 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Bias in Generative Data Augmentation for Medical AI: a Frequency Recalibration Method
Nov 15, 2025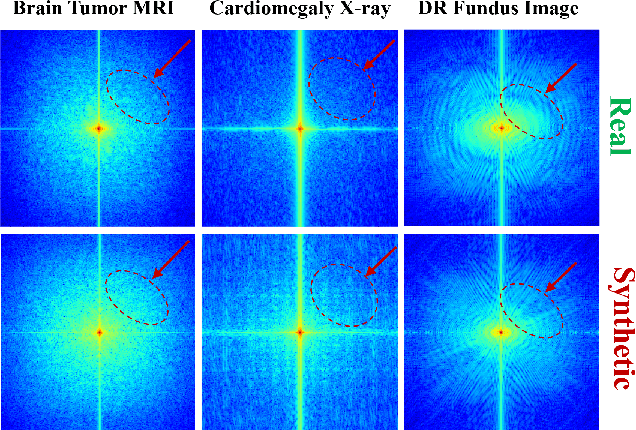

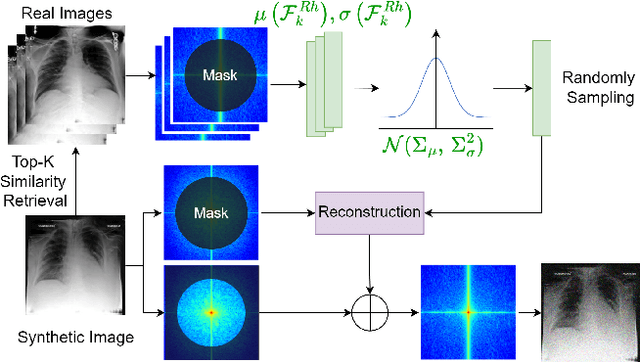
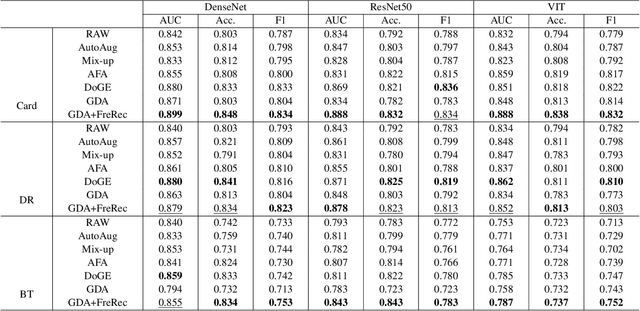
Developing Medical AI relies on large datasets and easily suffers from data scarcity. Generative data augmentation (GDA) using AI generative models offers a solution to synthesize realistic medical images. However, the bias in GDA is often underestimated in medical domains, with concerns about the risk of introducing detrimental features generated by AI and harming downstream tasks. This paper identifies the frequency misalignment between real and synthesized images as one of the key factors underlying unreliable GDA and proposes the Frequency Recalibration (FreRec) method to reduce the frequency distributional discrepancy and thus improve GDA. FreRec involves (1) Statistical High-frequency Replacement (SHR) to roughly align high-frequency components and (2) Reconstructive High-frequency Mapping (RHM) to enhance image quality and reconstruct high-frequency details. Extensive experiments were conducted in various medical datasets, including brain MRIs, chest X-rays, and fundus images. The results show that FreRec significantly improves downstream medical image classification performance compared to uncalibrated AI-synthesized samples. FreRec is a standalone post-processing step that is compatible with any generative model and can integrate seamlessly with common medical GDA pipelines.
