 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForgetting Similar Samples: Can Machine Unlearning Do it Better?
Jan 11, 2026Machine unlearning, a process enabling pre-trained models to remove the influence of specific training samples, has attracted significant attention in recent years. Although extensive research has focused on developing efficient machine unlearning strategies, we argue that these methods mainly aim at removing samples rather than removing samples' influence on the model, thus overlooking the fundamental definition of machine unlearning. In this paper, we first conduct a comprehensive study to evaluate the effectiveness of existing unlearning schemes when the training dataset includes many samples similar to those targeted for unlearning. Specifically, we evaluate: Do existing unlearning methods truly adhere to the original definition of machine unlearning and effectively eliminate all influence of target samples when similar samples are present in the training dataset? Our extensive experiments, conducted on four carefully constructed datasets with thorough analysis, reveal a notable gap between the expected and actual performance of most existing unlearning methods for image and language models, even for the retraining-from-scratch baseline. Additionally, we also explore potential solutions to enhance current unlearning approaches.
Dual-View Inference Attack: Machine Unlearning Amplifies Privacy Exposure
Dec 18, 2025Machine unlearning is a newly popularized technique for removing specific training data from a trained model, enabling it to comply with data deletion requests. While it protects the rights of users requesting unlearning, it also introduces new privacy risks. Prior works have primarily focused on the privacy of data that has been unlearned, while the risks to retained data remain largely unexplored. To address this gap, we focus on the privacy risks of retained data and, for the first time, reveal the vulnerabilities introduced by machine unlearning under the dual-view setting, where an adversary can query both the original and the unlearned models. From an information-theoretic perspective, we introduce the concept of {privacy knowledge gain} and demonstrate that the dual-view setting allows adversaries to obtain more information than querying either model alone, thereby amplifying privacy leakage. To effectively demonstrate this threat, we propose DVIA, a Dual-View Inference Attack, which extracts membership information on retained data using black-box queries to both models. DVIA eliminates the need to train an attack model and employs a lightweight likelihood ratio inference module for efficient inference. Experiments across different datasets and model architectures validate the effectiveness of DVIA and highlight the privacy risks inherent in the dual-view setting.
Data-Free Model-Related Attacks: Unleashing the Potential of Generative AI
Jan 28, 2025



Generative AI technology has become increasingly integrated into our daily lives, offering powerful capabilities to enhance productivity. However, these same capabilities can be exploited by adversaries for malicious purposes. While existing research on adversarial applications of generative AI predominantly focuses on cyberattacks, less attention has been given to attacks targeting deep learning models. In this paper, we introduce the use of generative AI for facilitating model-related attacks, including model extraction, membership inference, and model inversion. Our study reveals that adversaries can launch a variety of model-related attacks against both image and text models in a data-free and black-box manner, achieving comparable performance to baseline methods that have access to the target models' training data and parameters in a white-box manner. This research serves as an important early warning to the community about the potential risks associated with generative AI-powered attacks on deep learning models.
Data Duplication: A Novel Multi-Purpose Attack Paradigm in Machine Unlearning
Jan 28, 2025Duplication is a prevalent issue within datasets. Existing research has demonstrated that the presence of duplicated data in training datasets can significantly influence both model performance and data privacy. However, the impact of data duplication on the unlearning process remains largely unexplored. This paper addresses this gap by pioneering a comprehensive investigation into the role of data duplication, not only in standard machine unlearning but also in federated and reinforcement unlearning paradigms. Specifically, we propose an adversary who duplicates a subset of the target model's training set and incorporates it into the training set. After training, the adversary requests the model owner to unlearn this duplicated subset, and analyzes the impact on the unlearned model. For example, the adversary can challenge the model owner by revealing that, despite efforts to unlearn it, the influence of the duplicated subset remains in the model. Moreover, to circumvent detection by de-duplication techniques, we propose three novel near-duplication methods for the adversary, each tailored to a specific unlearning paradigm. We then examine their impacts on the unlearning process when de-duplication techniques are applied. Our findings reveal several crucial insights: 1) the gold standard unlearning method, retraining from scratch, fails to effectively conduct unlearning under certain conditions; 2) unlearning duplicated data can lead to significant model degradation in specific scenarios; and 3) meticulously crafted duplicates can evade detection by de-duplication methods.
When Machine Unlearning Meets Retrieval-Augmented Generation (RAG): Keep Secret or Forget Knowledge?
Oct 20, 2024



