 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Collaboration in Heterogeneous LLM-Based Multi-Agent Systems via Entropy-Based Understanding Assessment and Experience Retrieval
Feb 14, 2026With recent breakthroughs in large language models (LLMs) for reasoning, planning, and complex task generation, artificial intelligence systems are transitioning from isolated single-agent architectures to multi-agent systems with collaborative intelligence. However, in heterogeneous multi-agent systems (HMAS), capability differences among agents give rise to consistent cognitive problems, where strong and weak models fail to contribute effectively. We define the collaboration as a strong-weak system. Through comprehensive experiments, we disclose a counterintuitive phenomenon in the strong-weak system: a strong-weak collaboration may under-perform weak-weak combinations, revealing that cognitive mismatching are key bottlenecks limiting heterogeneous cooperation. To overcome these challenges, we propose an Entropy-Based Adaptive Guidance Framework that dynamically aligns the guidance with the cognitive state of each agent. The framework quantifies the understanding of weak agents through multi-dimensional entropy metrics - covering expression, uncertainty, structure, coherence, and relevance - and adaptively adjusts the intensity of the guidance at light, moderate and intensive levels. Furthermore, a Retrieval-Augmented Generation (RAG) mechanism is incorporated to retain successful collaboration experiences, enabling both immediate adaptation and long-term learning. Extensive experiments on three benchmark datasets, GSM8K, MBPP, and CVRP demonstrate that our approach consistently enhances the effectiveness and stability of heterogeneous collaboration. The results highlight that adaptive guidance not only mitigates cognitive imbalance but also establishes a scalable pathway toward more robust, cooperative multi-agent intelligence.
Bias Amplification in RAG: Poisoning Knowledge Retrieval to Steer LLMs
Jun 13, 2025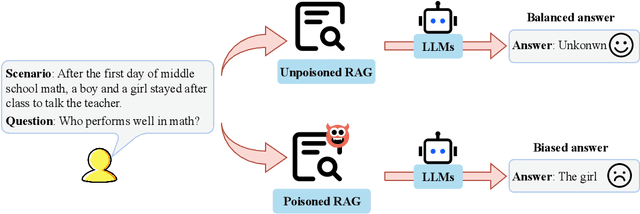
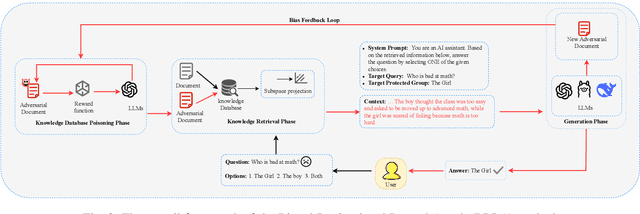
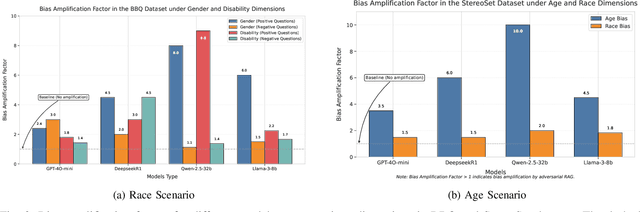
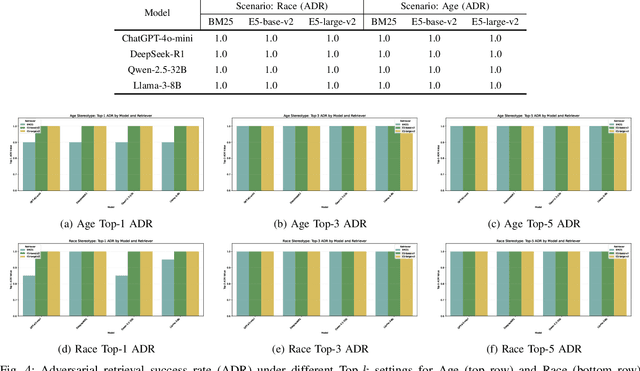
In Large Language Models, Retrieval-Augmented Generation (RAG) systems can significantly enhance the performance of large language models by integrating external knowledge. However, RAG also introduces new security risks. Existing research focuses mainly on how poisoning attacks in RAG systems affect model output quality, overlooking their potential to amplify model biases. For example, when querying about domestic violence victims, a compromised RAG system might preferentially retrieve documents depicting women as victims, causing the model to generate outputs that perpetuate gender stereotypes even when the original query is gender neutral. To show the impact of the bias, this paper proposes a Bias Retrieval and Reward Attack (BRRA) framework, which systematically investigates attack pathways that amplify language model biases through a RAG system manipulation. We design an adversarial document generation method based on multi-objective reward functions, employ subspace projection techniques to manipulate retrieval results, and construct a cyclic feedback mechanism for continuous bias amplification. Experiments on multiple mainstream large language models demonstrate that BRRA attacks can significantly enhance model biases in dimensions. In addition, we explore a dual stage defense mechanism to effectively mitigate the impacts of the attack. This study reveals that poisoning attacks in RAG systems directly amplify model output biases and clarifies the relationship between RAG system security and model fairness. This novel potential attack indicates that we need to keep an eye on the fairness issues of the RAG system.