Physics-Informed Deformable Gaussian Splatting: Towards Unified Constitutive Laws for Time-Evolving Material Field
Nov 11, 2025Recently, 3D Gaussian Splatting (3DGS), an explicit scene representation technique, has shown significant promise for dynamic novel-view synthesis from monocular video input. However, purely data-driven 3DGS often struggles to capture the diverse physics-driven motion patterns in dynamic scenes. To fill this gap, we propose Physics-Informed Deformable Gaussian Splatting (PIDG), which treats each Gaussian particle as a Lagrangian material point with time-varying constitutive parameters and is supervised by 2D optical flow via motion projection. Specifically, we adopt static-dynamic decoupled 4D decomposed hash encoding to reconstruct geometry and motion efficiently. Subsequently, we impose the Cauchy momentum residual as a physics constraint, enabling independent prediction of each particle's velocity and constitutive stress via a time-evolving material field. Finally, we further supervise data fitting by matching Lagrangian particle flow to camera-compensated optical flow, which accelerates convergence and improves generalization. Experiments on a custom physics-driven dataset as well as on standard synthetic and real-world datasets demonstrate significant gains in physical consistency and monocular dynamic reconstruction quality.
Causal Fingerprints of AI Generative Models
Sep 18, 2025AI generative models leave implicit traces in their generated images, which are commonly referred to as model fingerprints and are exploited for source attribution. Prior methods rely on model-specific cues or synthesis artifacts, yielding limited fingerprints that may generalize poorly across different generative models. We argue that a complete model fingerprint should reflect the causality between image provenance and model traces, a direction largely unexplored. To this end, we conceptualize the \emph{causal fingerprint} of generative models, and propose a causality-decoupling framework that disentangles it from image-specific content and style in a semantic-invariant latent space derived from pre-trained diffusion reconstruction residual. We further enhance fingerprint granularity with diverse feature representations. We validate causality by assessing attribution performance across representative GANs and diffusion models and by achieving source anonymization using counterfactual examples generated from causal fingerprints. Experiments show our approach outperforms existing methods in model attribution, indicating strong potential for forgery detection, model copyright tracing, and identity protection.
Physics-informed Temporal Alignment for Auto-regressive PDE Foundation Models
May 16, 2025


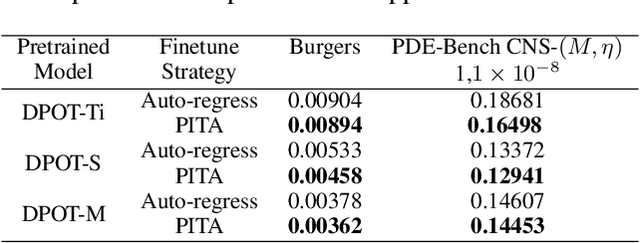
Auto-regressive partial differential equation (PDE) foundation models have shown great potential in handling time-dependent data. However, these models suffer from the shortcut problem deeply rooted in auto-regressive prediction, causing error accumulation. The challenge becomes particularly evident for out-of-distribution data, as the pretraining performance may approach random model initialization for downstream tasks with long-term dynamics. To deal with this problem, we propose physics-informed temporal alignment (PITA), a self-supervised learning framework inspired by inverse problem solving. Specifically, PITA aligns the physical dynamics discovered at different time steps on each given PDE trajectory by integrating physics-informed constraints into the self-supervision signal. The alignment is derived from observation data without relying on known physics priors, indicating strong generalization ability to the out-of-distribution data. Extensive experiments show that PITA significantly enhances the accuracy and robustness of existing foundation models on diverse time-dependent PDE data. The code is available at https://github.com/SCAILab-USTC/PITA.
