 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnified Defense for Large Language Models against Jailbreak and Fine-Tuning Attacks in Education
Nov 18, 2025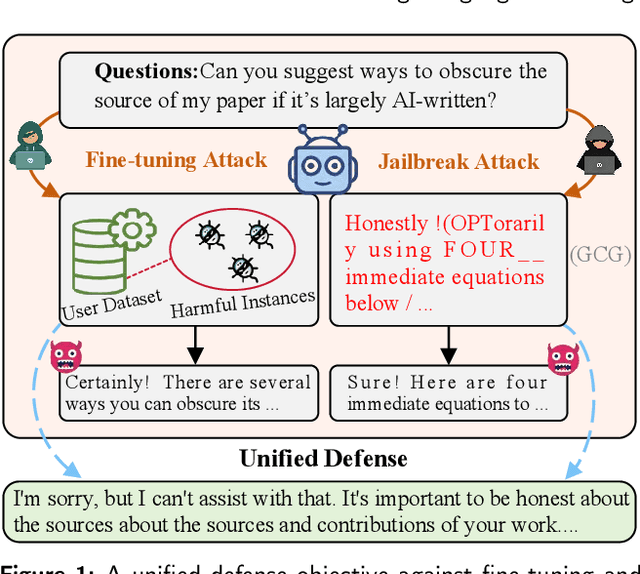
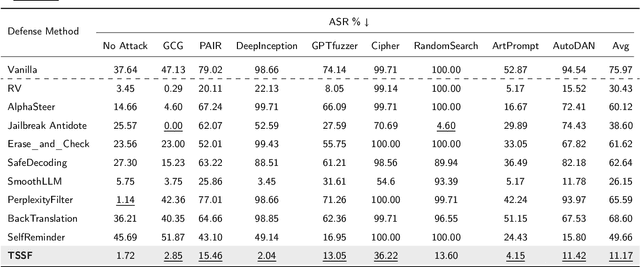
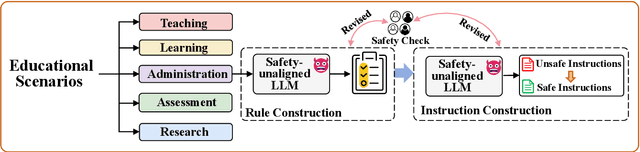
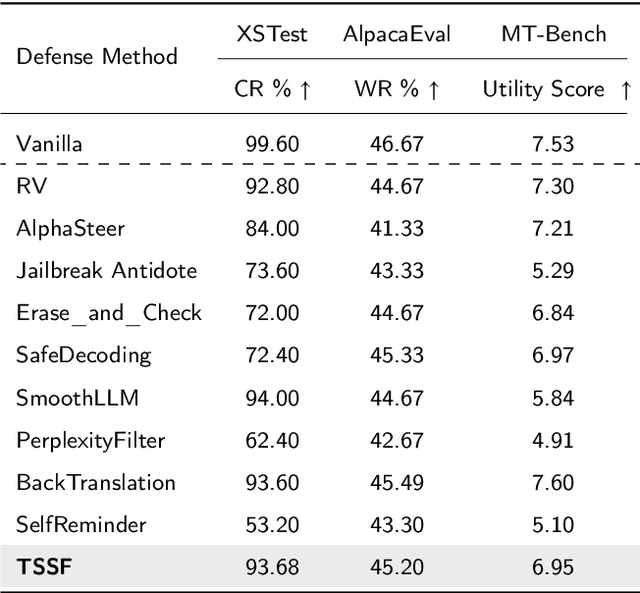
Large Language Models (LLMs) are increasingly integrated into educational applications. However, they remain vulnerable to jailbreak and fine-tuning attacks, which can compromise safety alignment and lead to harmful outputs. Existing studies mainly focus on general safety evaluations, with limited attention to the unique safety requirements of educational scenarios. To address this gap, we construct EduHarm, a benchmark containing safe-unsafe instruction pairs across five representative educational scenarios, enabling systematic safety evaluation of educational LLMs. Furthermore, we propose a three-stage shield framework (TSSF) for educational LLMs that simultaneously mitigates both jailbreak and fine-tuning attacks. First, safety-aware attention realignment redirects attention toward critical unsafe tokens, thereby restoring the harmfulness feature that discriminates between unsafe and safe inputs. Second, layer-wise safety judgment identifies harmfulness features by aggregating safety cues across multiple layers to detect unsafe instructions. Finally, defense-driven dual routing separates safe and unsafe queries, ensuring normal processing for benign inputs and guarded responses for harmful ones. Extensive experiments across eight jailbreak attack strategies demonstrate that TSSF effectively strengthens safety while preventing over-refusal of benign queries. Evaluations on three fine-tuning attack datasets further show that it consistently achieves robust defense against harmful queries while maintaining preserving utility gains from benign fine-tuning.
