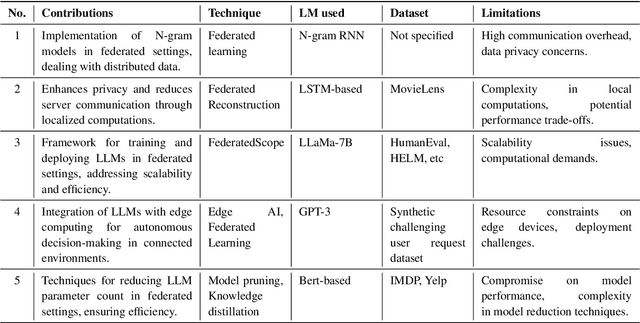
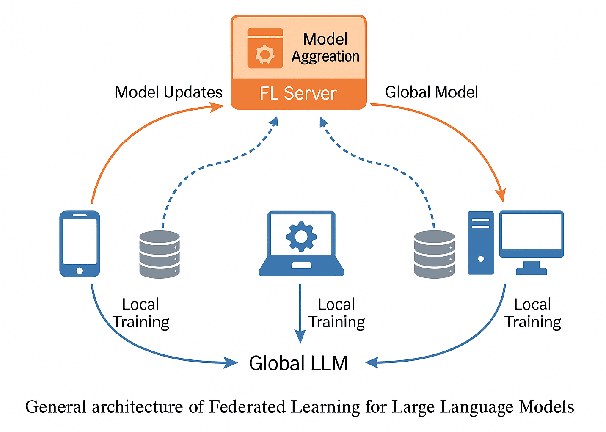
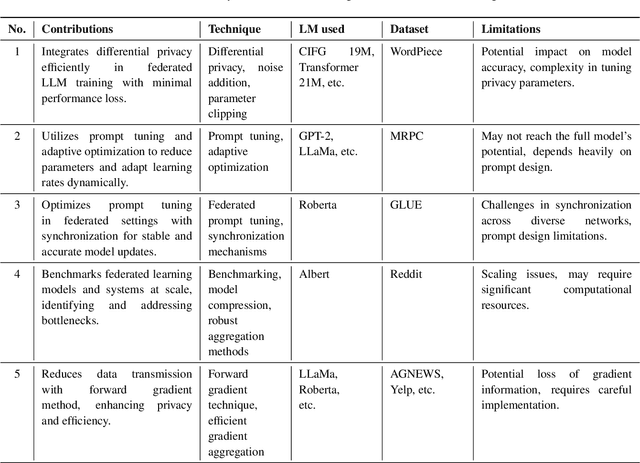
Federated learning (FL) offers a compelling framework for training large language models (LLMs) while addressing data privacy and decentralization challenges. This paper surveys recent advancements in the federated learning of large language models, with a particular focus on machine unlearning, a crucial aspect for complying with privacy regulations like the Right to be Forgotten. Machine unlearning in the context of federated LLMs involves systematically and securely removing individual data contributions from the learned model without retraining from scratch. We explore various strategies that enable effective unlearning, such as perturbation techniques, model decomposition, and incremental learning, highlighting their implications for maintaining model performance and data privacy. Furthermore, we examine case studies and experimental results from recent literature to assess the effectiveness and efficiency of these approaches in real-world scenarios. Our survey reveals a growing interest in developing more robust and scalable federated unlearning methods, suggesting a vital area for future research in the intersection of AI ethics and distributed machine learning technologies.
Privacy at a Price: Exploring its Dual Impact on AI Fairness
Apr 15, 2024



The worldwide adoption of machine learning (ML) and deep learning models, particularly in critical sectors, such as healthcare and finance, presents substantial challenges in maintaining individual privacy and fairness. These two elements are vital to a trustworthy environment for learning systems. While numerous studies have concentrated on protecting individual privacy through differential privacy (DP) mechanisms, emerging research indicates that differential privacy in machine learning models can unequally impact separate demographic subgroups regarding prediction accuracy. This leads to a fairness concern, and manifests as biased performance. Although the prevailing view is that enhancing privacy intensifies fairness disparities, a smaller, yet significant, subset of research suggests the opposite view. In this article, with extensive evaluation results, we demonstrate that the impact of differential privacy on fairness is not monotonous. Instead, we observe that the accuracy disparity initially grows as more DP noise (enhanced privacy) is added to the ML process, but subsequently diminishes at higher privacy levels with even more noise. Moreover, implementing gradient clipping in the differentially private stochastic gradient descent ML method can mitigate the negative impact of DP noise on fairness. This mitigation is achieved by moderating the disparity growth through a lower clipping threshold.
