 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation in Federated Learning: a Survey on Long Lasting Challenges and New Solutions
Paper and Code
Jun 16, 2024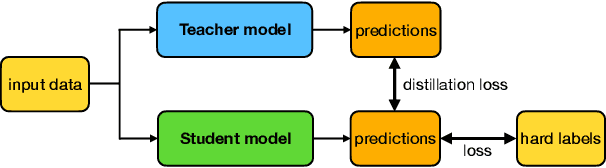

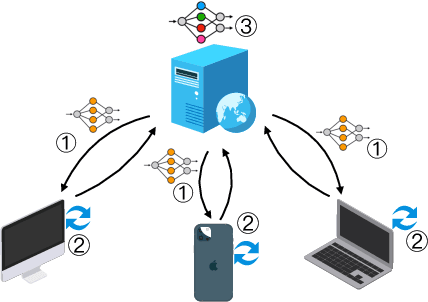
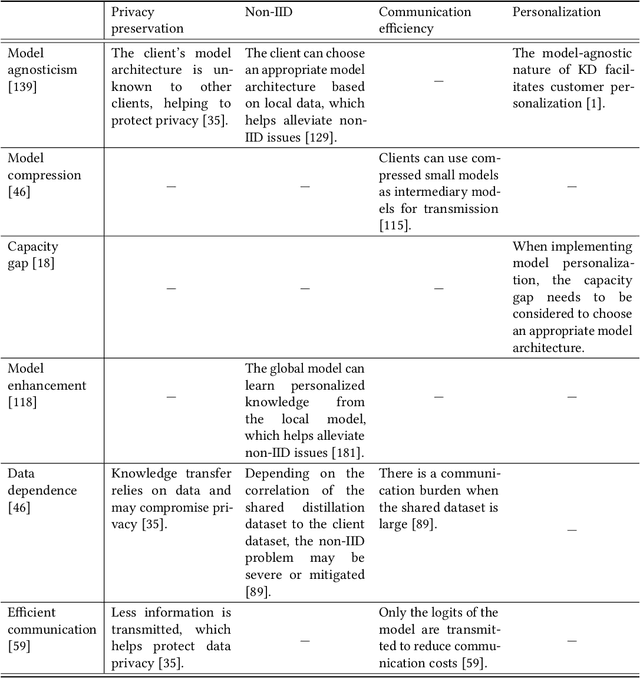
Federated Learning (FL) is a distributed and privacy-preserving machine learning paradigm that coordinates multiple clients to train a model while keeping the raw data localized. However, this traditional FL poses some challenges, including privacy risks, data heterogeneity, communication bottlenecks, and system heterogeneity issues. To tackle these challenges, knowledge distillation (KD) has been widely applied in FL since 2020. KD is a validated and efficacious model compression and enhancement algorithm. The core concept of KD involves facilitating knowledge transfer between models by exchanging logits at intermediate or output layers. These properties make KD an excellent solution for the long-lasting challenges in FL. Up to now, there have been few reviews that summarize and analyze the current trend and methods for how KD can be applied in FL efficiently. This article aims to provide a comprehensive survey of KD-based FL, focusing on addressing the above challenges. First, we provide an overview of KD-based FL, including its motivation, basics, taxonomy, and a comparison with traditional FL and where KD should execute. We also analyze the critical factors in KD-based FL in the appendix, including teachers, knowledge, data, and methods. We discuss how KD can address the challenges in FL, including privacy protection, data heterogeneity, communication efficiency, and personalization. Finally, we discuss the challenges facing KD-based FL algorithms and future research directions. We hope this survey can provide insights and guidance for researchers and practitioners in the FL area.