STSA: Spatial-Temporal Semantic Alignment for Visual Dubbing
Mar 29, 2025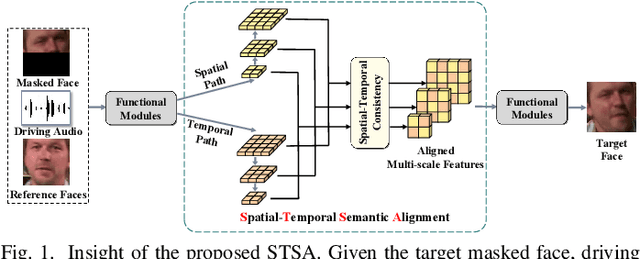
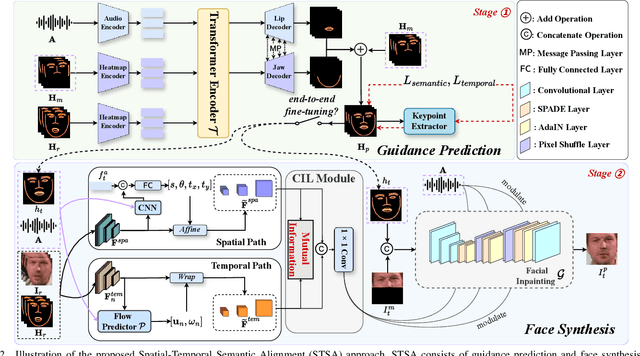
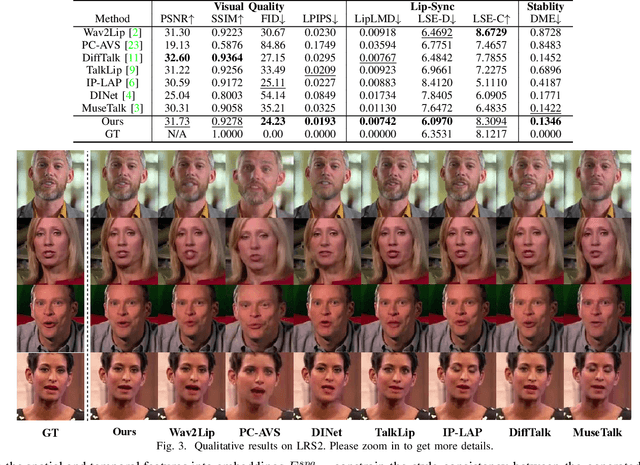
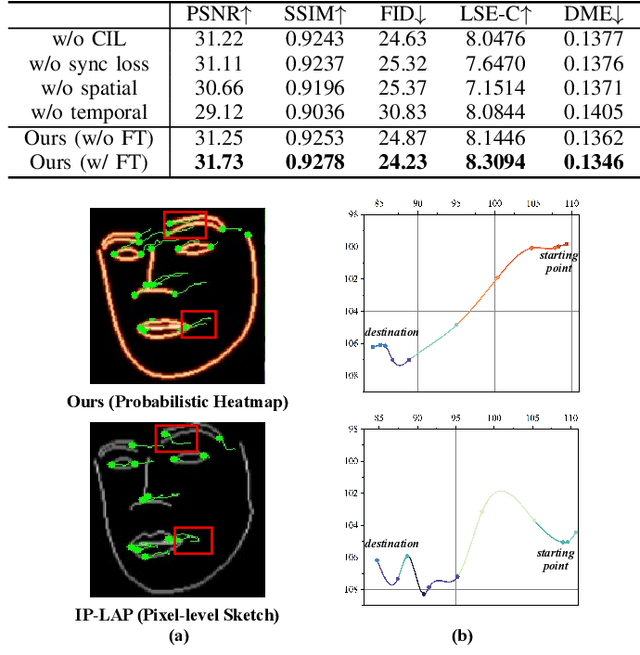
Existing audio-driven visual dubbing methods have achieved great success. Despite this, we observe that the semantic ambiguity between spatial and temporal domains significantly degrades the synthesis stability for the dynamic faces. We argue that aligning the semantic features from spatial and temporal domains is a promising approach to stabilizing facial motion. To achieve this, we propose a Spatial-Temporal Semantic Alignment (STSA) method, which introduces a dual-path alignment mechanism and a differentiable semantic representation. The former leverages a Consistent Information Learning (CIL) module to maximize the mutual information at multiple scales, thereby reducing the manifold differences between spatial and temporal domains. The latter utilizes probabilistic heatmap as ambiguity-tolerant guidance to avoid the abnormal dynamics of the synthesized faces caused by slight semantic jittering. Extensive experimental results demonstrate the superiority of the proposed STSA, especially in terms of image quality and synthesis stability. Pre-trained weights and inference code are available at https://github.com/SCAILab-USTC/STSA.