The Frontier of Data Erasure: Machine Unlearning for Large Language Models
Mar 23, 2024Large Language Models (LLMs) are foundational to AI advancements, facilitating applications like predictive text generation. Nonetheless, they pose risks by potentially memorizing and disseminating sensitive, biased, or copyrighted information from their vast datasets. Machine unlearning emerges as a cutting-edge solution to mitigate these concerns, offering techniques for LLMs to selectively discard certain data. This paper reviews the latest in machine unlearning for LLMs, introducing methods for the targeted forgetting of information to address privacy, ethical, and legal challenges without necessitating full model retraining. It divides existing research into unlearning from unstructured/textual data and structured/classification data, showcasing the effectiveness of these approaches in removing specific data while maintaining model efficacy. Highlighting the practicality of machine unlearning, this analysis also points out the hurdles in preserving model integrity, avoiding excessive or insufficient data removal, and ensuring consistent outputs, underlining the role of machine unlearning in advancing responsible, ethical AI.
Data and Model Poisoning Backdoor Attacks on Wireless Federated Learning, and the Defense Mechanisms: A Comprehensive Survey
Dec 14, 2023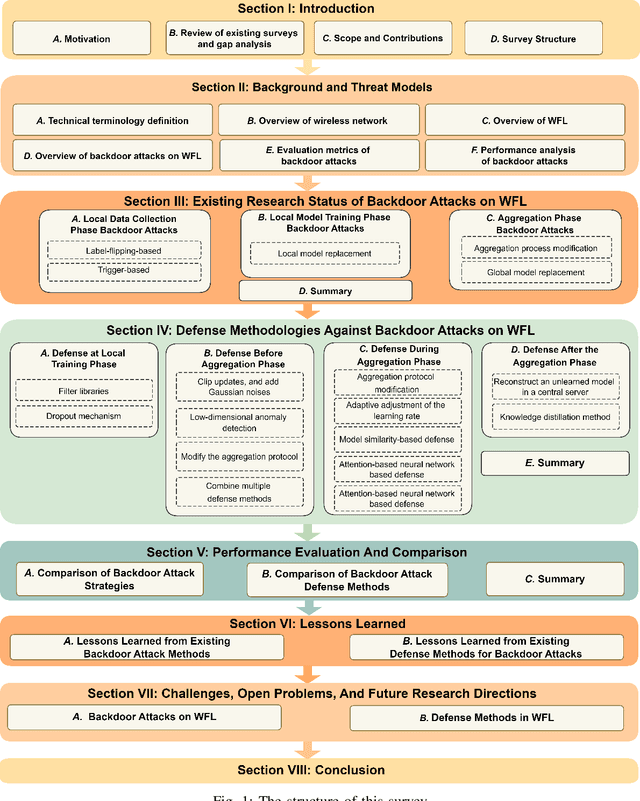
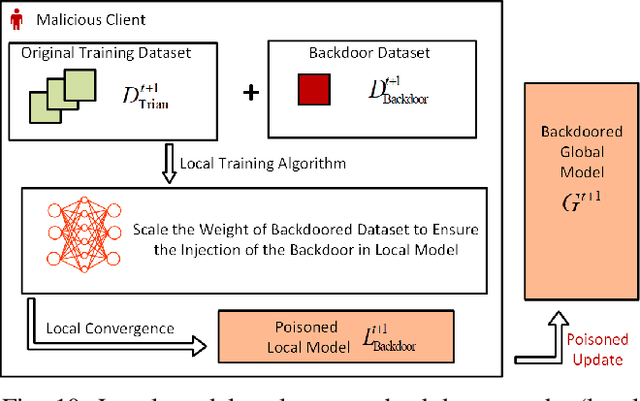
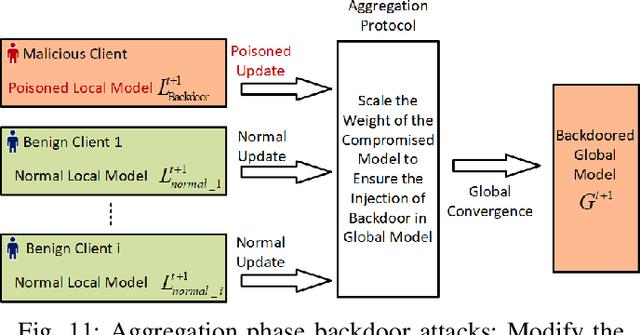
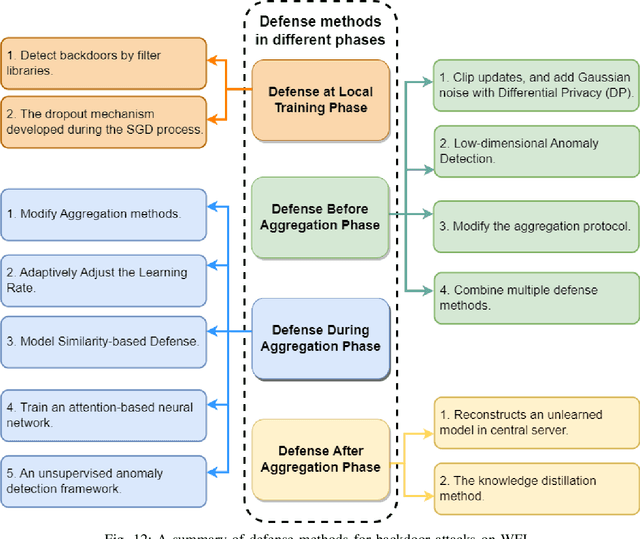
Due to the greatly improved capabilities of devices, massive data, and increasing concern about data privacy, Federated Learning (FL) has been increasingly considered for applications to wireless communication networks (WCNs). Wireless FL (WFL) is a distributed method of training a global deep learning model in which a large number of participants each train a local model on their training datasets and then upload the local model updates to a central server. However, in general, non-independent and identically distributed (non-IID) data of WCNs raises concerns about robustness, as a malicious participant could potentially inject a "backdoor" into the global model by uploading poisoned data or models over WCN. This could cause the model to misclassify malicious inputs as a specific target class