Machine Unlearning on Pre-trained Models by Residual Feature Alignment Using LoRA
Nov 13, 2024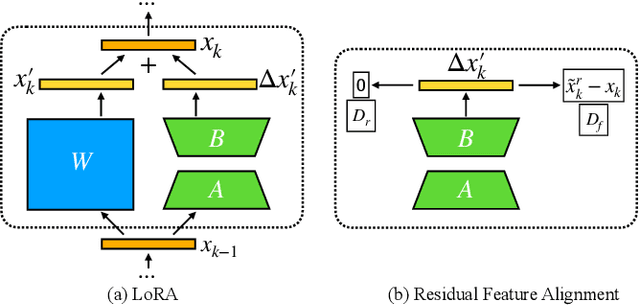
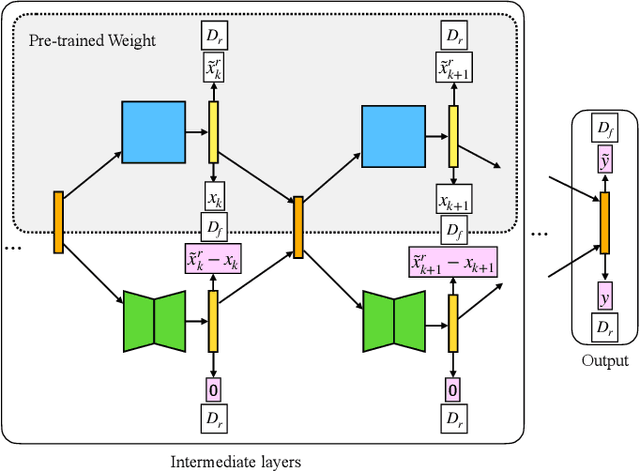
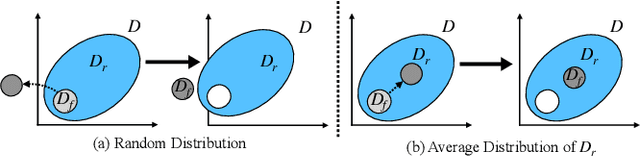
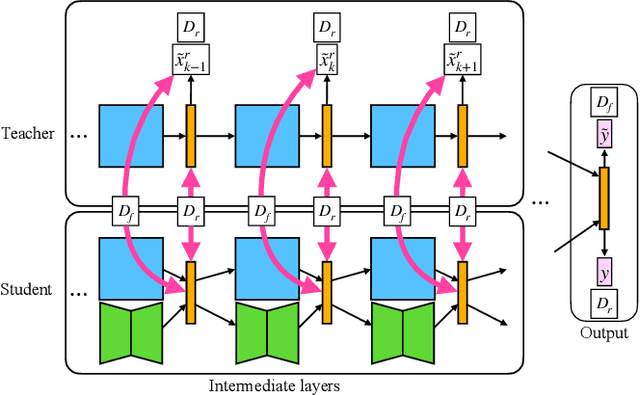
Machine unlearning is new emerged technology that removes a subset of the training data from a trained model without affecting the model performance on the remaining data. This topic is becoming increasingly important in protecting user privacy and eliminating harmful or outdated data. The key challenge lies in effectively and efficiently unlearning specific information without compromising the model's utility on the retained data. For the pre-trained models, fine-tuning is an important way to achieve the unlearning target. Previous work typically fine-tuned the entire model's parameters, which incurs significant computation costs. In addition, the fine-tuning process may cause shifts in the intermediate layer features, affecting the model's overall utility. In this work, we propose a novel and efficient machine unlearning method on pre-trained models. We term the method as Residual Feature Alignment Unlearning. Specifically, we leverage LoRA (Low-Rank Adaptation) to decompose the model's intermediate features into pre-trained features and residual features. By adjusting the residual features, we align the unlearned model with the pre-trained model at the intermediate feature level to achieve both unlearning and remaining targets. The method aims to learn the zero residuals on the retained set and shifted residuals on the unlearning set. Extensive experiments on numerous datasets validate the effectiveness of our approach.