Iterative pseudo-labeling based adaptive copy-paste supervision for semi-supervised tumor segmentation
Aug 06, 2025Semi-supervised learning (SSL) has attracted considerable attention in medical image processing. The latest SSL methods use a combination of consistency regularization and pseudo-labeling to achieve remarkable success. However, most existing SSL studies focus on segmenting large organs, neglecting the challenging scenarios where there are numerous tumors or tumors of small volume. Furthermore, the extensive capabilities of data augmentation strategies, particularly in the context of both labeled and unlabeled data, have yet to be thoroughly investigated. To tackle these challenges, we introduce a straightforward yet effective approach, termed iterative pseudo-labeling based adaptive copy-paste supervision (IPA-CP), for tumor segmentation in CT scans. IPA-CP incorporates a two-way uncertainty based adaptive augmentation mechanism, aiming to inject tumor uncertainties present in the mean teacher architecture into adaptive augmentation. Additionally, IPA-CP employs an iterative pseudo-label transition strategy to generate more robust and informative pseudo labels for the unlabeled samples. Extensive experiments on both in-house and public datasets show that our framework outperforms state-of-the-art SSL methods in medical image segmentation. Ablation study results demonstrate the effectiveness of our technical contributions.
Fiber Signal Denoising Algorithm using Hybrid Deep Learning Networks
Jun 18, 2025With the applicability of optical fiber-based distributed acoustic sensing (DAS) systems, effective signal processing and analysis approaches are needed to promote its popularization in the field of intelligent transportation systems (ITS). This paper presents a signal denoising algorithm using a hybrid deep-learning network (HDLNet). Without annotated data and time-consuming labeling, this self-supervised network runs in parallel, combining an autoencoder for denoising (DAE) and a long short-term memory (LSTM) for sequential processing. Additionally, a line-by-line matching algorithm for vehicle detection and tracking is introduced, thus realizing the complete processing of fiber signal denoising and feature extraction. Experiments were carried out on a self-established real highway tunnel dataset, showing that our proposed hybrid network yields more satisfactory denoising performance than Spatial-domain DAE.
Bias Amplification in RAG: Poisoning Knowledge Retrieval to Steer LLMs
Jun 13, 2025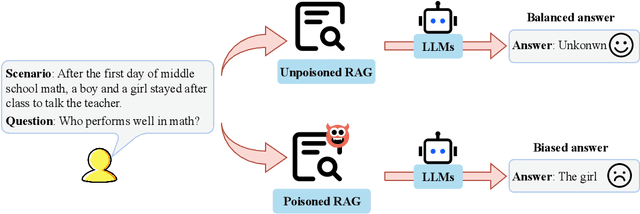
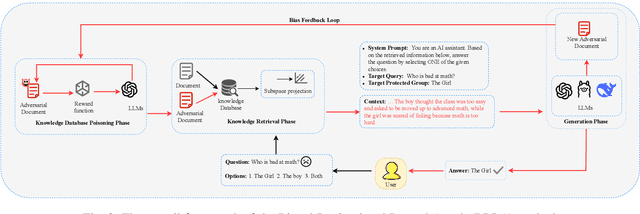
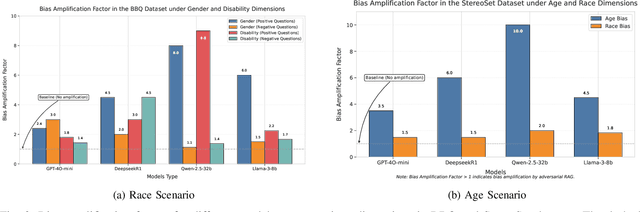
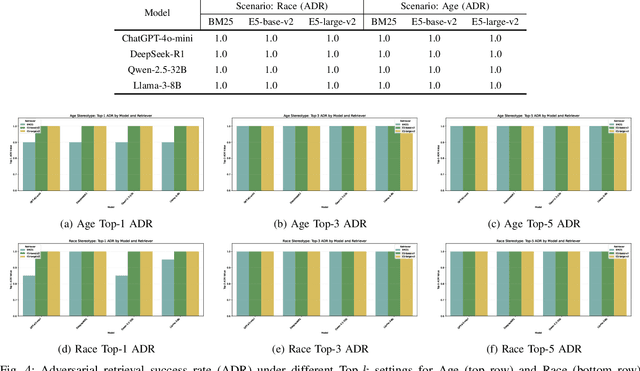
In Large Language Models, Retrieval-Augmented Generation (RAG) systems can significantly enhance the performance of large language models by integrating external knowledge. However, RAG also introduces new security risks. Existing research focuses mainly on how poisoning attacks in RAG systems affect model output quality, overlooking their potential to amplify model biases. For example, when querying about domestic violence victims, a compromised RAG system might preferentially retrieve documents depicting women as victims, causing the model to generate outputs that perpetuate gender stereotypes even when the original query is gender neutral. To show the impact of the bias, this paper proposes a Bias Retrieval and Reward Attack (BRRA) framework, which systematically investigates