The deployment of large language models (LLMs) like ChatGPT and Gemini has shown their powerful natural language generation capabilities. However, these models can inadvertently learn and retain sensitive information and harmful content during training, raising significant ethical and legal concerns. To address these issues, machine unlearning has been introduced as a potential solution. While existing unlearning methods take into account the specific characteristics of LLMs, they often suffer from high computational demands, limited applicability, or the risk of catastrophic forgetting. To address these limitations, we propose a lightweight unlearning framework based on Retrieval-Augmented Generation (RAG) technology. By modifying the external knowledge base of RAG, we simulate the effects of forgetting without directly interacting with the unlearned LLM. We approach the construction of unlearned knowledge as a constrained optimization problem, deriving two key components that underpin the effectiveness of RAG-based unlearning. This RAG-based approach is particularly effective for closed-source LLMs, where existing unlearning methods often fail. We evaluate our framework through extensive experiments on both open-source and closed-source models, including ChatGPT, Gemini, Llama-2-7b-chat-hf, and PaLM 2. The results demonstrate that our approach meets five key unlearning criteria: effectiveness, universality, harmlessness, simplicity, and robustness. Meanwhile, this approach can extend to multimodal large language models and LLM-based agents.
Reinforcement Unlearning
Dec 26, 2023



Machine unlearning refers to the process of mitigating the influence of specific training data on machine learning models based on removal requests from data owners. However, one important area that has been largely overlooked in the research of unlearning is reinforcement learning. Reinforcement learning focuses on training an agent to make optimal decisions within an environment to maximize its cumulative rewards. During the training, the agent tends to memorize the features of the environment, which raises a significant concern about privacy. As per data protection regulations, the owner of the environment holds the right to revoke access to the agent's training data, thus necessitating the development of a novel and pressing research field, known as \emph{reinforcement unlearning}. Reinforcement unlearning focuses on revoking entire environments rather than individual data samples. This unique characteristic presents three distinct challenges: 1) how to propose unlearning schemes for environments; 2) how to avoid degrading the agent's performance in remaining environments; and 3) how to evaluate the effectiveness of unlearning. To tackle these challenges, we propose two reinforcement unlearning methods. The first method is based on decremental reinforcement learning, which aims to erase the agent's previously acquired knowledge gradually. The second method leverages environment poisoning attacks, which encourage the agent to learn new, albeit incorrect, knowledge to remove the unlearning environment. Particularly, to tackle the third challenge, we introduce the concept of ``environment inference attack'' to evaluate the unlearning outcomes. The source code is available at \url{https://anonymous.4open.science/r/Reinforcement-Unlearning-D347}.
Boosting Model Inversion Attacks with Adversarial Examples
Jun 24, 2023



Model inversion attacks involve reconstructing the training data of a target model, which raises serious privacy concerns for machine learning models. However, these attacks, especially learning-based methods, are likely to suffer from low attack accuracy, i.e., low classification accuracy of these reconstructed data by machine learning classifiers. Recent studies showed an alternative strategy of model inversion attacks, GAN-based optimization, can improve the attack accuracy effectively. However, these series of GAN-based attacks reconstruct only class-representative training data for a class, whereas learning-based attacks can reconstruct diverse data for different training data in each class. Hence, in this paper, we propose a new training paradigm for a learning-based model inversion attack that can achieve higher attack accuracy in a black-box setting. First, we regularize the training process of the attack model with an added semantic loss function and, second, we inject adversarial examples into the training data to increase the diversity of the class-related parts (i.e., the essential features for classification tasks) in training data. This scheme guides the attack model to pay more attention to the class-related parts of the original data during the data reconstruction process. The experimental results show that our method greatly boosts the performance of existing learning-based model inversion attacks. Even when no extra queries to the target model are allowed, the approach can still improve the attack accuracy of reconstructed data. This new attack shows that the severity of the threat from learning-based model inversion adversaries is underestimated and more robust defenses are required.
New Challenges in Reinforcement Learning: A Survey of Security and Privacy
Dec 31, 2022Reinforcement learning (RL) is one of the most important branches of AI. Due to its capacity for self-adaption and decision-making in dynamic environments, reinforcement learning has been widely applied in multiple areas, such as healthcare, data markets, autonomous driving, and robotics. However, some of these applications and systems have been shown to be vulnerable to security or privacy attacks, resulting in unreliable or unstable services. A large number of studies have focused on these security and privacy problems in reinforcement learning. However, few surveys have provided a systematic review and comparison of existing problems and state-of-the-art solutions to keep up with the pace of emerging threats. Accordingly, we herein present such a comprehensive review to explain and summarize the challenges associated with security and privacy in reinforcement learning from a new perspective, namely that of the Markov Decision Process (MDP). In this survey, we first introduce the key concepts related to this area. Next, we cover the security and privacy issues linked to the state, action, environment, and reward function of the MDP process, respectively. We further highlight the special characteristics of security and privacy methodologies related to reinforcement learning. Finally, we discuss the possible future research directions within this area.
One Parameter Defense -- Defending against Data Inference Attacks via Differential Privacy
Mar 13, 2022Machine learning models are vulnerable to data inference attacks, such as membership inference and model inversion attacks. In these types of breaches, an adversary attempts to infer a data record's membership in a dataset or even reconstruct this data record using a confidence score vector predicted by the target model. However, most existing defense methods only protect against membership inference attacks. Methods that can combat both types of attacks require a new model to be trained, which may not be time-efficient. In this paper, we propose a differentially private defense method that handles both types of attacks in a time-efficient manner by tuning only one parameter, the privacy budget. The central idea is to modify and normalize the confidence score vectors with a differential privacy mechanism which preserves privacy and obscures membership and reconstructed data. Moreover, this method can guarantee the order of scores in the vector to avoid any loss in classification accuracy. The experimental results show the method to be an effective and timely defense against both membership inference and model inversion attacks with no reduction in accuracy.
Model Inversion Attack against Transfer Learning: Inverting a Model without Accessing It
Mar 13, 2022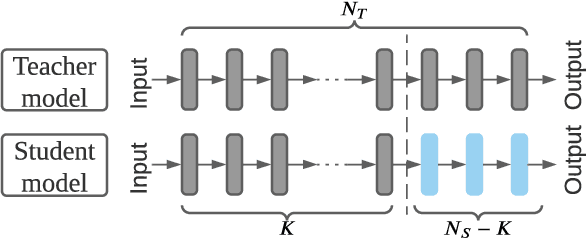

