 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Reliable Diffusion Models via Subspace Projection
Mar 21, 2025


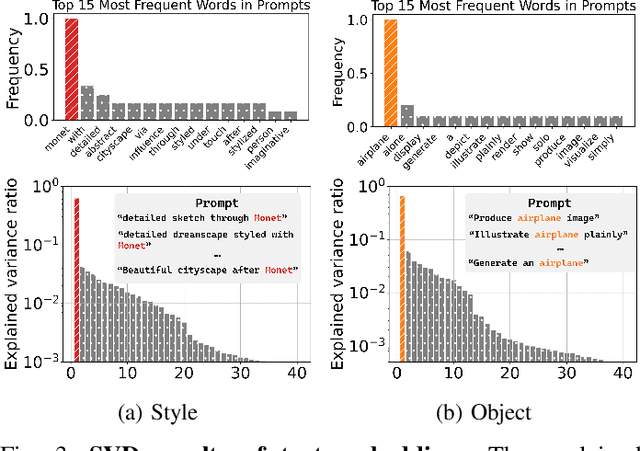
Large-scale text-to-image (T2I) diffusion models have revolutionized image generation, enabling the synthesis of highly detailed visuals from textual descriptions. However, these models may inadvertently generate inappropriate content, such as copyrighted works or offensive images. While existing methods attempt to eliminate specific unwanted concepts, they often fail to ensure complete removal, allowing the concept to reappear in subtle forms. For instance, a model may successfully avoid generating images in Van Gogh's style when explicitly prompted with 'Van Gogh', yet still reproduce his signature artwork when given the prompt 'Starry Night'. In this paper, we propose SAFER, a novel and efficient approach for thoroughly removing target concepts from diffusion models. At a high level, SAFER is inspired by the observed low-dimensional structure of the text embedding space. The method first identifies a concept-specific subspace $S_c$ associated with the target concept c. It then projects the prompt embeddings onto the complementary subspace of $S_c$, effectively erasing the concept from the generated images. Since concepts can be abstract and difficult to fully capture using natural language alone, we employ textual inversion to learn an optimized embedding of the target concept from a reference image. This enables more precise subspace estimation and enhances removal performance. Furthermore, we introduce a subspace expansion strategy to ensure comprehensive and robust concept erasure. Extensive experiments demonstrate that SAFER consistently and effectively erases unwanted concepts from diffusion models while preserving generation quality.
AFed: Algorithmic Fair Federated Learning
Jan 06, 2025



Federated Learning (FL) has gained significant attention as it facilitates collaborative machine learning among multiple clients without centralizing their data on a server. FL ensures the privacy of participating clients by locally storing their data, which creates new challenges in fairness. Traditional debiasing methods assume centralized access to sensitive information, rendering them impractical for the FL setting. Additionally, FL is more susceptible to fairness issues than centralized machine learning due to the diverse client data sources that may be associated with group information. Therefore, training a fair model in FL without access to client local data is important and challenging. This paper presents AFed, a straightforward yet effective framework for promoting group fairness in FL. The core idea is to circumvent restricted data access by learning the global data distribution. This paper proposes two approaches: AFed-G, which uses a conditional generator trained on the server side, and AFed-GAN, which improves upon AFed-G by training a conditional GAN on the client side. We augment the client data with the generated samples to help remove bias. Our theoretical analysis justifies the proposed methods, and empirical results on multiple real-world datasets demonstrate a substantial improvement in AFed over several baselines.
MM-WLAuslan: Multi-View Multi-Modal Word-Level Australian Sign Language Recognition Dataset
Oct 25, 2024