Reinforcement Unlearning
Dec 26, 2023



Machine unlearning refers to the process of mitigating the influence of specific training data on machine learning models based on removal requests from data owners. However, one important area that has been largely overlooked in the research of unlearning is reinforcement learning. Reinforcement learning focuses on training an agent to make optimal decisions within an environment to maximize its cumulative rewards. During the training, the agent tends to memorize the features of the environment, which raises a significant concern about privacy. As per data protection regulations, the owner of the environment holds the right to revoke access to the agent's training data, thus necessitating the development of a novel and pressing research field, known as \emph{reinforcement unlearning}. Reinforcement unlearning focuses on revoking entire environments rather than individual data samples. This unique characteristic presents three distinct challenges: 1) how to propose unlearning schemes for environments; 2) how to avoid degrading the agent's performance in remaining environments; and 3) how to evaluate the effectiveness of unlearning. To tackle these challenges, we propose two reinforcement unlearning methods. The first method is based on decremental reinforcement learning, which aims to erase the agent's previously acquired knowledge gradually. The second method leverages environment poisoning attacks, which encourage the agent to learn new, albeit incorrect, knowledge to remove the unlearning environment. Particularly, to tackle the third challenge, we introduce the concept of ``environment inference attack'' to evaluate the unlearning outcomes. The source code is available at \url{https://anonymous.4open.science/r/Reinforcement-Unlearning-D347}.
Reasoning Structural Relation for Occlusion-Robust Facial Landmark Localization
Dec 19, 2021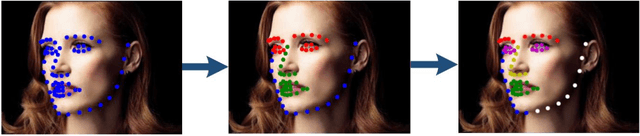
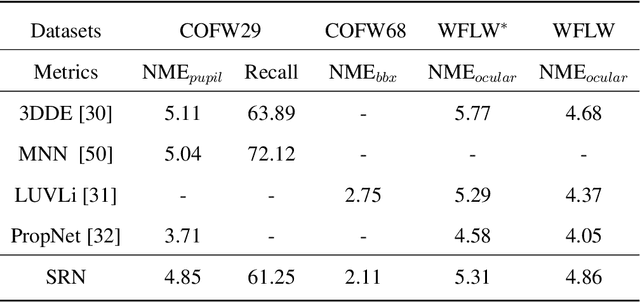
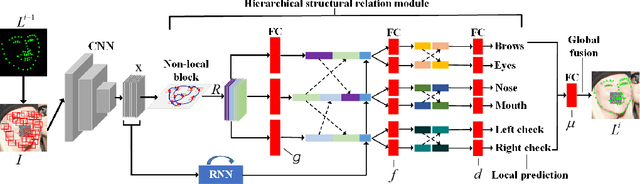
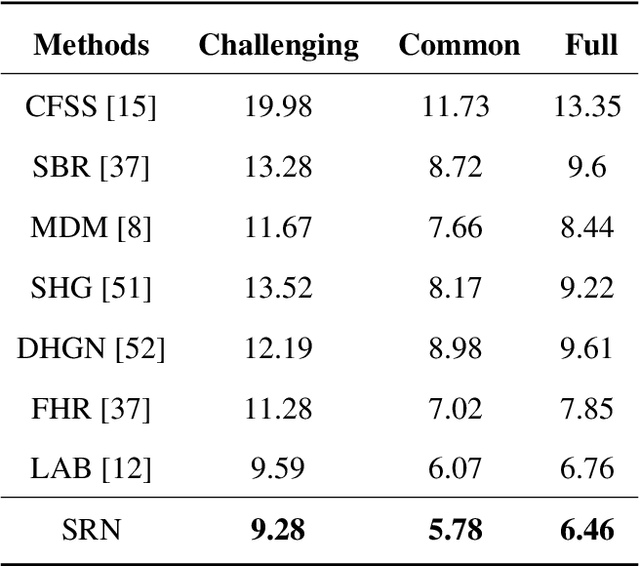
In facial landmark localization tasks, various occlusions heavily degrade the localization accuracy due to the partial observability of facial features. This paper proposes a structural relation network (SRN) for occlusion-robust landmark localization. Unlike most existing methods that simply exploit the shape constraint, the proposed SRN aims to capture the structural relations among different facial