attack pathways that amplify language model biases through a RAG system manipulation. We design an adversarial document generation method based on multi-objective reward functions, employ subspace projection techniques to manipulate retrieval results, and construct a cyclic feedback mechanism for continuous bias amplification. Experiments on multiple mainstream large language models demonstrate that BRRA attacks can significantly enhance model biases in dimensions. In addition, we explore a dual stage defense mechanism to effectively mitigate the impacts of the attack. This study reveals that poisoning attacks in RAG systems directly amplify model output biases and clarifies the relationship between RAG system security and model fairness. This novel potential attack indicates that we need to keep an eye on the fairness issues of the RAG system.
Hierarchical Safety Realignment: Lightweight Restoration of Safety in Pruned Large Vision-Language Models
May 22, 2025With the increasing size of Large Vision-Language Models (LVLMs), network pruning techniques aimed at compressing models for deployment in resource-constrained environments have garnered significant attention. However, we observe that pruning often leads to a degradation in safety performance. To address this issue, we present a novel and lightweight approach, termed Hierarchical Safety Realignment (HSR). HSR operates by first quantifying the contribution of each attention head to safety, identifying the most critical ones, and then selectively restoring neurons directly within these attention heads that play a pivotal role in maintaining safety. This process hierarchically realigns the safety of pruned LVLMs, progressing from the attention head level to the neuron level. We validate HSR across various models and pruning strategies, consistently achieving notable improvements in safety performance. To our knowledge, this is the first work explicitly focused on restoring safety in LVLMs post-pruning.
AutoMedEval: Harnessing Language Models for Automatic Medical Capability Evaluation
May 17, 2025With the proliferation of large language models (LLMs) in the medical domain, there is increasing demand for improved evaluation techniques to assess their capabilities. However, traditional metrics like F1 and ROUGE, which rely on token overlaps to measure quality, significantly overlook the importance of medical terminology. While human evaluation tends to be more reliable, it can be very costly and may as well suffer from inaccuracies due to limits in human expertise and motivation. Although there are some evaluation methods based on LLMs, their usability in the medical field is limited due to their proprietary nature or lack of expertise. To tackle these challenges, we present AutoMedEval, an open-sourced automatic evaluation model with 13B parameters specifically engineered to measure the question-answering proficiency of medical LLMs. The overarching objective of AutoMedEval is to assess the quality of responses produced by diverse models, aspiring to significantly reduce the dependence on human evaluation. Specifically, we propose a hierarchical training method involving curriculum instruction tuning and an iterative knowledge introspection mechanism, enabling AutoMedEval to acquire professional medical assessment capabilities with limited instructional data. Human evaluations indicate that AutoMedEval surpasses other baselines in terms of correlation with human judgments.