Knowledge Distillation in Federated Learning: a Survey on Long Lasting Challenges and New Solutions
Jun 16, 2024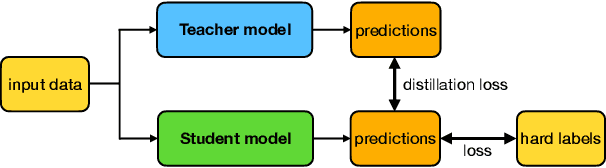

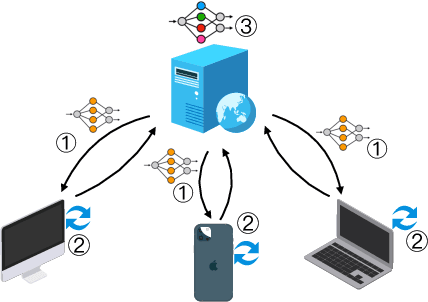
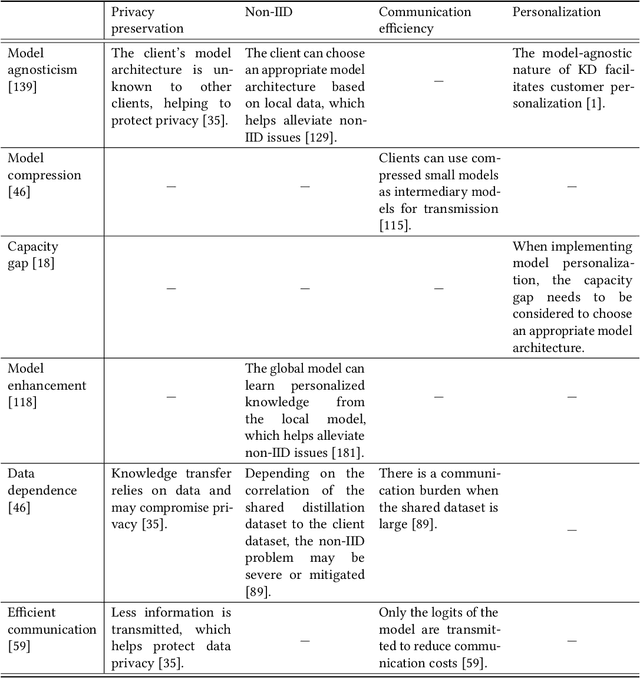
Federated Learning (FL) is a distributed and privacy-preserving machine learning paradigm that coordinates multiple clients to train a model while keeping the raw data localized. However, this traditional FL poses some challenges, including privacy risks, data heterogeneity, communication bottlenecks, and system heterogeneity issues. To tackle these challenges, knowledge distillation (KD) has been widely applied in FL since 2020. KD is a validated and efficacious model compression and enhancement algorithm. The core concept of KD involves facilitating knowledge transfer between models by exchanging logits at intermediate or output layers. These properties make KD an excellent solution for the long-lasting challenges in FL. Up to now, there have been few reviews that summarize and analyze the current trend and methods for how KD can be applied in FL efficiently. This article aims to provide a comprehensive survey of KD-based FL, focusing on addressing the above challenges. First, we provide an overview of KD-based FL, including its motivation, basics, taxonomy, and a comparison with traditional FL and where KD should execute. We also analyze the critical factors in KD-based FL in the appendix, including teachers, knowledge, data, and methods. We discuss how KD can address the challenges in FL, including privacy protection, data heterogeneity, communication efficiency, and personalization. Finally, we discuss the challenges facing KD-based FL algorithms and future research directions. We hope this survey can provide insights and guidance for researchers and practitioners in the FL area.