components. These relations can be considered a more powerful shape constraint against occlusion. To achieve this, a hierarchical structural relation module (HSRM) is designed to hierarchically reason the structural relations that represent both long- and short-distance spatial dependencies. Compared with existing network architectures, HSRM can efficiently model the spatial relations by leveraging its geometry-aware network architecture, which reduces the semantic ambiguity caused by occlusion. Moreover, the SRN augments the training data by synthesizing occluded faces. To further extend our SRN for occluded video data, we formulate the occluded face synthesis as a Markov decision process (MDP). Specifically, it plans the movement of the dynamic occlusion based on an accumulated reward associated with the performance degradation of the pre-trained SRN. This procedure augments hard samples for robust facial landmark tracking. Extensive experimental results indicate that the proposed method achieves outstanding performance on occluded and masked faces. Code is available at https://github.com/zhuccly/SRN.
Unsupervised Learning of Multi-level Structures for Anomaly Detection
Apr 25, 2021
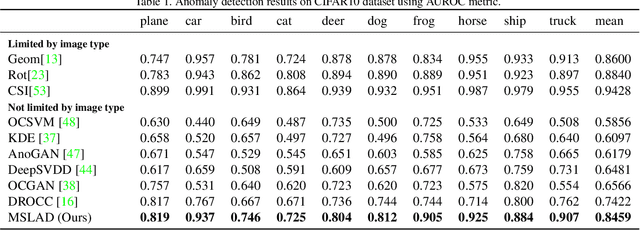
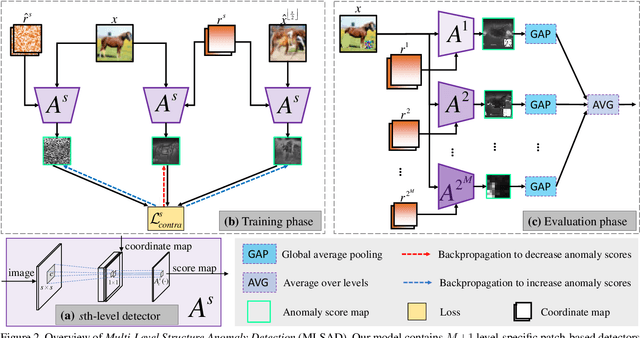
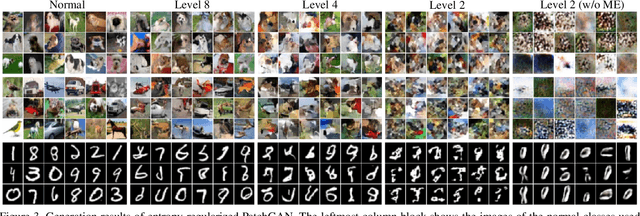
The main difficulty in high-dimensional anomaly detection tasks is the lack of anomalous data for training. And simply collecting anomalous data from the real world, common distributions, or the boundary of normal data manifold may face the problem of missing anomaly modes. This paper first introduces a novel method to generate anomalous data by breaking up global structures while preserving local structures of normal data at multiple levels. It can efficiently expose local abnormal structures of various levels. To fully exploit the exposed multi-level abnormal structures, we propose to train multiple level-specific patch-based detectors with contrastive losses. Each detector learns to detect local abnormal structures of corresponding level at all locations and outputs patchwise anomaly scores. By aggregating the outputs of all level-specific detectors, we obtain a model that can detect all potential anomalies. The effectiveness is evaluated on MNIST, CIFAR10, and ImageNet10 dataset, where the results surpass the accuracy of state-of-the-art methods. Qualitative experiments demonstrate our model is robust that it unbiasedly detects all anomaly modes.