while behaving normally with benign inputs. This survey provides a comprehensive review of the latest backdoor attacks and defense mechanisms. It classifies them according to their targets (data poisoning or model poisoning), the attack phase (local data collection, training, or aggregation), and defense stage (local training, before aggregation, during aggregation, or after aggregation). The strengths and limitations of existing attack strategies and defense mechanisms are analyzed in detail. Comparisons of existing attack methods and defense designs are carried out, pointing to noteworthy findings, open challenges, and potential future research directions related to security and privacy of WFL.
Towards Blockchain-Assisted Privacy-Aware Data Sharing For Edge Intelligence: A Smart Healthcare Perspective
Jun 29, 2023

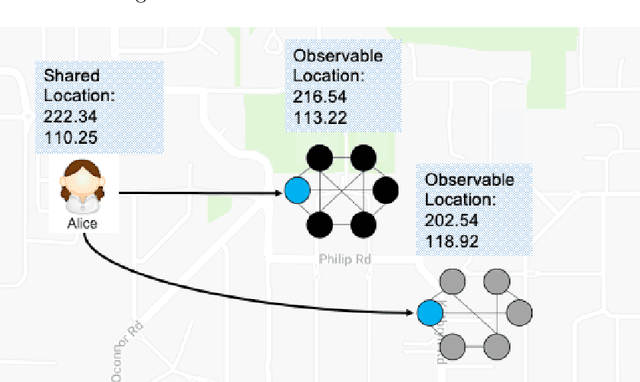
The popularization of intelligent healthcare devices and big data analytics significantly boosts the development of smart healthcare networks (SHNs). To enhance the precision of diagnosis, different participants in SHNs share health data that contains sensitive information. Therefore, the data exchange process raises privacy concerns, especially when the integration of health data from multiple sources (linkage attack) results in further leakage. Linkage attack is a type of dominant attack in the privacy domain, which can leverage various data sources for private data mining. Furthermore, adversaries launch poisoning attacks to falsify the health data, which leads to misdiagnosing or even physical damage. To protect private health data, we propose a personalized differential privacy model based on the trust levels among users. The trust is evaluated by a defined community density, while the corresponding privacy protection level is mapped to controllable randomized noise constrained by differential privacy. To avoid linkage attacks in personalized differential privacy, we designed a noise correlation decoupling mechanism using a Markov stochastic process. In addition, we build the community model on a blockchain, which can mitigate the risk of poisoning attacks during differentially private data transmission over SHNs. To testify the effectiveness and superiority of the proposed approach, we conduct extensive experiments on benchmark datasets.