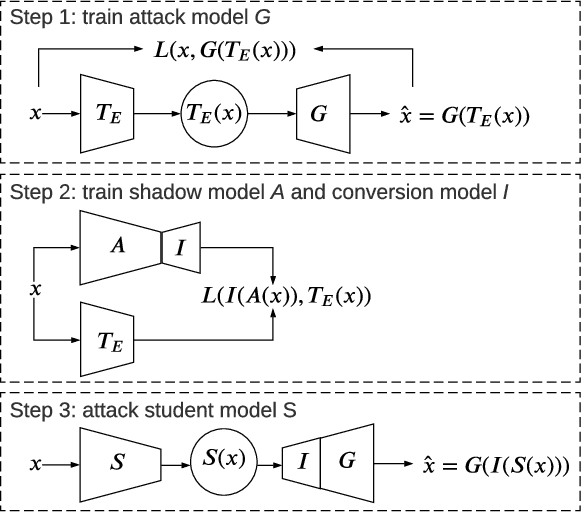
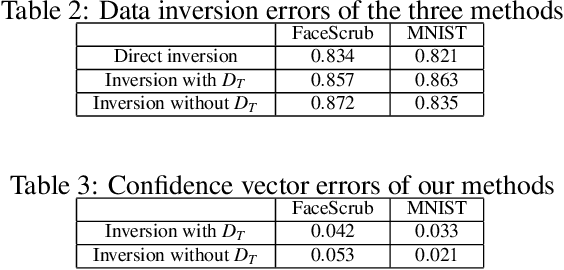
Transfer learning is an important approach that produces pre-trained teacher models which can be used to quickly build specialized student models. However, recent research on transfer learning has found that it is vulnerable to various attacks, e.g., misclassification and backdoor attacks. However, it is still not clear whether transfer learning is vulnerable to model inversion attacks. Launching a model inversion attack against transfer learning scheme is challenging. Not only does the student model hide its structural parameters, but it is also inaccessible to the adversary. Hence, when targeting a student model, both the white-box and black-box versions of existing model inversion attacks fail. White-box attacks fail as they need the target model's parameters. Black-box attacks fail as they depend on making repeated queries of the target model. However, they may not mean that transfer learning models are impervious to model inversion attacks. Hence, with this paper, we initiate research into model inversion attacks against transfer learning schemes with two novel attack methods. Both are black-box attacks, suiting different situations, that do not rely on queries to the target student model. In the first method, the adversary has the data samples that share the same distribution as the training set of the teacher model. In the second method, the adversary does not have any such samples. Experiments show that highly recognizable data records can be recovered with both of these methods. This means that even if a model is an inaccessible black-box, it can still be inverted.