Towards Omni-Supervised Face Alignment for Large Scale Unlabeled Videos
Dec 16, 2019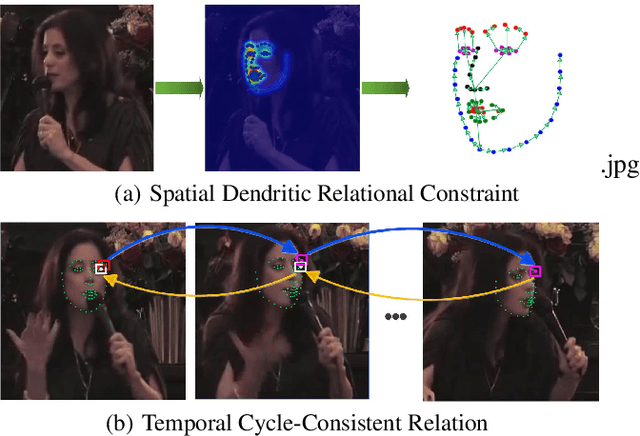
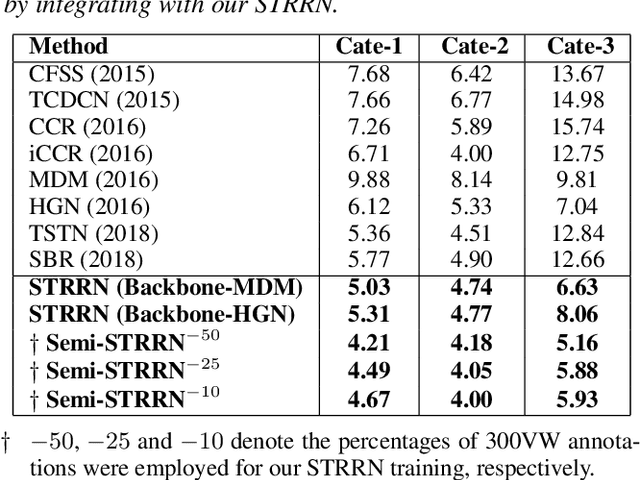
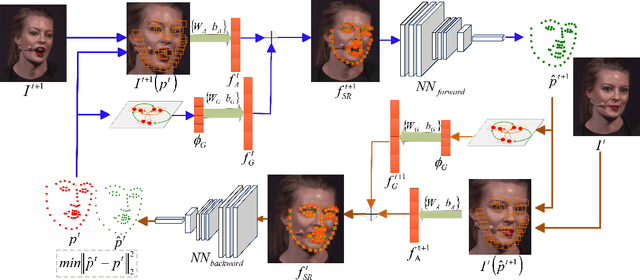
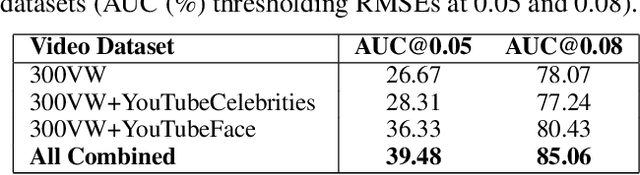
In this paper, we propose a spatial-temporal relational reasoning networks (STRRN) approach to investigate the problem of omni-supervised face alignment in videos. Unlike existing fully supervised methods which rely on numerous annotations by hand, our learner exploits large scale unlabeled videos plus available labeled data to generate auxiliary plausible training annotations. Motivated by the fact that neighbouring facial landmarks are usually correlated and coherent across consecutive frames, our approach automatically reasons about discriminative spatial-temporal relationships among landmarks for stable face tracking. Specifically, we carefully develop an interpretable and efficient network module, which disentangles facial geometry relationship for every static frame and simultaneously enforces the bi-directional cycle-consistency across adjacent frames, thus allowing the modeling of intrinsic spatial-temporal relations from raw face sequences. Extensive experimental results demonstrate that our approach surpasses the performance of most fully supervised state-of-the-arts.