Isolated Sign Language Recognition (ISLR) focuses on identifying individual sign language glosses. Considering the diversity of sign languages across geographical regions, developing region-specific ISLR datasets is crucial for supporting communication and research. Auslan, as a sign language specific to Australia, still lacks a dedicated large-scale word-level dataset for the ISLR task. To fill this gap, we curate \underline{\textbf{the first}} large-scale Multi-view Multi-modal Word-Level Australian Sign Language recognition dataset, dubbed MM-WLAuslan. Compared to other publicly available datasets, MM-WLAuslan exhibits three significant advantages: (1) the largest amount of data, (2) the most extensive vocabulary, and (3) the most diverse of multi-modal camera views. Specifically, we record 282K+ sign videos covering 3,215 commonly used Auslan glosses presented by 73 signers in a studio environment. Moreover, our filming system includes two different types of cameras, i.e., three Kinect-V2 cameras and a RealSense camera. We position cameras hemispherically around the front half of the model and simultaneously record videos using all four cameras. Furthermore, we benchmark results with state-of-the-art methods for various multi-modal ISLR settings on MM-WLAuslan, including multi-view, cross-camera, and cross-view. Experiment results indicate that MM-WLAuslan is a challenging ISLR dataset, and we hope this dataset will contribute to the development of Auslan and the advancement of sign languages worldwide. All datasets and benchmarks are available at MM-WLAuslan.
Machine Unlearning via Null Space Calibration
Apr 21, 2024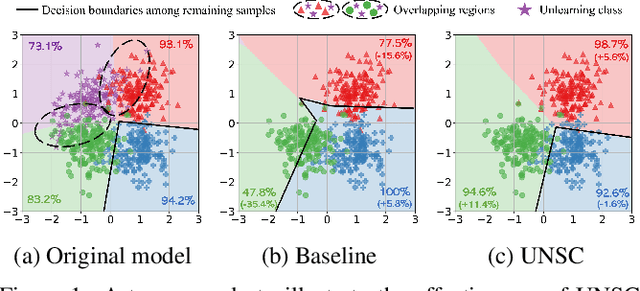

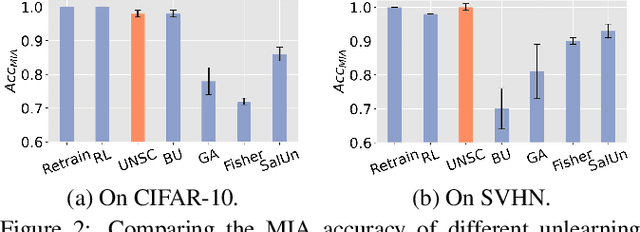

Machine unlearning aims to enable models to forget specific data instances when receiving deletion requests. Current research centres on efficient unlearning to erase the influence of data from the model and neglects the subsequent impacts on the remaining data. Consequently, existing unlearning algorithms degrade the model's performance after unlearning, known as \textit{over-unlearning}. This paper addresses this critical yet under-explored issue by introducing machine \underline{U}nlearning via \underline{N}ull \underline{S}pace \underline{C}alibration (UNSC), which can accurately unlearn target samples without over-unlearning. On the contrary, by calibrating the decision space during unlearning, UNSC can significantly improve the model's performance on the remaining samples. In particular, our approach hinges on confining the unlearning process to a specified null space tailored to the remaining samples, which is augmented by strategically pseudo-labeling the unlearning samples. Comparative analyses against several established baselines affirm the superiority of our approach. Code is released at this \href{https://github.com/HQC-ML/Machine-Unlearning-via-Null-Space-Calibration}{URL}.
Divide and Ensemble: Progressively Learning for the Unknown
Oct 09, 2023
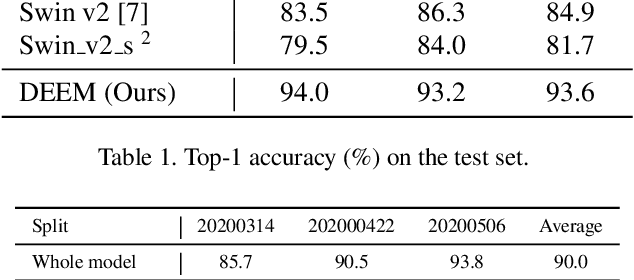


In the wheat nutrient deficiencies classification challenge, we present the DividE and EnseMble (DEEM) method for progressive test data predictions. We find that (1) test images are provided in the challenge; (2) samples are equipped with their collection dates; (3) the samples of different dates show notable discrepancies. Based on the findings, we partition the dataset into discrete groups by the dates and train models on each divided group. We then adopt the pseudo-labeling approach to label the test data and incorporate those with high confidence into the training set. In pseudo-labeling, we leverage models ensemble with different architectures to enhance the reliability of predictions. The pseudo-labeling and ensembled model training are iteratively conducted until all test samples are labeled. Finally, the separated models for each group are unified to obtain the model for the whole dataset. Our method achieves an average of 93.6\% Top-1 test accuracy~(94.0\% on WW2020 and 93.2\% on WR2021) and wins the 1$st$ place in the Deep Nutrient Deficiency Challenge~\footnote{https://cvppa2023.github.io/challenges/}.
Privacy and Fairness in Federated Learning: on the Perspective of Trade-off
Jun 25, 2023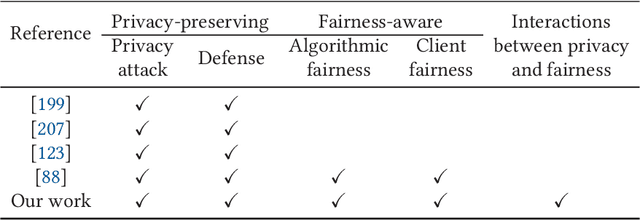