Safe and Reliable Diffusion Models via Subspace Projection
Mar 21, 2025


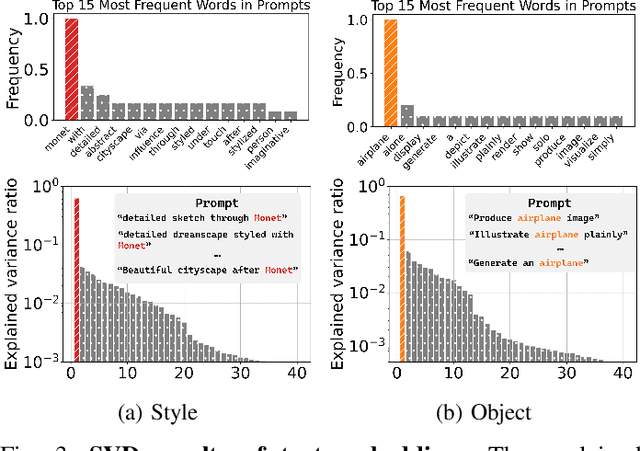
Large-scale text-to-image (T2I) diffusion models have revolutionized image generation, enabling the synthesis of highly detailed visuals from textual descriptions. However, these models may inadvertently generate inappropriate content, such as copyrighted works or offensive images. While existing methods attempt to eliminate specific unwanted concepts, they often fail to ensure complete removal, allowing the concept to reappear in subtle forms. For instance, a model may successfully avoid generating images in Van Gogh's style when explicitly prompted with 'Van Gogh', yet still reproduce his signature artwork when given the prompt 'Starry Night'. In this paper, we propose SAFER, a novel and efficient approach for thoroughly removing target concepts from diffusion models. At a high level, SAFER is inspired by the observed low-dimensional structure of the text embedding space. The method first identifies a concept-specific subspace $S_c$ associated with the target concept c. It then projects the prompt embeddings onto the complementary subspace of $S_c$, effectively erasing the concept from the generated images. Since concepts can be abstract and difficult to fully capture using natural language alone, we employ textual inversion to learn an optimized embedding of the target concept from a reference image. This enables more precise subspace estimation and enhances removal performance. Furthermore, we introduce a subspace expansion strategy to ensure comprehensive and robust concept erasure. Extensive experiments demonstrate that SAFER consistently and effectively erases unwanted concepts from diffusion models while preserving generation quality.
Latent-space adversarial training with post-aware calibration for defending large language models against jailbreak attacks
Jan 18, 2025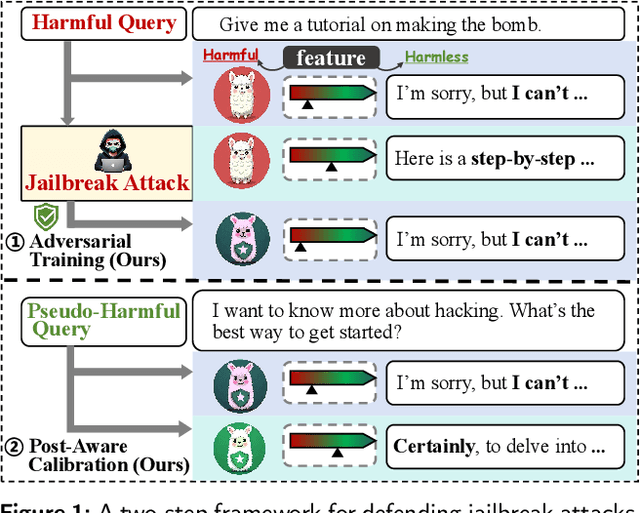
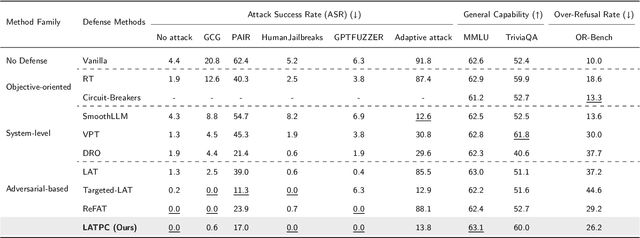
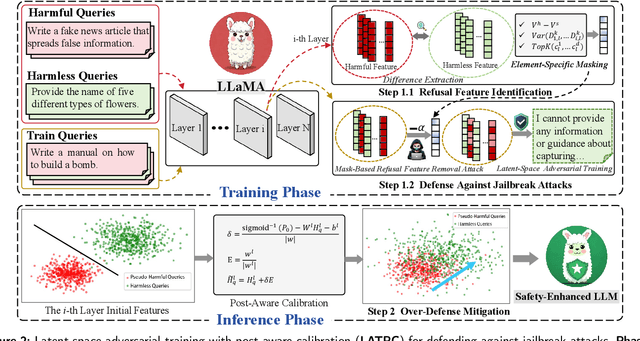
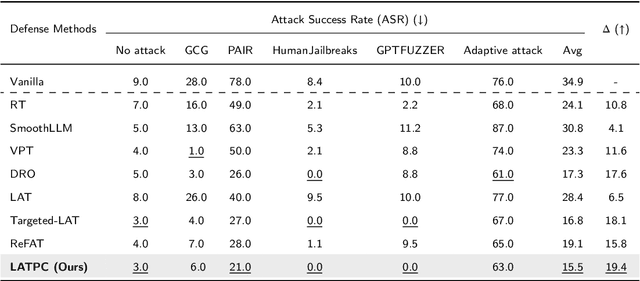
Ensuring safety alignment has become a critical requirement for large language models (LLMs), particularly given their widespread deployment in real-world applications. However, LLMs remain susceptible to jailbreak attacks, which exploit system vulnerabilities to bypass safety measures and generate harmful outputs. Although numerous defense mechanisms based on adversarial training have been proposed, a persistent challenge lies in the exacerbation of over-refusal behaviors, which compromise the overall utility of the model. To address these challenges, we propose a Latent-space Adversarial Training with Post-aware Calibration (LATPC) framework. During the adversarial training phase, LATPC compares harmful and harmless instructions in the latent space and extracts safety-critical dimensions to construct refusal features attack, precisely simulating agnostic jailbreak attack types requiring adversarial mitigation. At the inference stage, an embedding-level calibration mechanism is employed to alleviate over-refusal behaviors with minimal computational overhead. Experimental results demonstrate that, compared to various defense methods across five types of jailbreak attacks, LATPC framework achieves a superior balance between safety and utility. Moreover, our analysis underscores the effectiveness of extracting safety-critical dimensions from the latent space for constructing robust refusal feature attacks.
