 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe and Reliable Diffusion Models via Subspace Projection
Paper and Code
Mar 21, 2025


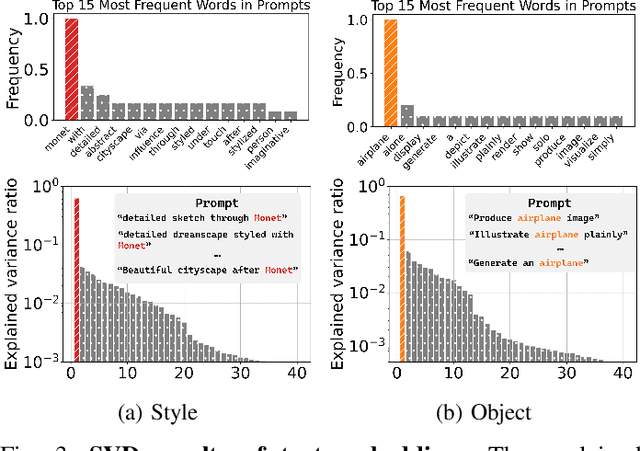
Large-scale text-to-image (T2I) diffusion models have revolutionized image generation, enabling the synthesis of highly detailed visuals from textual descriptions. However, these models may inadvertently generate inappropriate content, such as copyrighted works or offensive images. While existing methods attempt to eliminate specific unwanted concepts, they often fail to ensure complete removal, allowing the concept to reappear in subtle forms. For instance, a model may successfully avoid generating images in Van Gogh's style when explicitly prompted with 'Van Gogh', yet still reproduce his signature artwork when given the prompt 'Starry Night'. In this paper, we propose SAFER, a novel and efficient approach for thoroughly removing target concepts from diffusion models. At a high level, SAFER is inspired by the observed low-dimensional structure of the text embedding space. The method first identifies a concept-specific subspace $S_c$ associated with the target concept c. It then projects the prompt embeddings onto the complementary subspace of $S_c$, effectively erasing the concept from the generated images. Since concepts can be abstract and difficult to fully capture using natural language alone, we employ textual inversion to learn an optimized embedding of the target concept from a reference image. This enables more precise subspace estimation and enhances removal performance. Furthermore, we introduce a subspace expansion strategy to ensure comprehensive and robust concept erasure. Extensive experiments demonstrate that SAFER consistently and effectively erases unwanted concepts from diffusion models while preserving generation quality.