Federated learning (FL) has been a hot topic in recent years. Ever since it was introduced, researchers have endeavored to devise FL systems that protect privacy or ensure fair results, with most research focusing on one or the other. As two crucial ethical notions, the interactions between privacy and fairness are comparatively less studied. However, since privacy and fairness compete, considering each in isolation will inevitably come at the cost of the other. To provide a broad view of these two critical topics, we presented a detailed literature review of privacy and fairness issues, highlighting unique challenges posed by FL and solutions in federated settings. We further systematically surveyed different interactions between privacy and fairness, trying to reveal how privacy and fairness could affect each other and point out new research directions in fair and private FL.
Model Inversion Attack against Transfer Learning: Inverting a Model without Accessing It
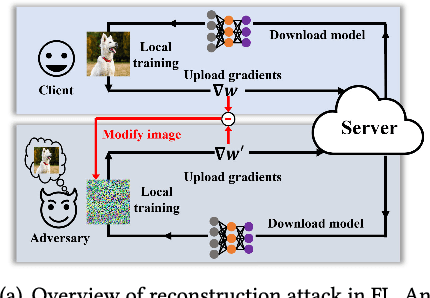
Mar 13, 2022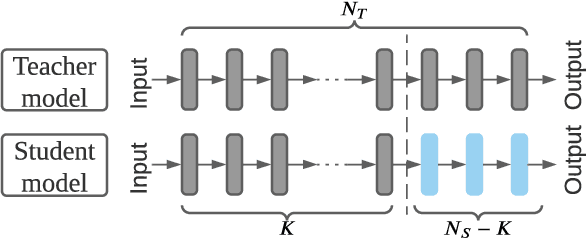

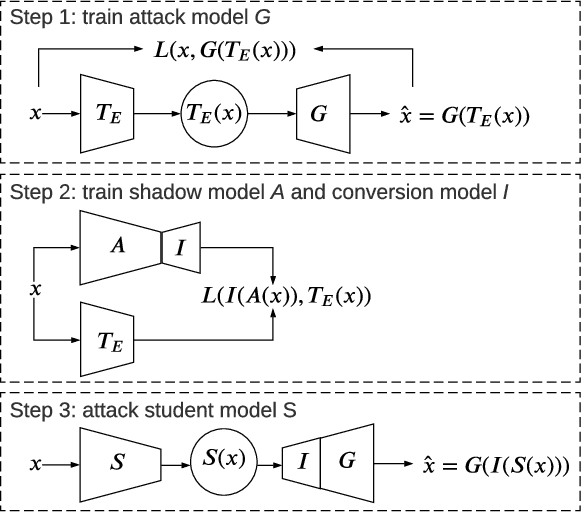
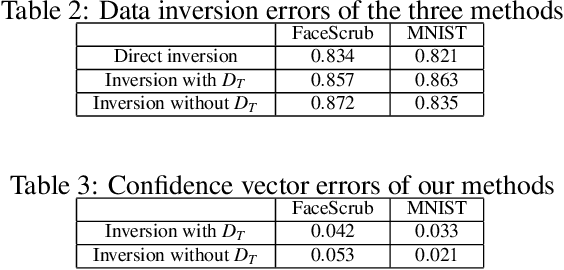
Transfer learning is an important approach that produces pre-trained teacher models which can be used to quickly build specialized student models. However, recent research on transfer learning has found that it is vulnerable to various attacks, e.g., misclassification and backdoor attacks. However, it is still not clear whether transfer learning is vulnerable to model inversion attacks. Launching a model inversion attack against transfer learning scheme is challenging. Not only does the student model hide its structural parameters, but it is also inaccessible to the adversary. Hence, when targeting a student model, both the white-box and black-box versions of existing model inversion attacks fail. White-box attacks fail as they need the target model's parameters. Black-box attacks fail as they depend on making repeated queries of the target model. However, they may not mean that transfer learning models are impervious to model inversion attacks. Hence, with this paper, we initiate research into model inversion attacks against transfer learning schemes with two novel attack methods. Both are black-box attacks, suiting different situations, that do not rely on queries to the target student model. In the first method, the adversary has the data samples that share the same distribution as the training set of the teacher model. In the second method, the adversary does not have any such samples. Experiments show that highly recognizable data records can be recovered with both of these methods. This means that even if a model is an inaccessible black-box, it can still be inverted.