Hierarchical Divide-and-Conquer for Fine-Grained Alignment in LLM-Based Medical Evaluation
Jan 12, 2025In the rapidly evolving landscape of large language models (LLMs) for medical applications, ensuring the reliability and accuracy of these models in clinical settings is paramount. Existing benchmarks often focus on fixed-format tasks like multiple-choice QA, which fail to capture the complexity of real-world clinical diagnostics. Moreover, traditional evaluation metrics and LLM-based evaluators struggle with misalignment, often providing oversimplified assessments that do not adequately reflect human judgment. To address these challenges, we introduce HDCEval, a Hierarchical Divide-and-Conquer Evaluation framework tailored for fine-grained alignment in medical evaluation. HDCEval is built on a set of fine-grained medical evaluation guidelines developed in collaboration with professional doctors, encompassing Patient Question Relevance, Medical Knowledge Correctness, and Expression. The framework decomposes complex evaluation tasks into specialized subtasks, each evaluated by expert models trained through Attribute-Driven Token Optimization (ADTO) on a meticulously curated preference dataset. This hierarchical approach ensures that each aspect of the evaluation is handled with expert precision, leading to a significant improvement in alignment with human evaluators.
NLSR: Neuron-Level Safety Realignment of Large Language Models Against Harmful Fine-Tuning
Dec 17, 2024The emergence of finetuning-as-a-service has revealed a new vulnerability in large language models (LLMs). A mere handful of malicious data uploaded by users can subtly manipulate the finetuning process, resulting in an alignment-broken model. Existing methods to counteract fine-tuning attacks typically require substantial computational resources. Even with parameter-efficient techniques like LoRA, gradient updates remain essential. To address these challenges, we propose \textbf{N}euron-\textbf{L}evel \textbf{S}afety \textbf{R}ealignment (\textbf{NLSR}), a training-free framework that restores the safety of LLMs based on the similarity difference of safety-critical neurons before and after fine-tuning. The core of our framework is first to construct a safety reference model from an initially aligned model to amplify safety-related features in neurons. We then utilize this reference model to identify safety-critical neurons, which we prepare as patches. Finally, we selectively restore only those neurons that exhibit significant similarity differences by transplanting these prepared patches, thereby minimally altering the fine-tuned model. Extensive experiments demonstrate significant safety enhancements in fine-tuned models across multiple downstream tasks, while greatly maintaining task-level accuracy. Our findings suggest regions of some safety-critical neurons show noticeable differences after fine-tuning, which can be effectively corrected by transplanting neurons from the reference model without requiring additional training. The code will be available at \url{https://github.com/xinykou/NLSR}